
面试官:谈谈MySQL的limit用法、逻辑分页和物理分页
来源:blog.csdn.net/lvoelife/article/details/81943070
物理分页为什么用limit
在讲解limit之间,我们先说说分页的事情。
分页有逻辑分页和物理分页,就像删除有逻辑删除和物理删除。逻辑删除就是改变数据库的状态,物理删除就是直接删除数据库的记录,而逻辑删除只是改变该数据库的状态。例如
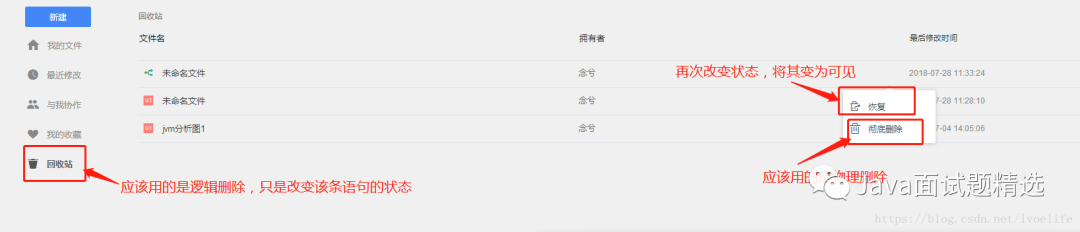
同理,逻辑分页和物理分页是有区别的

为什么逻辑分页占用较大的内存空间,比如我有一张表,表的信息是:
-- ----------------------------
-- Table structure for vote_record_memory
-- ----------------------------
DROP TABLE IF EXISTS `vote_record_memory`;
CREATE TABLE `vote_record_memory` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` varchar(20) NOT NULL,
`vote_id` int(11) NOT NULL,
`group_id` int(11) NOT NULL,
`create_time` datetime NOT NULL,
PRIMARY KEY (`id`),
KEY `index_id` (`user_id`) USING HASH
) ENGINE=MEMORY AUTO_INCREMENT=3000001 DEFAULT CHARSET=utf8;
向该表中插入300万条数据后,再转储到桌面,查看转储后的SQL文件的属性:
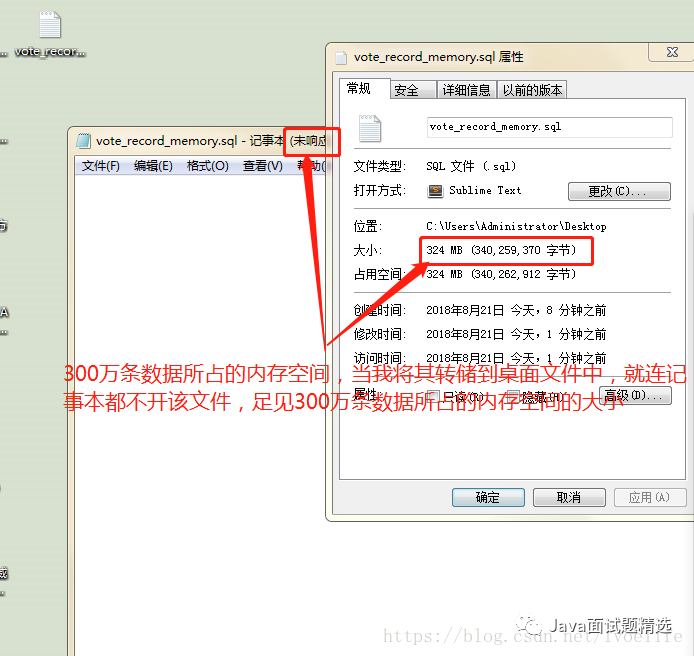
这是多么庞大的数据,占用的内存多么可怕,为什么我们再选用数据库。这也是我们使用云服务器时,设定mysql的存储空间的大小。
我们一般不推荐使用逻辑分页,而使用物理分页。在使用物理分页的时候,就要考虑到limit的用法。
解释limit
limit X,Y ,跳过前X条数据,读取Y条数据
X表示第一个返回记录行的偏移量,Y表示返回记录行的最大数目
如果X为0的话,即 limit 0, Y,相当于limit Y、
通过业务分析limit
我有一张工资表,只显示最新的_前两条记录_,同时进行员工姓名和工资提成备注查询
SELECT
cue.real_name empName,
zs.push_money AS pushMoney,
zs.push_money_note AS pushMoneyNote,
zs.create_datetime AS createTime
FROM
zq_salary zs //主表
LEFT JOIN core_user_ext cue ON cue.id = zs.user_id //从表 on之后是从表的条件
WHERE
zs.is_deleted = 0
AND (
cue.real_name LIKE '%李%'
OR zs.push_money_note LIKE '%测%'
)
ORDER BY
zs.create_datetime DESC
LIMIT 2;
就相当于
ORDER BY
zs.create_datetime DESC
LIMIT 0,2;

