
编译的速度与激情:从10mins到1s
导语:对于大型前端项目而言,构建的稳定性和易用性至关重要,腾讯文档在迭代过程中,复杂的项目结构和编译带来的问题日益增多,极大的增加了新人上手与日常搬砖的开销。恰逢 Webpack5 上线,不如来一次彻底的魔改~
1.前言
腾讯文档最近基于刚刚发布的 Webpack5 进行了一次编译的大重构,作为一个多个仓库共同构成的大型项目,任意品类的代码量都超过百万。对于腾讯文档这样一个快速迭代,高度依赖自动化流水线,常年并行多个大型需求和无数小需求的项目来说,稳定且快速的编译对于开发效率至关重要。
这篇文章,就是笔者最近进行重构,成功将日常开发优化到 1s 的过程中,遇到的一些大型项目特有的问题和思考,希望能给大家在前端项目构建的优化中带来一些参考和启发。
2.大型项目编译之痛
随着项目体系的逐渐扩大,往往会遇到旧的编译配置无法支持新特性,由于各种 config 文件自带的阅读 debuff,以及累累的技术债,大家总会趋于不去修改旧配置,而是试图新增一些配置在外围对编译系统进行修正。也是这样类似的原因,腾讯文档过去的编译编译也并不优雅:
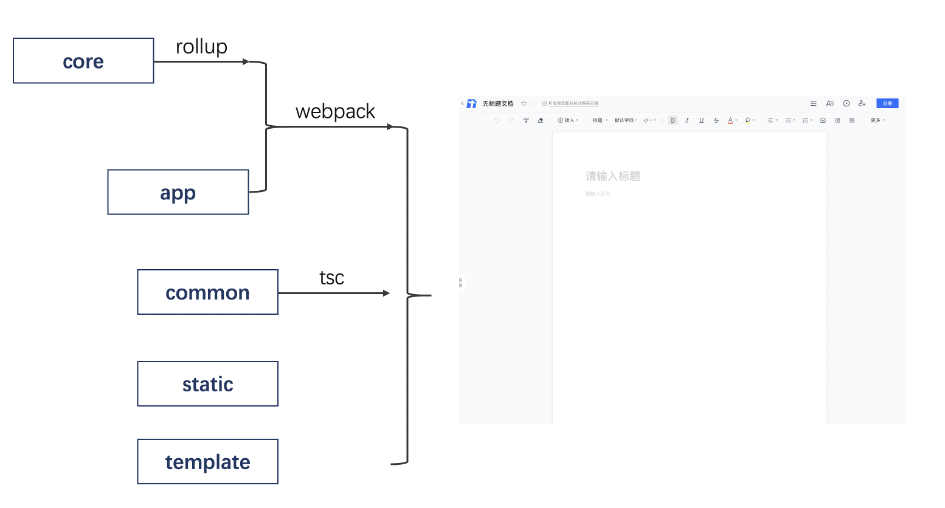
多级的子仓库结构,复杂的编译系统造成很高的理解和改动成本,也带来了较高的编译耗时,对于整个团队的开发效率有着不小的影响。
3.All in One
为了解决编译复杂和缓慢的问题,至关重要的,就是禁止套娃:多层级混合的系统必须废除,统一的编译才是王道。在所有编译系统中,Webpack 在大项目的打包上具备很强优势,插件系统最为丰满,并且 Webpack5 的带来了 Module Federation 新特性,因此笔者选择了用 Webpack 来统合多个子仓库的编译。
3.1.整合基于 lerna 的仓库结构
腾讯文档使用了 lerna 来管理仓库中的子包,使用 lerna 的好处此处就不作展开了。不过 lerna 的通用用法也带来了一定的问题,lerna 将一个仓库变成了结构上的多个仓库,如果按照默认的使用方式,每个仓库都会有自己的编译配置,单个项目的编译变成了多个项目的联编联调,修改配置和增量优化都会变得比较困难。
虽然使用 lerna 的目的是使各个子包相对独立,但是在整个项目的编译调试中,往往需要的是所有包的集合,那么,笔者就可以忽略掉这个子包间的物理隔离,把子仓库作为子目录来看待。不依赖 lerna,笔者需要解决的,是子包间的引用问题:
/** package/layout/src/xxx.ts **/import { Stream } from "@core/model";// do something
事实上,笔者可以通过 webpack 配置中 resolve 的 alias 属性来达到相应效果:
{resolve: {alias: {'@core/model': 'word/package/model/src/',}}}
3.2.管理游离于打包系统之外的文件
在大型项目中,有时会存在一些特殊的静态代码文件,它们往往并不参与到打包系统中,而是由其他方式直接引入 html,或者合并到最终的结果中。
这样的文件,一般分为如下几类:
