
耗时减半?腾讯云OCR只做了3件事

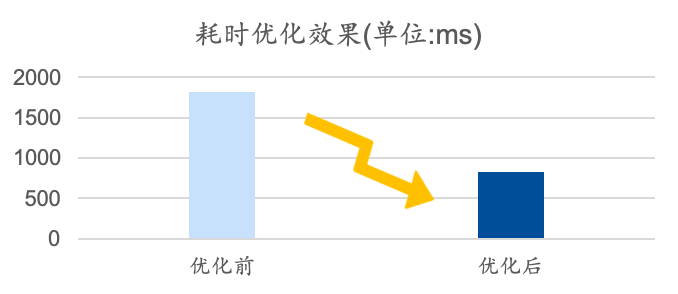
导读|腾讯云OCR团队在产品性能的长期优化实践中,结合客户使用场景及产品架构对服务耗时问题进行了深入剖析和优化。本文作者——腾讯研发工程师彭碧发详细介绍了OCR团队在耗时优化中的思路和方法(如工程优化、模型优化、TIACC加速等),通过引入TSA算法使用TI-ACC减少模型的识别耗时,结合客户使用场景优化编解码逻辑、对关键节点的日志分流以及与客户所在地就近部署持续降低传输耗时,克服OCR耗时优化面临的环节多、时间短甚至成本有限的问题,最终实现了OCR产品平均耗时从1815ms降低到824ms。希望大家在阅读中能收获一些新的思路。

