
PyTorch下的可视化工具
来源:知乎—锦恢
01
import torchimport torch.nn as nnclass ConvNet(nn.Module):def __init__(self):super(ConvNet, self).__init__()self.conv1 = nn.Sequential(nn.Conv2d(1, 16, 3, 1, 1),nn.ReLU(),nn.AvgPool2d(2, 2))self.conv2 = nn.Sequential(nn.Conv2d(16, 32, 3, 1, 1),nn.ReLU(),nn.MaxPool2d(2, 2))self.fc = nn.Sequential(nn.Linear(32 * 7 * 7, 128),nn.ReLU(),nn.Linear(128, 64),nn.ReLU())self.out = nn.Linear(64, 10)def forward(self, x):x = self.conv1(x)x = self.conv2(x)x = x.view(x.size(0), -1)x = self.fc(x)output = self.out(x)return output
MyConvNet = ConvNet()print(MyConvNet)
ConvNet((conv1): Sequential((0): Conv2d(1, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU()(2): AvgPool2d(kernel_size=2, stride=2, padding=0))(conv2): Sequential((0): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU()(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(fc): Sequential((0): Linear(in_features=1568, out_features=128, bias=True)(1): ReLU()(2): Linear(in_features=128, out_features=64, bias=True)(3): ReLU())(out): Linear(in_features=64, out_features=10, bias=True))
需要说明的是,这两个库都是基于Graphviz开发的,因此倘若你的电脑上没有安装并且没有添加环境变量,请自行安装Graphviz工具,https://blog.csdn.net/lizzy05/article/details/88529483
1.1 通过HiddenLayer可视化网络
pip install hiddenlayer
import hiddenlayer as hvis_graph = h.build_graph(MyConvNet, torch.zeros([1 ,1, 28, 28])) # 获取绘制图像的对象vis_graph.theme = h.graph.THEMES["blue"].copy() # 指定主题颜色vis_graph.save("./demo1.png") # 保存图像的路径

1.2 通过PyTorchViz可视化网络
pip install torchviz
from torchviz import make_dotx = torch.randn(1, 1, 28, 28).requires_grad_(True) # 定义一个网络的输入值y = MyConvNet(x) # 获取网络的预测值MyConvNetVis = make_dot(y, params=dict(list(MyConvNet.named_parameters()) + [('x', x)]))MyConvNetVis.format = "png"# 指定文件生成的文件夹MyConvNetVis.directory = "data"# 生成文件MyConvNetVis.view()