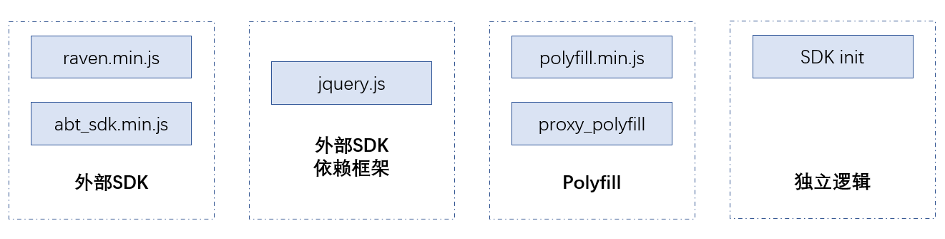
加载时机较早的外部 sdk 文件,本身以 minify 文件提供
外部文件依赖的其他框架文件,比如 jquery
一些 polyfill
一些特殊的必须早期运行的独立逻辑,比如初始化 sdk 等
由于 polyfill 和外部 sdk 往往直接通过挂全局变量运行的模式,项目中往往会通过直接写入 html script 标签的方式引用它们。不过,随着此类文件的增多,直接利用标签引用,对于版本管理和编译流程都不友好,它们对应的一些初始化逻辑,也无法添加到打包流程中来。这种情况,笔者建议手工的创建一个 js 入口文件,对以上文件进行引用,并作为 webpack 的一个入口。如此,就能通过代码的方式,将这些散装文件管理起来了:
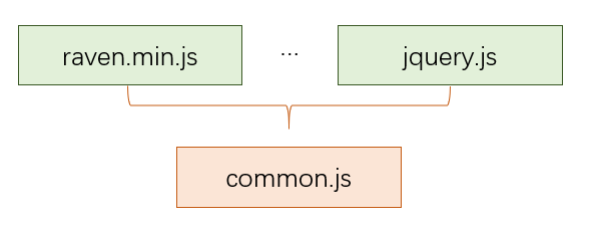
import "jquery";import "raven.min.js";import "log.js";// ...
但是,一些外部的 js 可能依赖于其他 sdk,比如 jQuery,但是打包系统并不知道它们之间的依赖关系,导致 jQuery 没有及时暴露到全局中,该怎么办呢?事实上,webpack 提供了很灵活的方案来处理这些问题,比如,笔者可以通过 expose-loader,将 jQuery 的暴露到全局,供第三方引用。
在腾讯文档中,还包含了一些对远程 cdn 的 sdk 组件,这些 sdk 也需要引用一些库,比如 jQuery 的。因此,笔者还通过 splitChunks 的配置,将 jQuery 重新分离出来,放在了较早的加载时机,保证基于 cdn 加载的 sdk 亦能正常初始化。
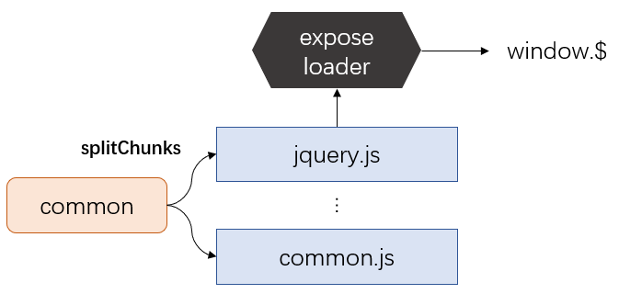
通过代码引用,一方面,可以很好的进行依赖文件的版本管理;另一方面,由于对应文件的编译也加入了打包流程,所有对应文件的改动都可以被动态监视到,有利于后续进行增量编译。同时,由于 webpack 的封装特点,每个库都会被包含在一个 webpack_require 的特殊函数之中,全局变量的暴露数量也变得较为可控。
3.3.定制化的 webpack 流程
Webpack 提供了一个非常灵活的 html-webpack-plugin 来进行 html 生成,它支持模板和一众的专属插件,但是,仍然架不住项目有一些特殊的需求,通用的插件配置要么无法满足这些需求,要么适配的结果就十分难懂。这也是腾讯文档在最初使用了 gulp 来生成 html 的原因,在 gulp 配置中,有很多自定义流程来满足腾讯文档的发布要求。
既然,gulp 可以自定义流程来实现 html 生成,那么,笔者也可以单独写一个 webpack 插件来实现定制的流程。
Webpack 本身是一个非常灵活的系统,它是一个按照特定的流程执行的框架,在每个流程的不同的阶段提供了不同的钩子,通过各种插件去实现这些钩子的回调,来完成代码的打包,事实上,webpack 本身就是由无数原生插件组成的。在这整个流程中,笔者可以做各种不同的事情来定制它。