背景介绍
但是耗时优化是一个系统性工程,需要多方的支持和协作。文字识别服务进行耗时优化,主要有以下挑战:
环节多:耗时优化涉及多个环节,包括模型算法、TI-ACC、工程等。各环节都需要分析各自阶段耗时,制定完整的耗时优化目标。 时间短:客户耗时优化诉求强烈,但是给到的优化的时间很短。 成本考量:降本增效大背景下,单纯依赖机器的情况一去不复返。耗时优化方案也需要考虑成本优化。

分析问题
1)框架和链路分析
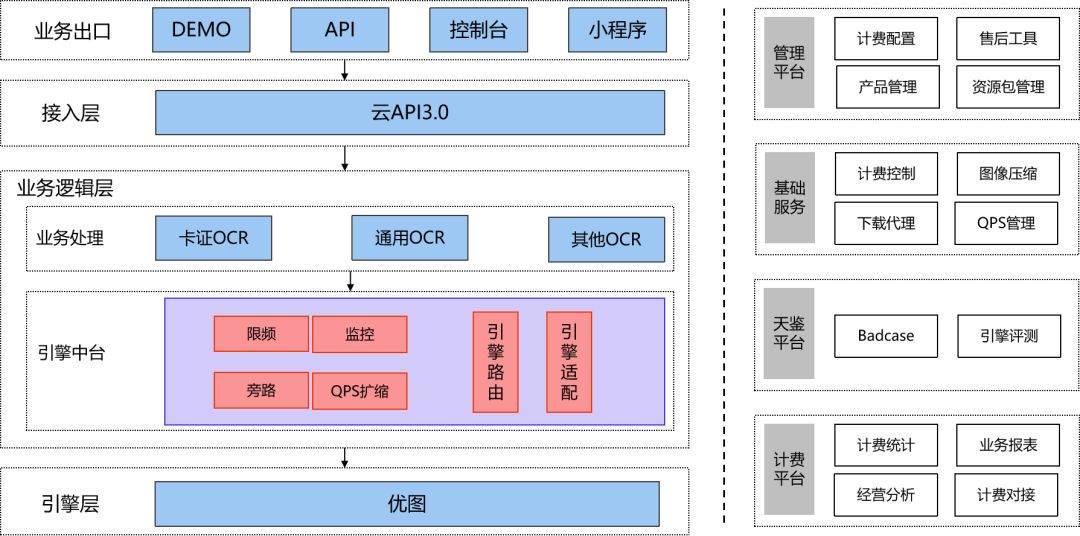