默认情况下,上述程序运行后会自动打开.png文件
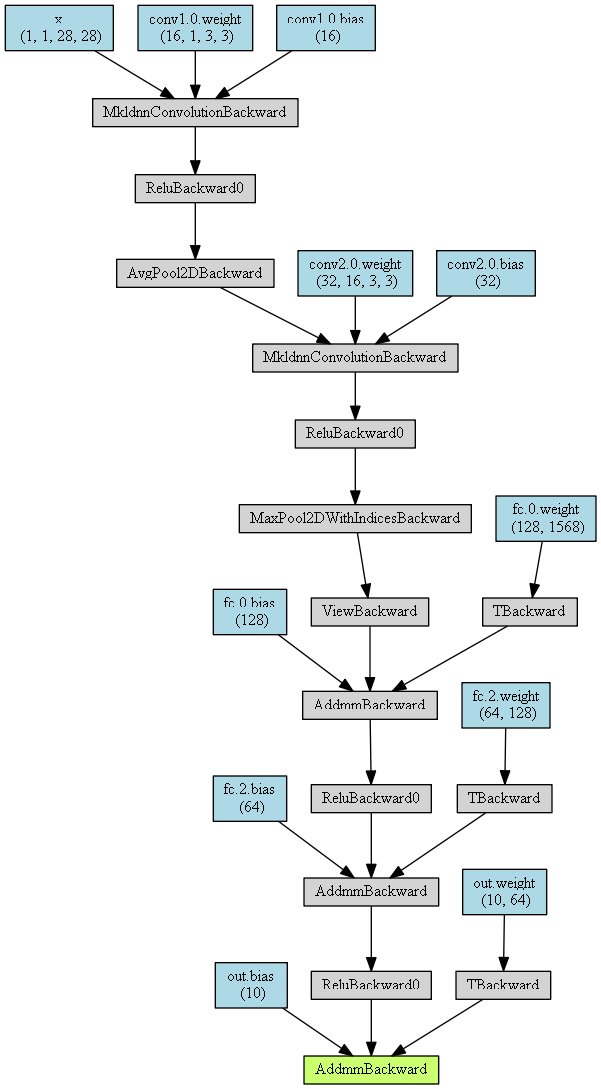
02
import torchvisionimport torch.utils.data as Data# 准备训练用的MNIST数据集train_data = torchvision.datasets.MNIST(root = "./data/MNIST", # 提取数据的路径train=True, # 使用MNIST内的训练数据transform=torchvision.transforms.ToTensor(), # 转换成torch.tensordownload=False # 如果是第一次运行的话,置为True,表示下载数据集到root目录)# 定义loadertrain_loader = Data.DataLoader(dataset=train_data,batch_size=128,shuffle=True,num_workers=0)test_data = torchvision.datasets.MNIST(root="./data/MNIST",train=False, # 使用测试数据download=False)# 将测试数据压缩到0-1test_data_x = test_data.data.type(torch.FloatTensor) / 255.0test_data_x = torch.unsqueeze(test_data_x, dim=1)test_data_y = test_data.targets# 打印一下测试数据和训练数据的shapeprint("test_data_x.shape:", test_data_x.shape)print("test_data_y.shape:", test_data_y.shape)for x, y in train_loader:print(x.shape)print(y.shape)break
test_data_x.shape: torch.Size([10000, 1, 28, 28])test_data_y.shape: torch.Size([10000])torch.Size([128, 1, 28, 28])torch.Size([128])
2.1 通过tensorboardX可视化训练过程
pip install tensorboardXpip install tensorboard
from tensorboardX import SummaryWriterlogger = SummaryWriter(log_dir="data/log")# 获取优化器和损失函数optimizer = torch.optim.Adam(MyConvNet.parameters(), lr=3e-4)loss_func = nn.CrossEntropyLoss()log_step_interval = 100 # 记录的步数间隔for epoch in range(5):print("epoch:", epoch)# 每一轮都遍历一遍数据加载器for step, (x, y) in enumerate(train_loader):# 前向计算->计算损失函数->(从损失函数)反向传播->更新网络predict = MyConvNet(x)loss = loss_func(predict, y)optimizer.zero_grad() # 清空梯度(可以不写)loss.backward() # 反向传播计算梯度optimizer.step() # 更新网络global_iter_num = epoch * len(train_loader) + step + 1 # 计算当前是从训练开始时的第几步(全局迭代次数)if