对于生成 html 的场景,通过增加一个插件,在 webpack 处理生成文件的阶段,将生成的 js、css 等资源文件,以及 ejs 模板和特殊配置整合到一起,再添加到 webpack 的 assets 集合中,便可以完成一次自定义的 html 生成。
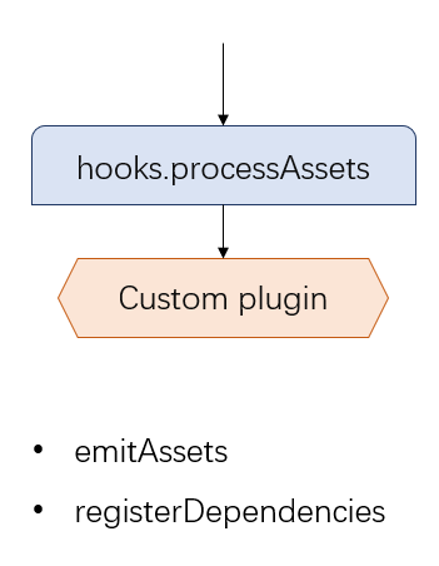
compilation.hooks.processAssets.tap({name: "TemplateHtmlEmitPlugin",stage: Compilation.PROCESS_ASSETS_STAGE_ADDITIONAL,},() => {// custom generationcompilation.emitAsset(`${parsed.name}.html`,new sources.RawSource(source, true));compilation.fileDependencies.addAll(dependencies);});
在以上代码中,大家可以留意到最后一句: compilation.fileDependencies.addAll(dependencies),通过这一句,笔者可以将所有被自定义生成所依赖的文件加入的 webpack 的依赖系统中,那么当这些文件发生变更的时候,webpack 能够自动再次触发对应的生成流程。
3.4.一键化的开发体验
至此,各路编译都已经统一化,笔者可以用一个 webpack 编译整个项目了,watch 和 devServer 也可以一起 high 起来。不过,既然编译可以统一,何不让所有操作都整合起来呢?
基于 node_modules 不应该手工操作的假设,笔者可以创建 package.json 中依赖的快照,每次根据 package 的变化来判断是否需要重新安装,避免开发同学同步代码后的手动判断,跳过不必要的步骤。
public async install(force = false) {const startTime = performance.now();const lastSnapshot = this.readSnapshot();const snapshot = this.createSnapshot();const runs = this.repoInfos.map((repo) => {if (this.isRepoInstallMissing(repo.root)|| (!repo.installed&& (force || !isEqual(snapshot[repo.root], lastSnapshot[repo.root])))) {// create and return install cmd}return undefined;}).filter(script => !!script);const { info } = console;if (runs.length > 0) {try {// 执行安装并保存快照await Promise.all(runs.map(run => this.exec(run!.cmd, run!.cwd, run!.name)));this.saveSnapshot(snapshot);} catch (e) {this.removeSnapshot();throw e;}} else {info(chalk.green('Skip install'));}info(chalk.bgGreen.black(`Install cost: ${TimeUtil.formatTime(performance.now() - startTime)}`));}