云API层:请求首先会传输到离客户最近的云API接入点,云API接入点会进行相应的鉴权、寻址、转发等操作。 业务逻辑层:文字识别逻辑层服务会对数据做处理、下载、计费、上报等操作。 引擎层:算法引擎服务对图片进行处理,识别出文字。
2)主要阶段耗时
客户传输耗时:客户请求到云API和云API响应到客户链路的传输耗时在测试过程中发现波动很大。文字识别业务场景下请求传输的都是图片数据,这受客户网络带宽和质量的影响大。此外,因客户请求的文字识别服务在广州,所以请求需要跨地域。这进一步增加了传输耗时。 业务逻辑耗时:业务逻辑中有很多复杂的工程处理,主要耗时点包括数据处理、编解码、图片下载、路由、上报等。 算法引擎耗时:想达到更好的识别效果和泛化性,通用OCR模型会比较复杂。检测和识别都会涉及到复杂的浮点计算,耗时长。
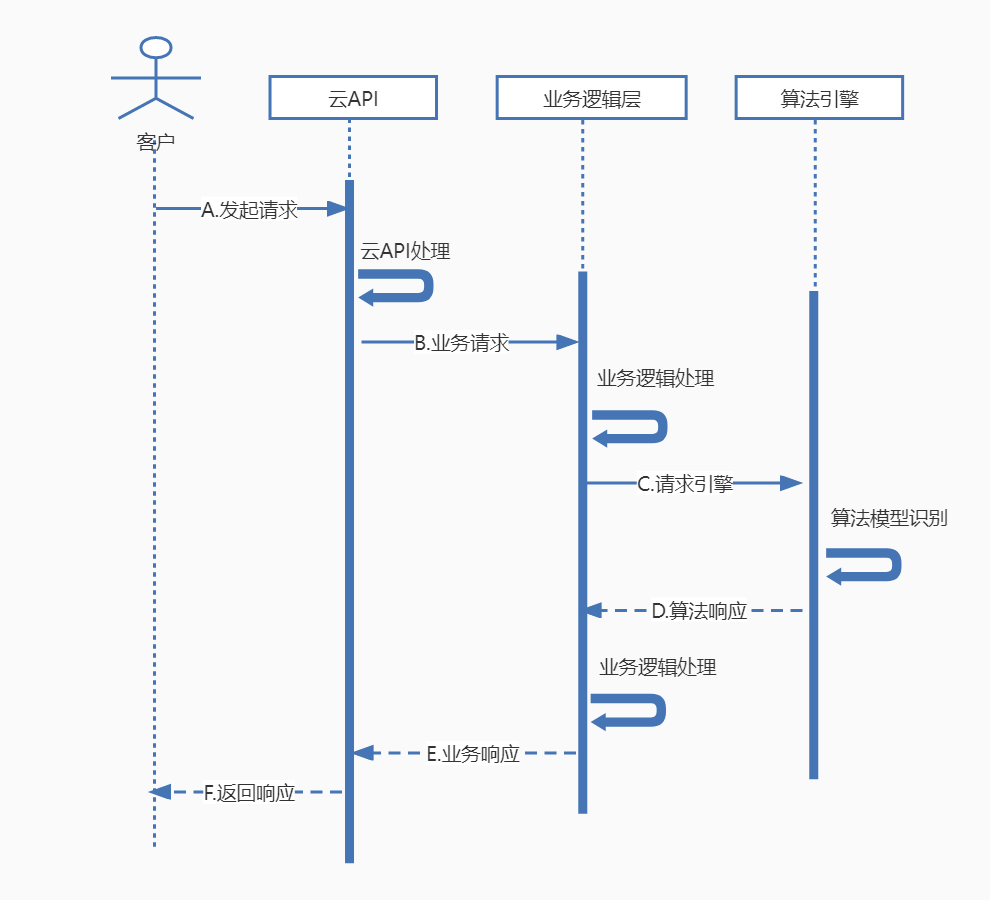
3)测试方法和结论

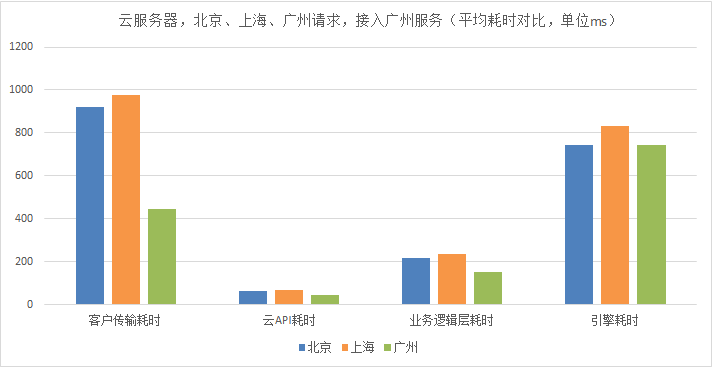
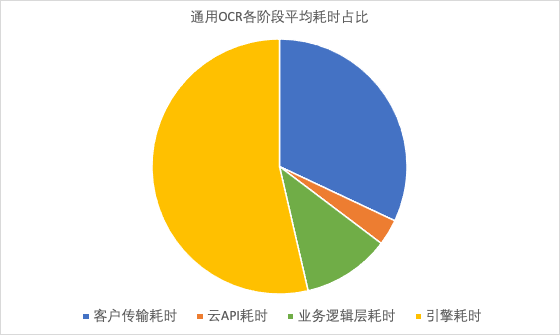
客户的传输耗时占比很大。主要是因为客户在北京发起请求,需要跨地域到广州的服务,存在很大的传输耗时,这部分需要我们通过优化部署来减低耗时。 在服务链路中,业务逻辑处理的耗时也较多。