limit的效率问题
我有一个需求,就是从vote_record_memory表中查出3600000到3800000的数据,此时在id上加个索引,索引的类型是Normal,索引的方法是BTREE,分别用两种方法查询
-- 方法1
SELECT * FROM vote_record_memory vrm LIMIT 3600000,20000 ;
-- 方法2
SELECT * FROM vote_record_memory vrm WHERE vrm.id >= 3600000 LIMIT 20000
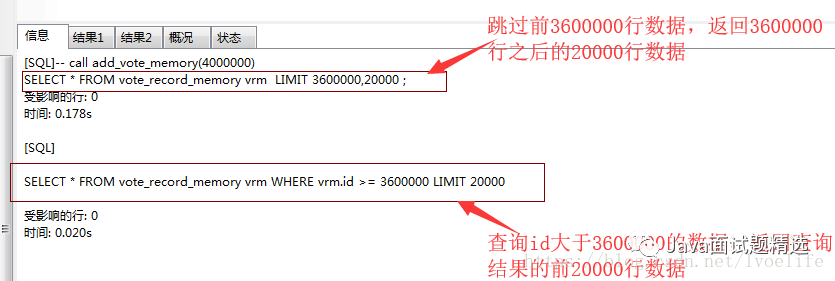
你会发现,方法2的执行效率远比方法1的执行效率高,几乎是方法1的九分之一的时间。
为什么方法1的效率低,而方法二的效率高呢?
分析一、
因为在方法1中,我们使用的单纯的limit。limit随着行偏移量的增大,当大到一定程度后,会出现效率下降。而方法2用上索引加where和limit,性能基本稳定,受偏移量和行数的影响不大。
分析二、
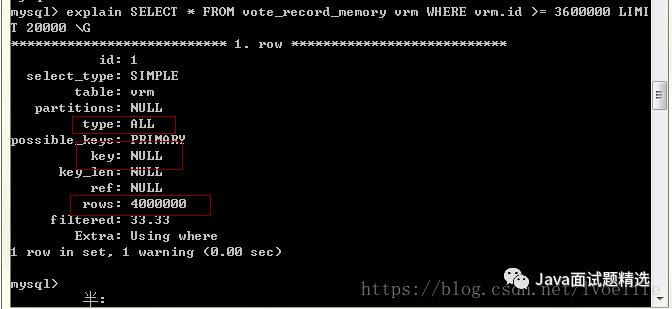
我们用explain来分析

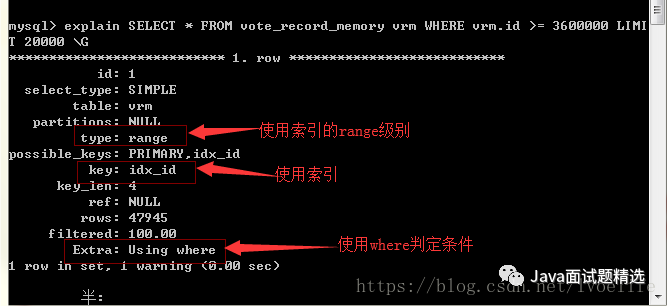
可见,limit语句的执行效率未必很高,因为会进行全表扫描,这就是为什么方法1扫描的的行数是400万行的原因。方法2的扫描行数是47945行,这也是为什么方法2执行效率高的原因。我们尽量避免全表扫描查询,尤其是数据非常庞大,这张表仅有400万条数据,方法1和方法就有这么大差距,可想而知上千万条的数据呢。
能用索引的尽量使用索引,type至少达到range级别_,这不是我说的,这是阿里巴巴开发手册的5.2.8中要求的_