同样的,腾讯文档的本地调试是基于特殊的测试环境,通过 whislte 进行代理,这样的步骤也可以自动化,那么,对于开发来说,一切就很轻松了,一条命令,轻松搬砖~
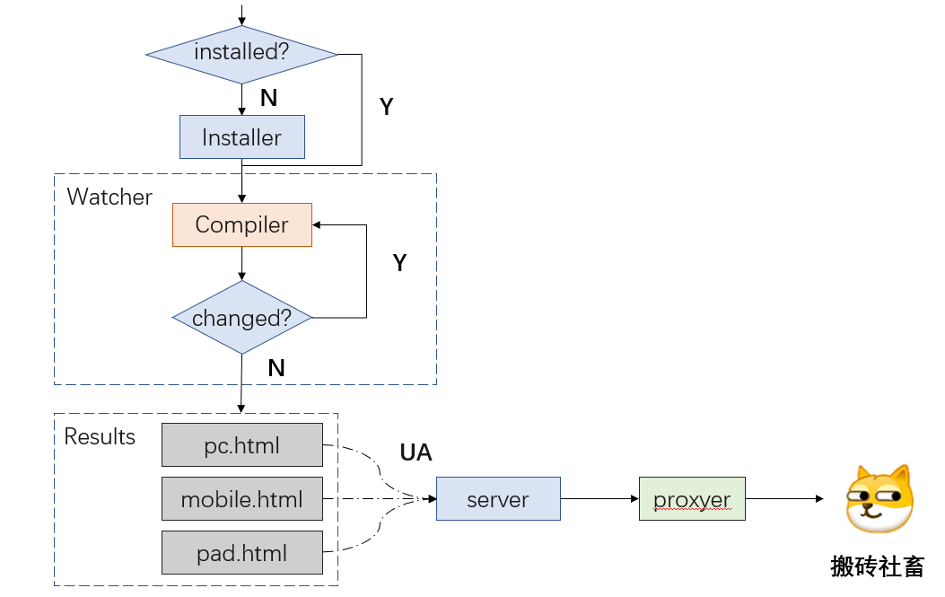
不过,作为是一个复杂的系统,第一次使用,总需要初始化的吧,如果编译系统的依赖尚未安装,没有鸡,怎么生蛋呢?
其实不然,笔者不妨在整套编译系统的外层套个娃,做前端开发,node 总会先安装的吧?那么,在执行正在的编译命令之前,笔者执行一个只依赖于 node 的脚本,这个脚本会尝试执行主要命令,如果主命令直接 crash,说明安装环境尚未准备完毕,那么这个时候,对编译系统进行初始化就 ok 了。如此,就真的可以做到一键开发了。
const cmd = "启动编译的命令";const main = (extraArg) =>childProcess.execSync(`${cmd} ${extraArg}`, {stdio: "inherit",cwd: __dirname,});try {main("");} catch (e) {// 初始化main("after-initialize");}
3.5.编译系统代码化
在这一次的重构过程中,笔者将原本的编译配置改为了由 ts 调用 webpack 的 nodeApi 来执行编译。代码化的编译系统有诸多好处:
使用 api 调用,可以享受 IDE 带来的代码提示,再也不会因为不小心在配置文件里面打了一个 typo 而调试一整天。
使用代码 api,能够更好的实现编译的结构,特别是有多重输出的时候,比起简单的 config 文件组合,更好管理。
使用代码化的编译系统,还有一个特别的作用,编译系统也可以写测试了!啥?编译系统要写测试?事实上,在腾讯文档历次的发布中,经历过数次莫名的 bug,在上线前的测试中,整个程序的表现突然就不正常了。相关代码,并没有任何改动,大家地毯式的排查了很久,才发现编译的结果和以前有微小的不同。
事实上,在系统测试环境生成的前五个小时,一个编译所依赖的插件默默的更新了一个小版本,而笔者在 package.json 中对该插件使用的是默认的^xx.xx,流水线 install 到了最新的版本,导致了 crash。当时笔者得出了一个结论,编译相关的库需要锁定版本。但是,锁定版本并不能真正的解决问题,编译所使用的组件,总有升级的一天,如果保证这个升级不会引起问题呢?这就是自动化测试的范畴了。
如果大家看看 Webpack 的代码,会发现他们也做了很多测试用例来编译的一致性,但是,webpack 的插件五花八门,并不是每一个作者在质量保障上都有足够的投入,因此,用自动化测试保证编译系统的稳定性,也是一个可以深入研究的课题。
4.编译提速