这部分耗时需要我们精益求精,优化工程逻辑和架构,进而降低耗时。 文字识别服务的引擎耗时占比最高。所以我们需要对算法引擎的耗时进行重点优化。
 解决问题
解决问题
1 )模型优化—引入TSA算法减少模型耗时
OCR特点与算法过程分析

TSA研发背景
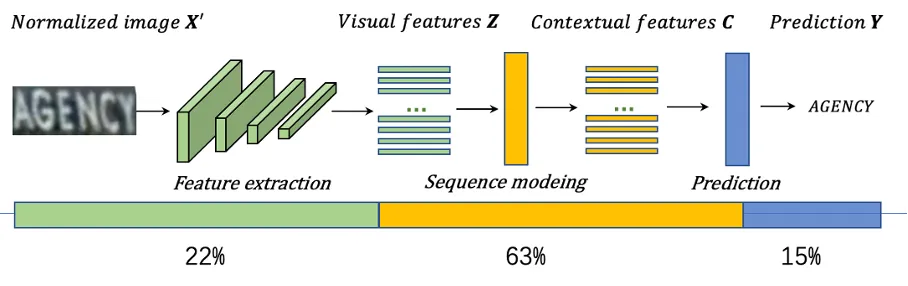
识别模型特点
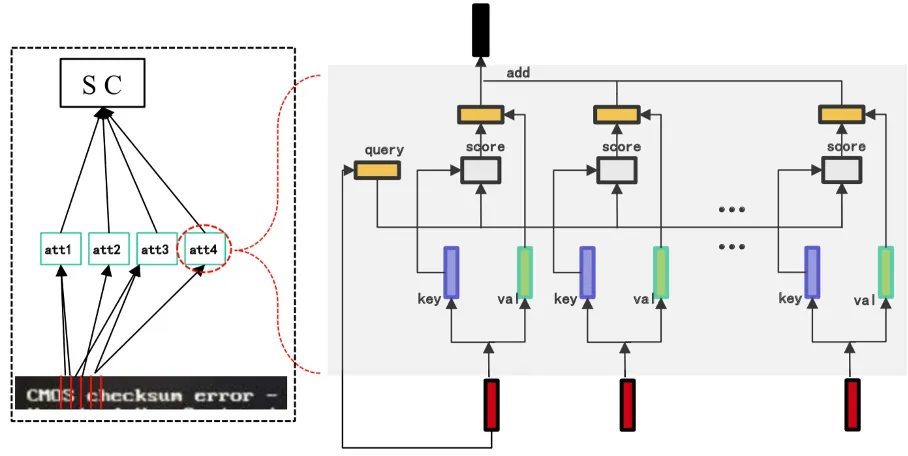
2 )TIACC加速优化—继续减少模型耗时
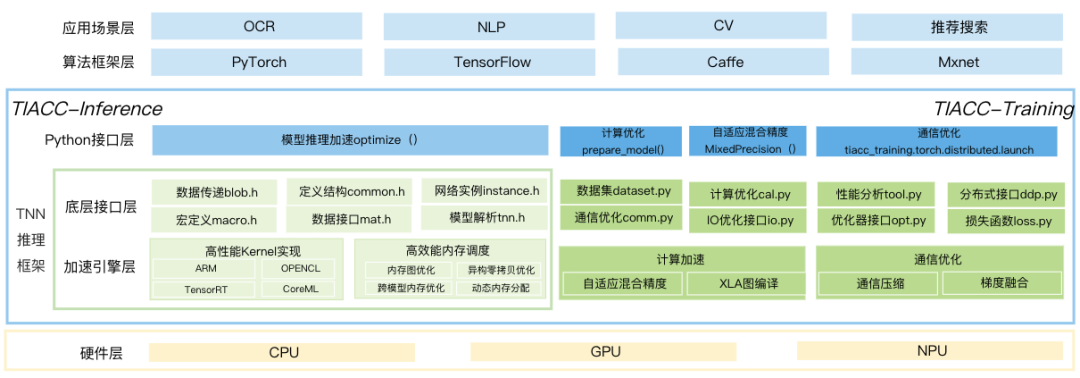
支持复杂结构模型

降低请求延迟并提高系统吞吐