global_iter_num % log_step_interval == 0:# 控制台输出一下print("global_step:{}, loss:{:.2}".format(global_iter_num, loss.item()))# 添加的第一条日志:损失函数-全局迭代次数logger.add_scalar("train loss", loss.item() ,global_step=global_iter_num)# 在测试集上预测并计算正确率test_predict = MyConvNet(test_data_x)_, predict_idx = torch.max(test_predict, 1) # 计算softmax后的最大值的索引,即预测结果acc = accuracy_score(test_data_y, predict_idx)# 添加第二条日志:正确率-全局迭代次数logger.add_scalar("test accuary", acc.item(), global_step=global_iter_num)# 添加第三条日志:这个batch下的128张图像img = vutils.make_grid(x, nrow=12)logger.add_image("train image sample", img, global_step=global_iter_num)# 添加第三条日志:网络中的参数分布直方图for name, param in MyConvNet.named_parameters():logger.add_histogram(name, param.data.numpy(), global_step=global_iter_num)
logdir后面的参数是日志文件的文件夹的路径
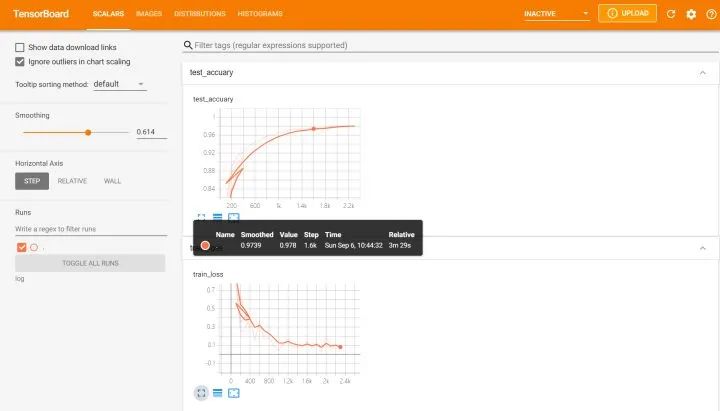
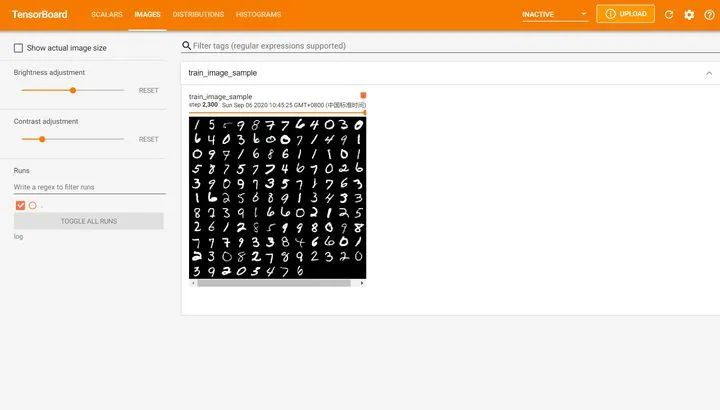
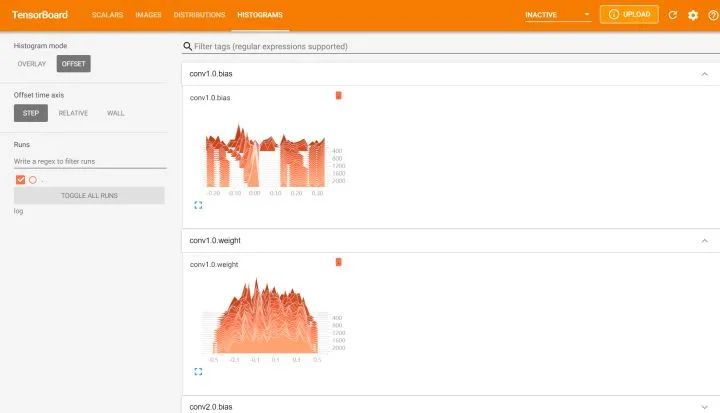
以下是笔者安装使用tensorboard时遇到的一些错误
2.2 HiddenLayer可视化训练过程
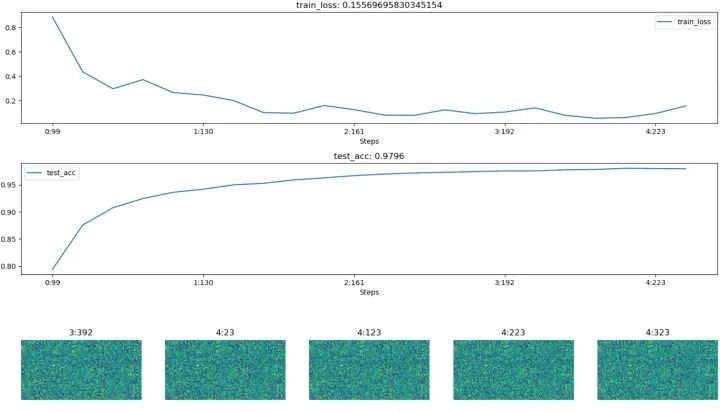
import hiddenlayer as hlimport time# 记录训练过程的指标history = hl.History()# 使用canvas进行可视化canvas = hl.Canvas()# 获取优化器和损失函数optimizer = torch.optim.Adam(MyConvNet.parameters(), lr=3e-4)loss_func = nn.CrossEntropyLoss()log_step_interval = 100 # 记录的步数间隔for epoch in range(5):print("epoch:", epoch)# 每一轮都遍历一遍数据加载器for step, (x, y) in enumerate(train_loader):# 前向计算->计算损失函数->(从损失函数)反向传播->更新网络predict = MyConvNet(x)loss = loss_func(predict, y)optimizer.zero_grad() # 清空梯度(可以不写)loss.backward() # 反向传播计算梯度optimizer.step() # 更新网络global_iter_num = epoch * len(train_loader) + step + 1 # 计算当前是从训练开始时的第几步(全局迭代次数)if global_iter_num % log_step_interval == 0:# 控制台输出一下print("global_step:{}, loss:{:.2}".format(global_iter_num, loss.item()))# 在测试集上预测并计算正确率test_predict = MyConvNet(test_data_x)_, predict_idx = torch.max(test_predict, 1) # 计算softmax后的最大值的索引,即预测结果acc = accuracy_score(test_data_y, predict_idx)# 以epoch和step为索引,创建日志字典history.log((epoch, step),train_loss=loss,test_acc=acc,hidden_weight=MyConvNet.fc[2].weight)# 可视化with canvas:canvas.draw_plot(history["train_loss"])canvas.draw_plot(history["test_acc"])canvas.draw_image(history["hidden_weight"])
不同于tensorboard,hiddenlayer会在程序运行的过程中动态生成图像,而不是模型训练完后
03
from visdom import Visdomfrom sklearn.datasets import load_irisimport torchimport numpy as npfrom PIL import Image
# 绘制图像需要的数据iris_x, iris_y = load_iris(return_X_y=True)# 获取绘图对象,相当于pltvis = Visdom()# 添加折线图x = torch.linspace(-6, 6, 100).view([-1, 1])sigmoid = torch.nn.Sigmoid()sigmoid_y = sigmoid(x)tanh = torch.nn.Tanh()tanh_y = tanh(x)relu = torch.nn.ReLU()relu_y = relu(x)# 连接三个张量plot_x = torch.cat([x, x, x], dim=1)plot_y = torch.cat([sigmoid_y, tanh_y, relu_y], dim=1)# 绘制线性图vis.line(X=plot_x, Y=plot_y, win="line plot", env="main",opts={"dash" : np.array(["solid", "dash", "dashdot"]),"legend" : ["Sigmoid", "Tanh", "ReLU"]})
# 绘制2D和3D散点图# 参数Y用来指定点的分布,win指定图像的窗口名称,env指定图像所在的环境,opts通过字典来指定一些样式vis.scatter(iris_x[ : , 0 : 2], Y=iris_y+1, win="windows1", env="main")vis.scatter(iris_x[ : , 0 : 3], Y=iris_y+1, win="3D scatter", env="main",opts={"markersize" : 4, # 点的大小"xlabel" : "特征1","ylabel" : "特征2"})
# 添加茎叶图x = torch.linspace(-6, 6, 100).view([-1, 1])y1 = torch.sin(x)y2 = torch.cos(x)# 连接张量plot_x = torch.cat([x, x], dim=1)plot_y = torch.cat([y1, y2], dim=1)# 绘制茎叶图vis.stem(X=plot_x, Y=plot_y, win="stem plot", env="main",opts={"legend" : ["sin", "cos"],"title" : "茎叶图"})
# 计算鸢尾花数据集特征向量的相关系数矩阵iris_corr = torch.from_numpy(np.corrcoef(iris_x, rowvar=False))# 