在涉及 typescript 编译的项目中,基本的提速操作,就是异步的类型检查,ts-loader 的 tranpsileOnly 参数和 fork-ts-checker 的组合拳百试不厌。不过,对于复杂的大型项目来说,这一套组合拳的启用过程未必是一帆风顺,不妨随着笔者一起看看,在腾讯文档中,启用快速编译的坎坷之路。
4.1.消失的 enum
在启用 transpileOnly 参数后,编译速度立即有了质的提升,但是,结果并不乐观。编译后,页面还没打开,就 crash 了。根据报错查下去,发现一个从依赖库导入的对象变成了 undefined,从而引起程序崩溃。这个变为 undefined 的对象,是一个 enum,定义如下:
export const enumScope{VAL1= 0,VAL2= 1,}
为什么当笔者启用了 transpileOnly 后它就为空了呢?这和它的特殊属性有关,它不是一个普通的 enum,它是一个 const enum。众所周知,枚举是 ts 的语法糖,每一个枚举,对应了 js 中的一个对象,所以,一个普通的枚举,转化为 js 之后,会变成这样:
tsexport enum Scope {VAL1 = 0,VAL2 = 1,}const a = Scope.VAL1;jsconstScope = {VAL1: 0,VAL2: 1,0: "VAL1",1: "VAL2",};const a = Scope.EDITOR;
如果笔者给 Scope 加上一个 const 关键字呢?它会变成这样:
// tsexport const enumScope{VAL1= 0,VAL2= 1,}const a = Scope.VAL1;// jsconst a = 0;
也就是说,const enum 就和宏是等效的,在翻译成 js 之后,它就不存在了。可是,为何在关闭 transpileOnly 时,编译结果可以正常运行呢?其实,仔细翻看外部库的声明文件.d.ts,就会发现,在这个.d.ts 文件中,Scope 被原封不动的保留了下来。
// .d.tsexport const enumScope{VAL1= 0,VAL2= 1,}
在正常的编译流程下,tsc 会检查.d.ts 文件,并且已经预知了这一个定义,因此,它能够正确的执行宏转换,而对于 transpileOnly 开启的情况下,所有的类型被忽略,由于原本的库模块中已经不存在 Scope 了,所以编译结果无法正常执行(PS:tsc 官方已经表态 transpile 模式下的编译不解析.d.ts 是标准 feature,丢失了 const enum 不属于 bug,所以等待官方支持是无果的)。既然得知了缘由,就可以修复了。四种方案:
方案一,遵循官方指导,对于不导出 const enum,只对内部使用的枚举 const 化,也就是说,需要修改依赖库。当然,腾讯文档本次 crash 所有依赖库确实属于自有的 sdk,但是如果是外部的库引起了该问题呢?所以该方案并不保险。
方案二,完美版,手动解析.d.ts 文件,寻找所有 const enum 并提取定义。但是,transpileOnly 获取的编译加速真是得益于忽略.d.ts 文件,如果笔者再去为了一个 enum 手工解析.d.ts,而.d.ts 文件可能存在复杂的引用链路,是极其耗时的。