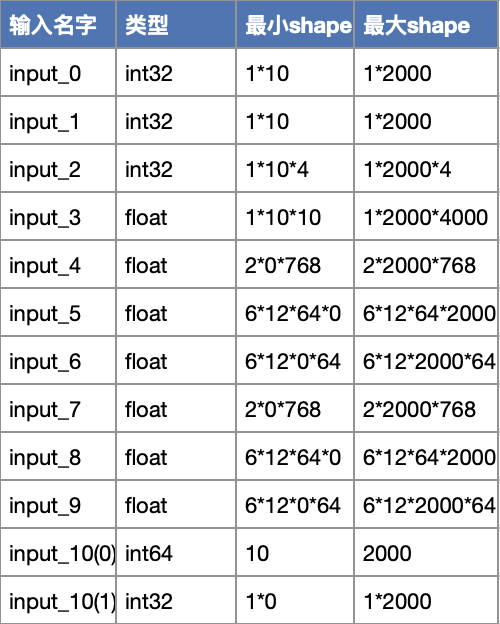

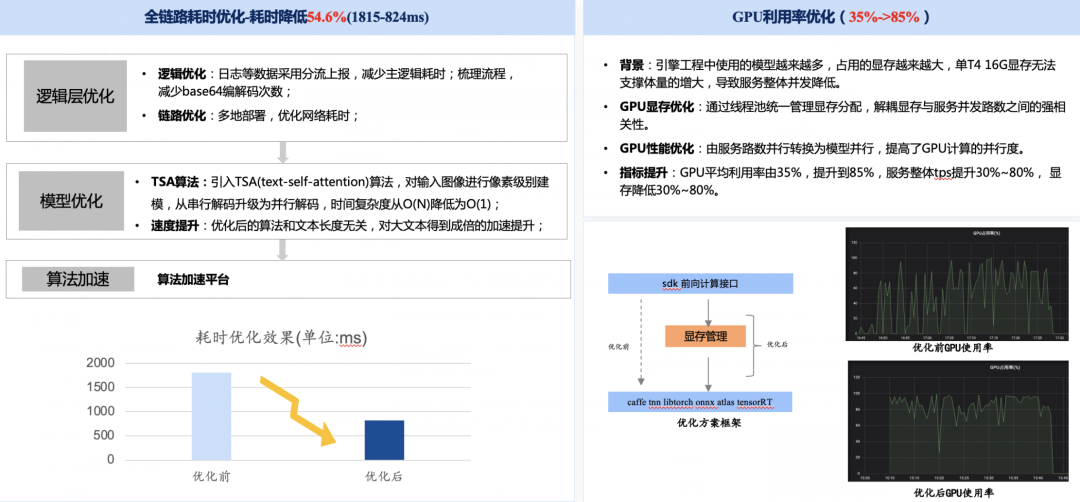
3)工程优化——优化逻辑和传输耗时
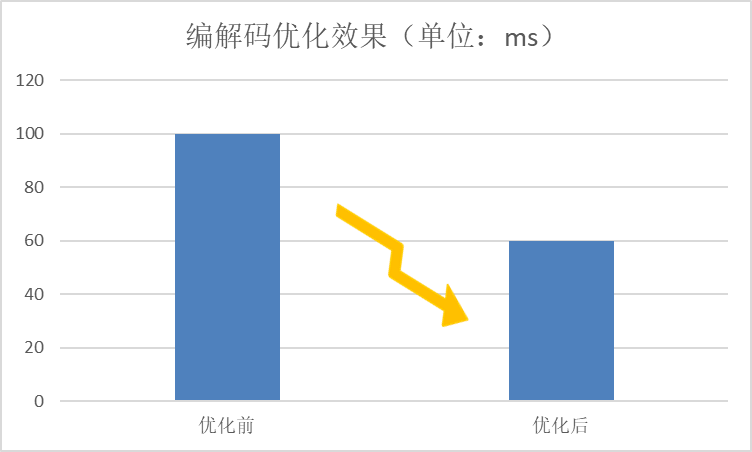
编解码优化
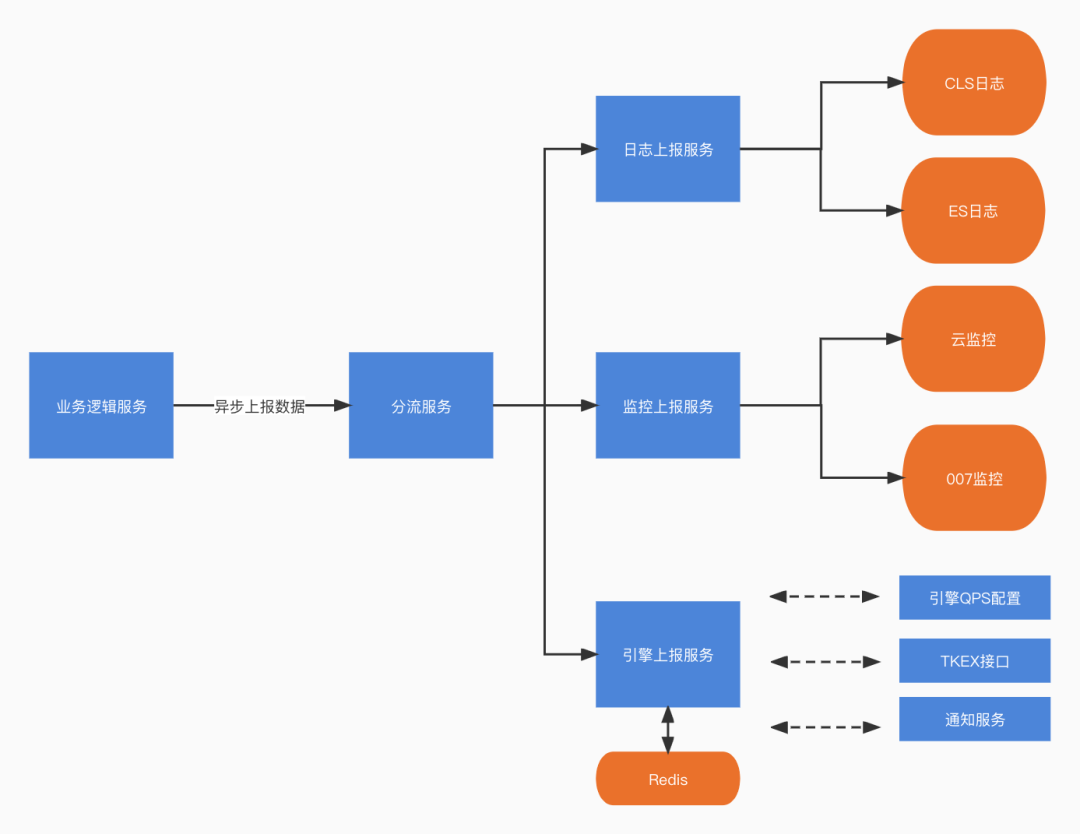
日志分流处理
就近部署—降低传输耗时

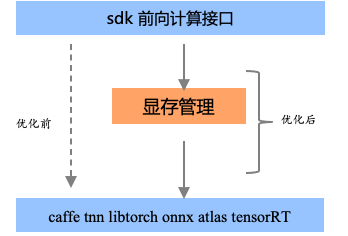
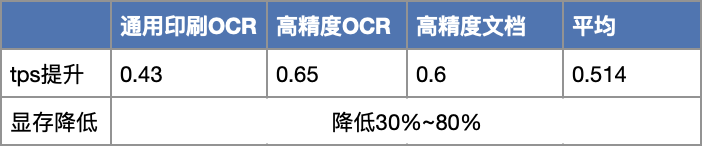