绘制热力图vis.heatmap(iris_corr, win="heatmap", env="main",opts={"rownames" : ["x1", "x2", "x3", "x4"],"columnnames" : ["x1", "x2", "x3", "x4"],"title" : "热力图"})
# 可视化图片img_Image = Image.open("./example.jpg")img_array = np.array(img_Image.convert("L"), dtype=np.float32)img_tensor = torch.from_numpy(img_array)print(img_tensor.shape)# 这次env自定义vis.image(img_tensor, win="one image", env="MyPlotEnv",opts={"title" : "一张图像"})
# 可视化文本text = "hello world"vis.text(text=text, win="text plot", env="MyPlotEnv",opts={"title" : "可视化文本"})
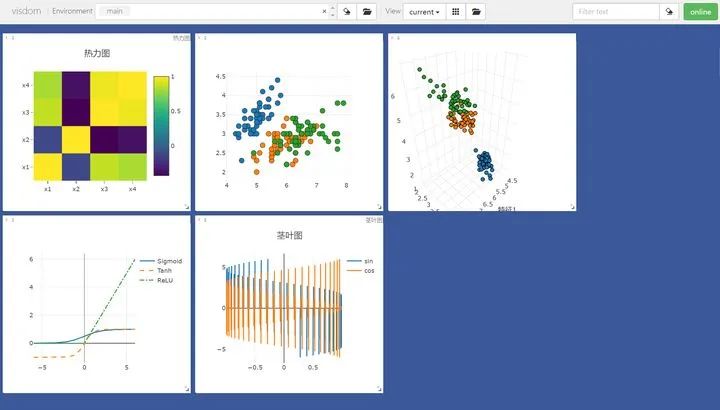
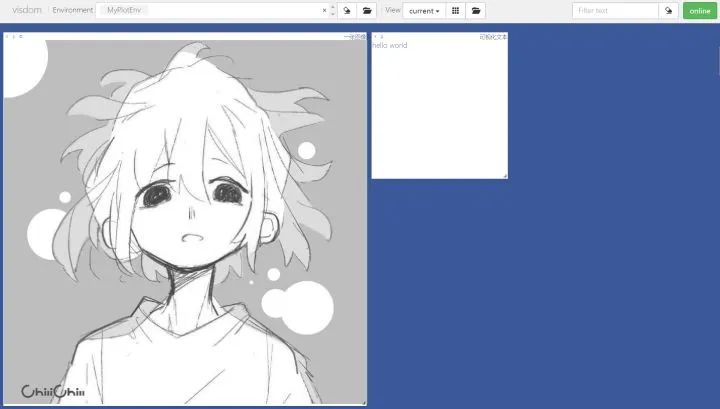
在Environment中输入不同的env参数可以看到我们在不同环境下绘制的图片。对于分类图集特别有用
04
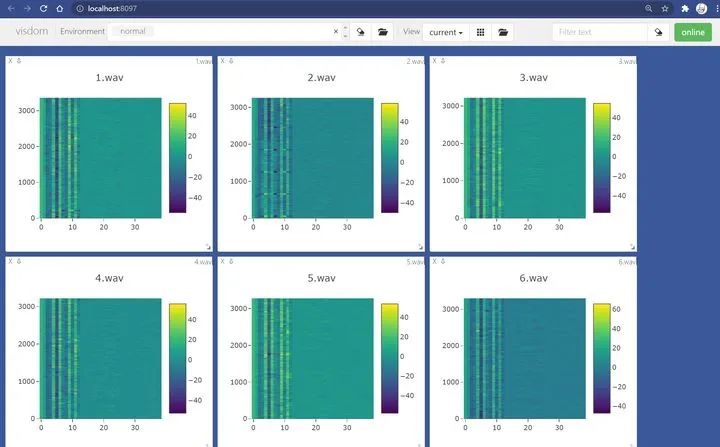
import jsonwith open(r"...\.visdom\normal.json", "r", encoding="utf-8") as f:dataset : dict = json.load(f)jsons : dict = dataset["jsons"] # 这里存着你想要恢复的数据reload : dict = dataset["reload"] # 这里存着有关窗口尺寸的数据 print(jsons.keys()) # 查看所有的win
dict_keys(['jsons', 'reload'])dict_keys(['1.wav', '2.wav', '3.wav', '4.wav', '5.wav', '6.wav', '7.wav', '8.wav', '9.wav', '10.wav', '11.wav', '12.wav', '13.wav', '14.wav'])
from visdom import Visdomvis = Visdom()print(vis.get_env_list())Setting up a new session...['main', 'normal']
from visdom import Visdomimport jsonvis = Visdom()window = vis.get_window_data(win="1.wav", env="normal") window = json.loads(window) # window 是 str,需要解析为字典content = window["content"]data = content["data"][0]print(data.keys())Setting up a new session...dict_keys(['z', 'x', 'y', 'zmin', 'zmax', 'type', 'colorscale'])
猜您喜欢:
戳我,查看GAN的系列专辑~!
一顿午饭外卖,成为CV视觉前沿弄潮儿! CVPR 2022 | 25+方向、最新50篇GAN论文 ICCV 2021 | 35个主题GAN论文汇总 超110篇!CVPR 2021最全GAN论文梳理 超100篇!CVPR 2020最全GAN论文梳理
附下载 |《TensorFlow 2.0 深度学习算法实战》
评论