方案三,字符串替换,既然 const enum 是宏,那么笔者可以手工通过 string-replace-loader 达到类似效果。不过,字符串替换方式依旧过于暴力,如果使用了类似于 Scope['VAL1']的用法,可能就猝不及防的失效了。

方案四,也是笔者最终所采取的方案,既然定义消失了,重新定义就好,通过 Webpack 的 DefinePlugin,笔者可以重新定义丢失的对象,保证编译的正常解析。
new DefinePlugin({Scope: { VAL1: 0, VAL2: 1 },});
4.2.爱恨交加的 decorator 及依赖注入
很不幸,仅仅是解决了编译对象丢失的问题,代码依旧无法运行。程序在初始化的时候,依旧迷之失败了,经过一番调试,发现,初始化流程有一些微妙的不同。很明显,transpileOnly 开启的情况下,编译的结果发生了变化。
要解决这个问题,就需要对 transpileOnly 模式的实现一探究竟了。transpileOnly 底层是基于 tsc 的 transpileModule 功能来实现的,transpileModule 的作用,是将每一个文件当做独立的个体进行解析,每一个 import 都会被当做一个整体模块来看待,编译器不会再解析模块导出与文件的具体关系,举个例子:
// src/base/a.tsexport class A {}// src/base/b.tsexport class B {}// src/base/index.tsexport * from "./a";export * from "./b";// src/app.tsimport { A } from "./base";const a = new A();
如上是常见的代码写法,我们往往会通过一个 index.ts 导出 base 中的模块,这样,在其他模块中,笔者就不需要引用到文件了。在正常模式下,编辑器解析这段代码,会附带信息,告知 webpack,A 是由 a.ts 导出的,因此,webpack 在打包时,可以根据具体场景将 A、B 打包到不同的文件中。
但是,在 transpileModule 模式下,webpack 所知道的,只有 base 模块导出了 A,但是它并不知道 A 具体是由哪个文件导出的,因此,此时的 webpack 一定会将 A、B 打包到一个文件中,作为一整个模块,提供给 App。对于腾讯文档,这个情况发生了如下变化(模块按照 1、2、3、4、5 的顺序进行加载,模块的视觉大小表示体积大小):
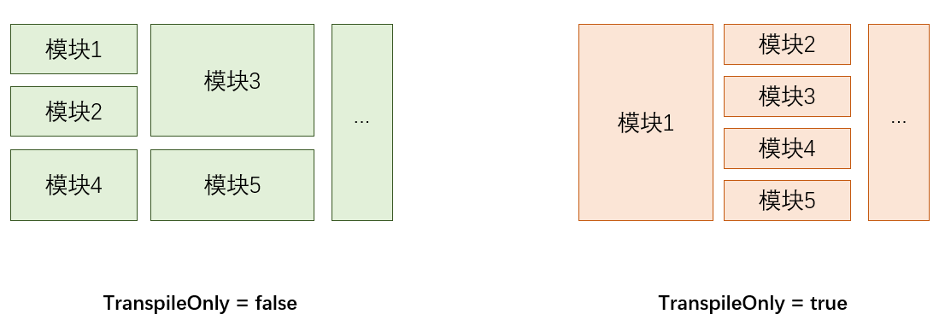
可以看到,在 transpileOnly 开启的情况下,大量的文件被打包到了模块 1 中,被提前加载了。不过,一般情况下,模块被打包到什么位置,并不应该影响代码的表现,不是么?毕竟,关闭 code splitting,代码是可以不拆包的。对于一般的情况而言,这样理解并没有错。但是,对于使用了 decorator 的项目而言,就不适用了。