GPU显存优化-提高系统吞吐
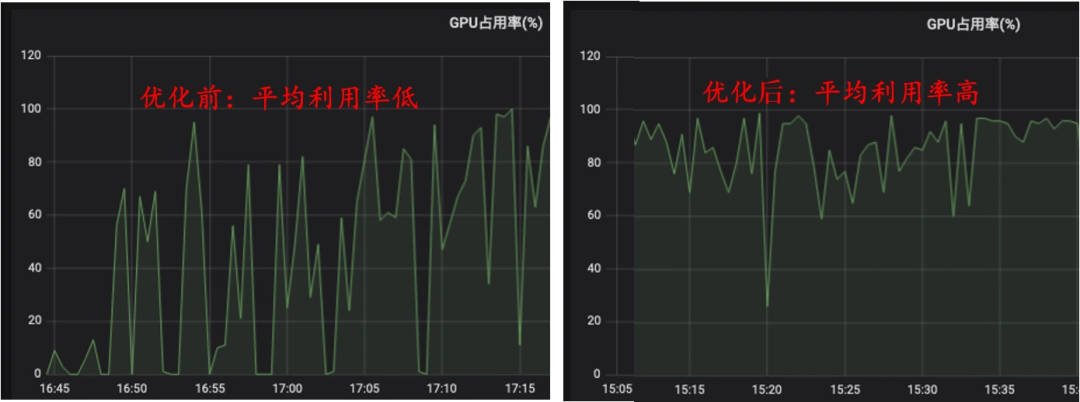
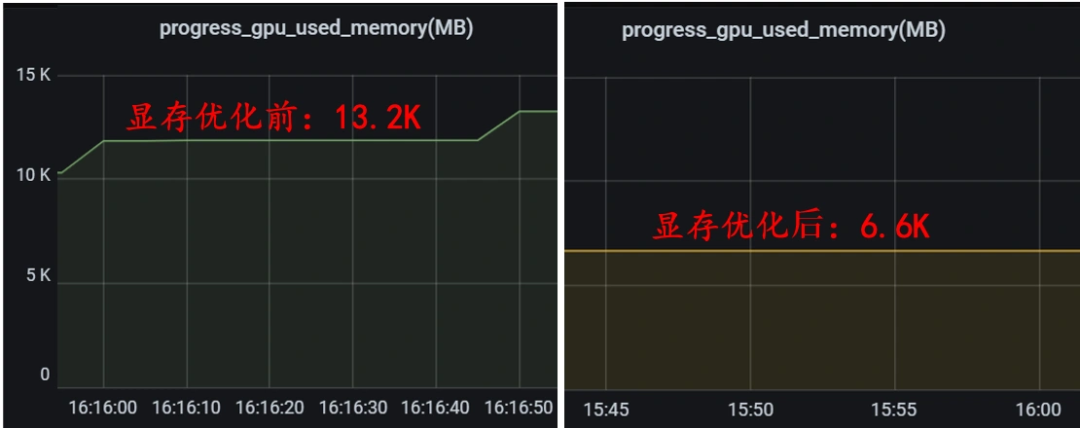

最终效果
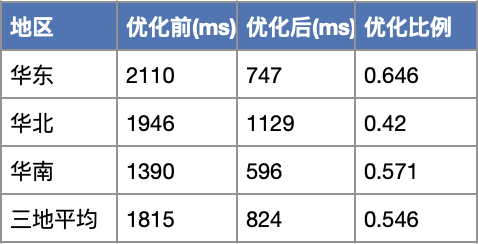
1)通用OCR平均耗时优化54.6%
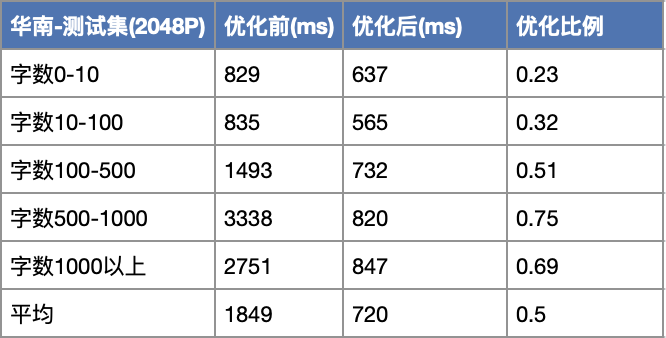
2、图片文字越多,耗时优化越明显
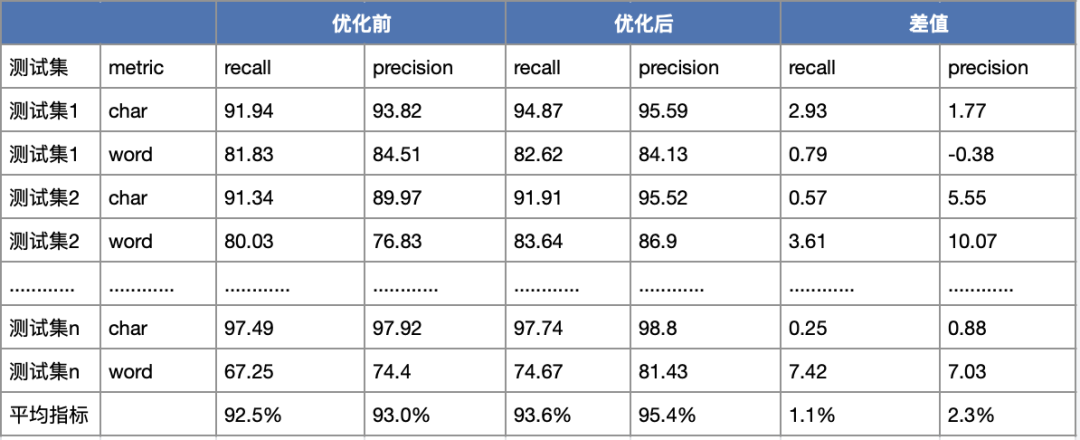
3、召回率提升1.1%

成本降低

结语

评论