
使用Python快速实现图片文字识别(30行代码)
共 2108字,需浏览 5分钟
·
2022-02-09 17:36
前言
想必使用QQ的的同学中有很多人对图片转文字这个功能不陌生,这个功能极大地满足了我们的内容提取以及后期修改的需求。但是如果我们想批量进行图片转文字怎么办呢?总不能一直手动重复这么多遍吧?为了解放你的双手,提高生产力,我特地写了这篇文章来教你使用 python 来实现图片转文字,注意,只需要 30 行代码哦(去除代码注释之后)!
效果展示
待识别的图片如下


运行之后的识别结果(右边部分)

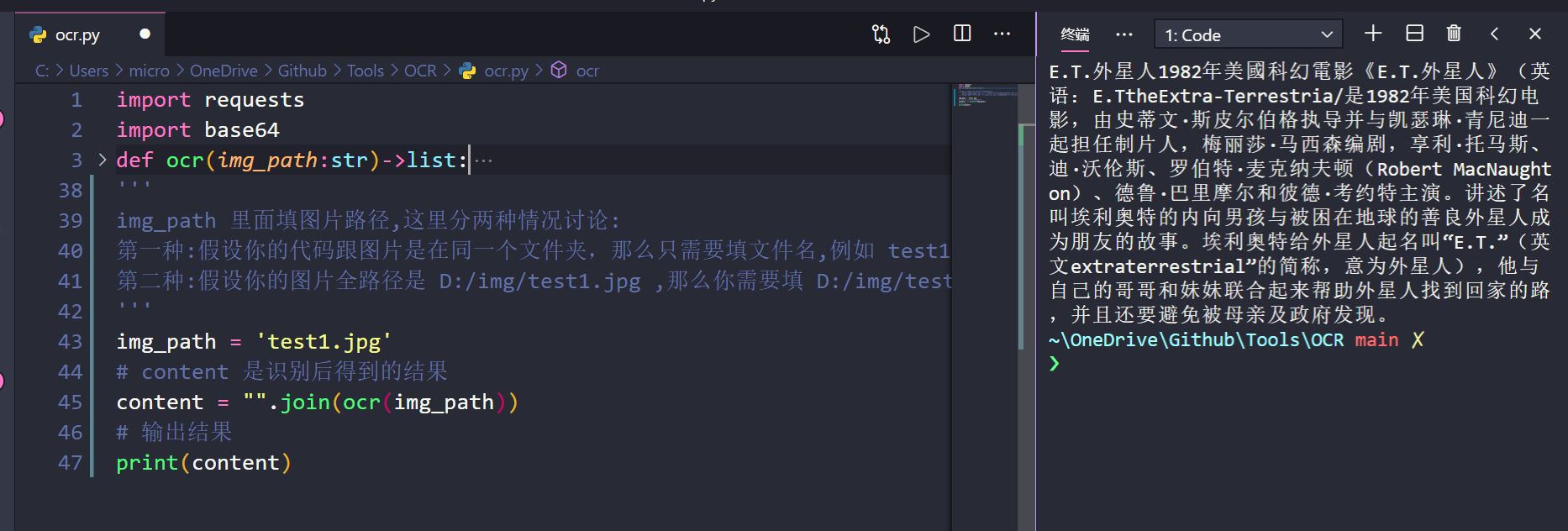
对比两张图片,可以看到识别的效果非常不错。
完整的代码
import requests
import base64
def ocr(img_path: str) -> list:
'''
根据图片路径,将图片转为文字,返回识别到的字符串列表
'''
# 请求头
headers = {
'Host': 'cloud.baidu.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.76',
'Accept': '*/*',
'Origin': 'https://cloud.baidu.com',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Dest': 'empty',
'Referer': 'https://cloud.baidu.com/product/ocr/general',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
}
# 打开图片并对其使用 base64 编码
with open(img_path, 'rb') as f:
img = base64.b64encode(f.read())
data = {
'image': 'data:image/jpeg;base64,'+str(img)[2:-1],
'image_url': '',
'type': 'https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic',
'detect_direction': 'false'
}
# 开始调用 ocr 的 api
response = requests.post(
'https://cloud.baidu.com/aidemo', headers=headers, data=data)
# 设置一个空的列表,后面用来存储识别到的字符串
ocr_text = []
result = response.json()['data']
if not result.get('words_result'):
return []
# 将识别的字符串添加到列表里面
for r in result['words_result']:
text = r['words'].strip()
ocr_text.append(text)
# 返回字符串列表
return ocr_text
'''
img_path 里面填图片路径,这里分两种情况讨论:
第一种:假设你的代码跟图片是在同一个文件夹,那么只需要填文件名,例如 test1.jpg (test1.jpg 是图片文件名)
第二种:假设你的图片全路径是 D:/img/test1.jpg ,那么你需要填 D:/img/test1.jpg
'''
img_path = 'test1.jpg'
# content 是识别后得到的结果
content = "".join(ocr(img_path))
# 输出结果
print(content)
注意事项
以上代码为 python 代码 ,如需要运行成功,则要安装 python3 版本,并且需要额外安装 requests 这个第三方库,如果你没有具备以上条件,可以看看我的这篇文章来搭建基础环境
顺手牵羊:Win下快速搭建Python编程环境如果你想批量进行图片转文字,那么需要具备一定的编程基础,例如会使用 for 循环语句。对于小白而言,没有空学这个的话,可以给我留言,我后面再加上能实现图片批量转文字的版本。
最后
感谢大家的阅读,希望我的分享能给你带来帮助。
评论