
【开源】Chrome 浏览器书签层级可视化
点击上方 月小水长 并 设为星标,第一时间接收干货推送
今天推送一篇极其实用的可视化教程,可视化我们自己的浏览器中收藏的书签。
事情是这样的,昨天我在找一个收藏夹中的书签时:
由于层级过深,无法直接触达,学代码写程序就是为了解决这些小问题,我灵感一现,可不可以浏览器书签层次可视化出来,直接点击呢?说干就干,花了几个小时,完成了下面这个 mini-project。

按照收藏夹中书签的层次顺序,由根节点延伸到叶子节点,每个叶子节点就是一个书签,可以直接点击叶子节点到达对应的书签地址。
代码全部开源,地址如下,走过路过求个 star :
https://github.com/inspurer/ChromeBookmarkVisual可以复制在浏览器中打开,也可以直接点击文末的阅读原文直达。
核心代码
导出浏览器书签格式如下
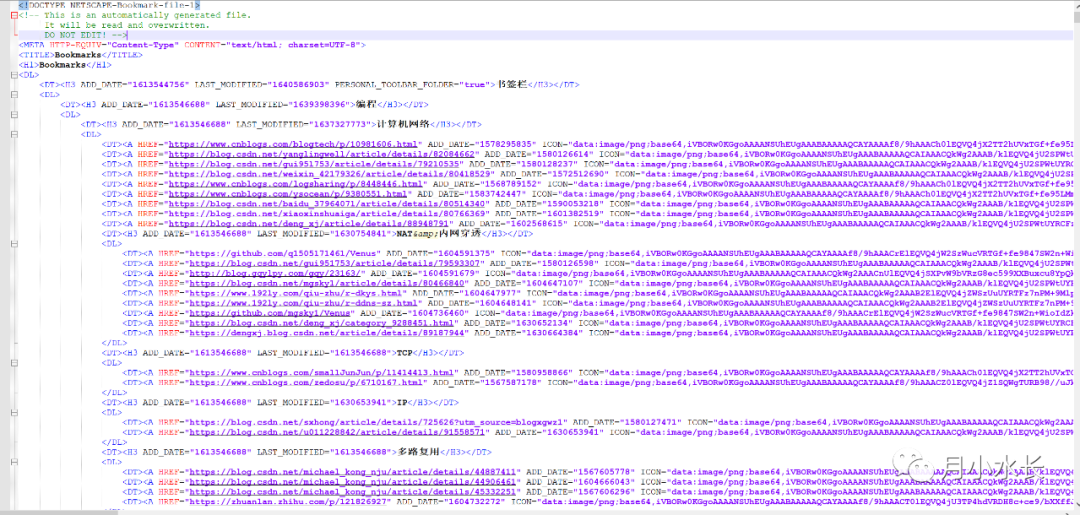
需要使用 lxml 将它解析成 json,然后扔给 echarts 做可视化。
在 lxml 解析过程中发现,由于导出的 html 中许多 DT、H3 标签没有闭合,导致解析紊乱,故先将 html 内容规范化处理之。
def get_regular_html():with open(bookmark_html_file, mode='r', encoding='utf-8-sig') as fp:html_content = fp.read()'''先规则 html 标签,否则 etree.HTML 解析的结构很混乱'''html_content = html_content.replace(r''
, '')html_content = html_content.replace(r'', r'')html_content = html_content.replace(r'', r'')return html_content
然后使用递归解析 lxml 成 json
def parse_html_recursive(root_html):children = []children_html = root_html.xpath('./child::*')for index, ele in enumerate(children_html):tag_name = ele.tag.strip()if tag_name == 'dt':if ele.xpath('./h3'):name = ele.xpath('./h3/text()')[0].strip()if name in exclude_collection:continuechildren.append({name_key: name,children_key: parse_html_recursive(children_html[index + 1])})elif ele.xpath('./a'):if len(ele.xpath('./a/text()')) == 0:print('过滤掉没有书签名的')continueurl = ele.xpath('./a/@href')[0]name = ele.xpath('./a/text()')[0].strip()children.append({name_key: name,url_key: url})return children
json 格式大致如下:
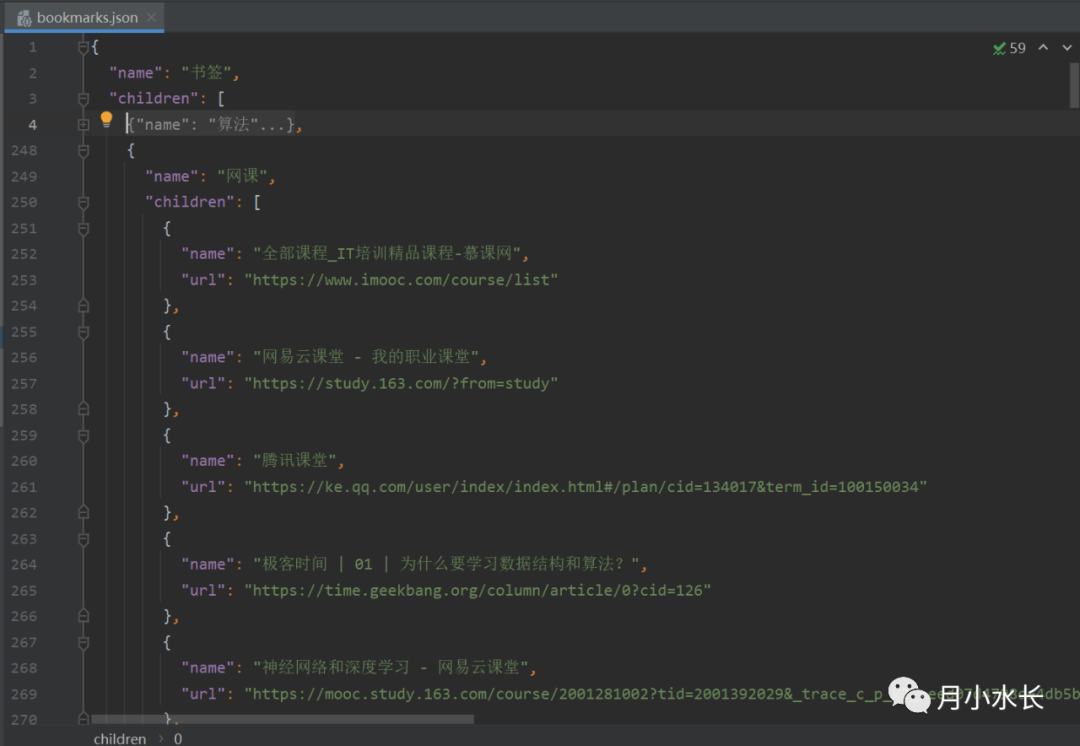
最后 echart 可视化 json 内容,这部分代码全在 tree-radial.html 中,在此就不展开了。
运行步骤
1、将代码 clone 至本地
git clone git@github.com:inspurer/ChromeBookmarkVisual.git2、安装相关的第三方库依赖
pip install requirements.txt3、在浏览器中将收藏的书签导出为 html,命名为 bookmarks.html
4、运行 py 文件得到 bookmarks.json
python parse_bookmark_html_to_json.py5、在浏览器中打开 tree-radial.html,即可看到可视化效果,并可点击叶子节点
个性配置
1、可在 py 文件中 exclude_collection 变量中添加不需要可视化的根书签收藏夹。
2、可在tree-radial.html 中可设置图表样式,如 layout = orthogonal 可设置成层次树状图,initialTreeDepth 可以设置初始最大层数。
可以参考下面的 B 站视频,查看浏览器书签导出等步骤,不要忘了一键三连~。
Referer
ECharts绘制径向图:https://www.cnblogs.com/rustfisher/p/15219690.htmlps,如果大家看教程看得很晕,直接看运行步骤即可,不明白的地方可以借鉴 B 站视频。