我不用索引查询到的结果和返回的时间和方法1的时间差不多:
SELECT * FROM vote_record_memory vrm WHERE vrm.id >= 3600000 LIMIT
20000 受影响的行: 0 时间: 0.196s
这也就是我们为什么尽量使用索引的原因。mysql索引方法一般有BTREE索引和HASH索引,hash索引的效率比BTREE索引的效率高,但我们经常使用BTREE索引,而不是hash索引。因为最重要的一点就是:Hash索引仅仅能满足”=”,”IN”和”<=>”查询,不能使用范围查询。
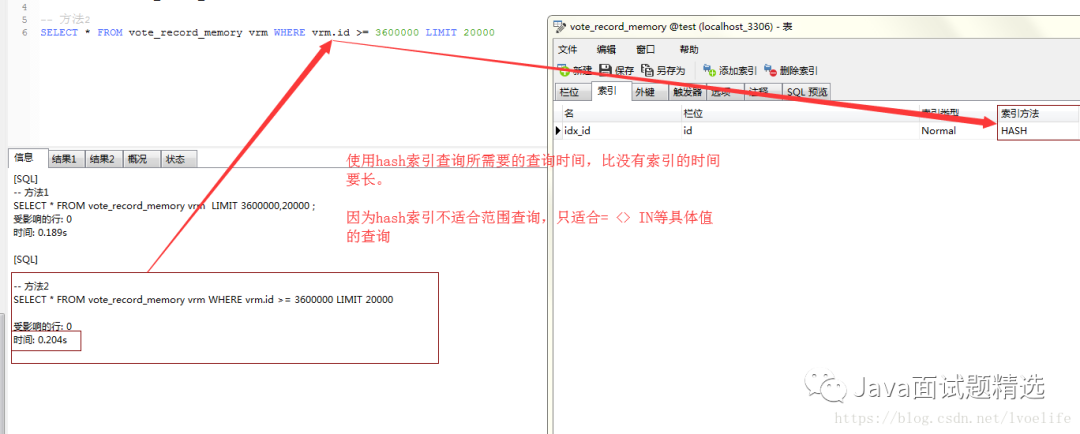
如果是范围查询,我们为什么用BTREE索引的原因。BTREE索引就是二叉树索引,学过数据结构的应该都清楚,这里就不赘述了。
limit物理分页
我们都知道limit一般有两个参数,X和Y,X表示跳过X个数据,读取Y个数据,我们就此来查询数据

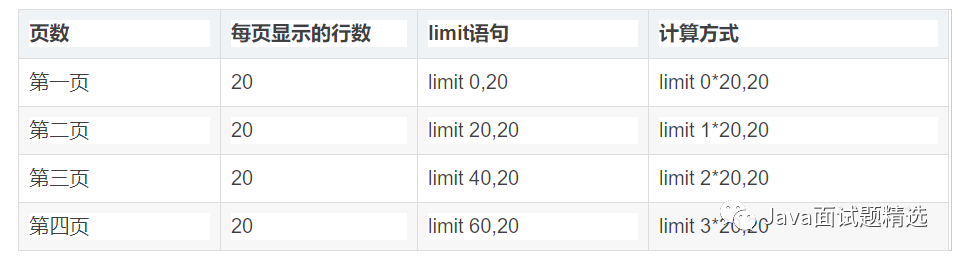
如果是SQL语句来进行分页的话,我们可以看到的是:
-- 首页
SELECT * from vote_record_memory LIMIT 0,20;
-- 第二页
SELECT * from vote_record_memory LIMIT 20,20;
-- 第三页
SELECT * from vote_record_memory LIMIT 40,20;
-- 第四页
SELECT * from vote_record_memory LIMIT 60,20;
-- n页
SELECT * from vote_record_memory LIMIT (n-1)*20,20;
因而,如果是用java的话,我们就可以写一个方法,有两个参数,一个是页数,一个每页显示的行数
/**
* @description 简单的模拟分页雏形
* @author zby
* @param currentPage 当前页
* @param lines 每页显示的多少条
* @return 数据的集合
*/
public List{
String sql = "SELECT * from vote_record_memory LIMIT " + (currentPage - 1) * lines + "," + lines;
return null;
}
↓↓↓↓点击下方获取源码和教程↓↓↓↓