在代码普遍会转为 es5 的时代,decorator 会被转换为一个__decorator 函数,这个函数,是代码加载时的一个自执行函数。如果代码打包的顺序发生了变化,那么自执行函数的执行顺序也就可能发生了变化。那么,这又如何导致了腾讯文档无法正常启动呢?这,就要从腾讯文档全面引入依赖注入技术开始说起。
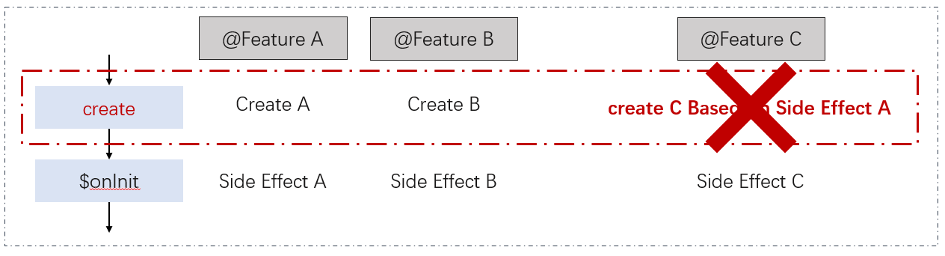
在腾讯文档中,每一个功能都是一个 feature,这个 feature 并不会手动初始化,而是通过一个特殊装饰器,注入到腾讯文档的 DI 框架中,然后,由注入框架进行统一的实例创建。
举个例子,在正常的变一下,由三个 Feature A、B、C,A、B 被编译在模块 1 中,C 被编译到模块 2 中。在模块 1 加载时,workbench 会进行一轮实例创建和初始化,此时,FeatureA 的初始化带来了某个副作用。然后,模块 2 加载了,workbench 再次进行一轮实力创建和初始化,此时 FeatureC 的初始化依赖了 FeatureA 的副作用,但是第一轮初始化已经结束,因此 C 顺利实例化了。
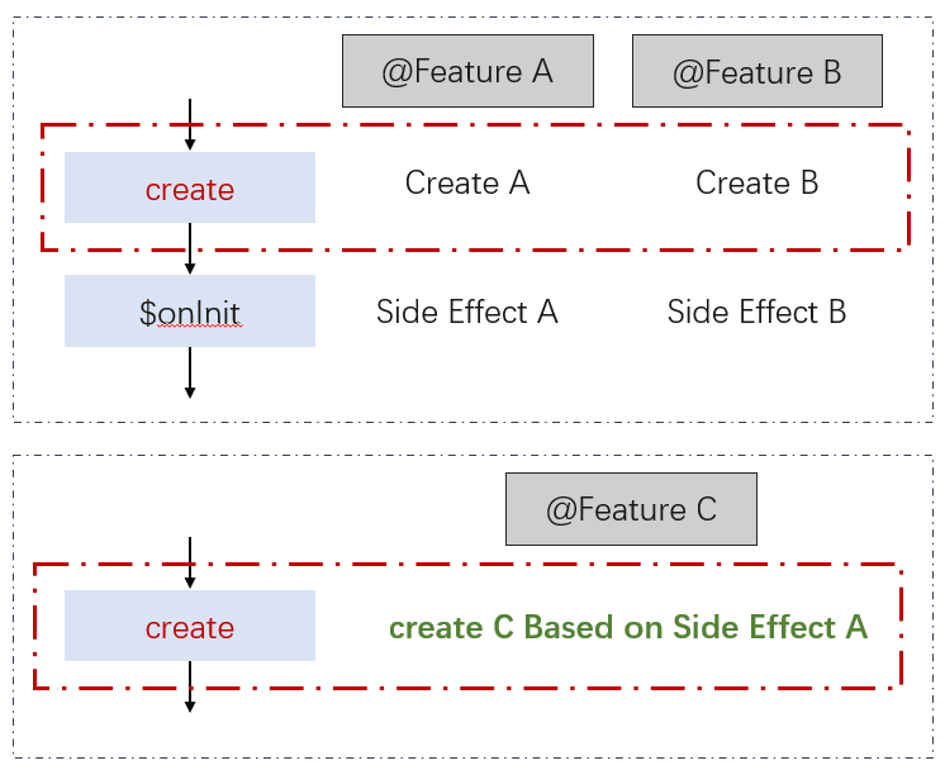
当 transpileOnly 被开启式,一切变了样,由于无法区分导出,Feature A、B、C 被打包到同一个模块了。可想而知,在 Feature C 初始化时,由于副作用尚未发生,C 的初始化就失败了。
既然 transpileOnly 与依赖注入先天不兼容,那笔者就需要想办法修复它。如果,笔者将 app 中的引用进行替换:
// src/app.tsimport { A } from "./base/a";const a = new A();
模块导出的解析问题,是否就迎刃而解了?不过,这么多的代码,改成这样的引用,不但难看,反人类,工作量也很大。因此,让笔者设计一个 plugin/loader 组合在编译时来解决问题吧。在编译的初始阶段,笔者通过一个 plugin,对项目文件进行解析,将其中的 export 提取出来,找到每一个 export 和文件的对应关系,并储存起来(此处,可能大家会担心 IO 读写对性能的影响,考虑到现在开发人均都是高速 SSD,这点 IO 吞吐真的不算什么,实测这个 export 解析<1s),然后在编译过程中,笔者再通过一个自定义的 loader 将对应的 import 语句进行替换,这样,就可以实现在不影响正常写代码的情况下,保持 transpileOnly 解析的有效性了。
经过一番折腾,终于,成功的将腾讯文档在高速编译模式下运行了起来,达到了预定的编译速度。
5.Webpack5 升级之路
5.1.一些兼容问题处理
Webpack5 毕竟属于一次非兼容的大升级,在腾讯文档编译系统重构的过程中,也遇到诸多问题。
5.1.1. SplitChunks 自定义 ChunkGroups 报错
如果你也是 splitChunks 的重度用户,在升级 webpack5 的过程中,你可能会遇到如下警告:

这个警告的说明并不是十分明确,用大白话来说,出现了这个提示,说明你的 chunkGroups 配置中,出现了 module 同时属于 A、B 两组(此处 A、B 是两个 Entrypoint 或者两个异步模块),但是你明确指定了将模块属于 A 的情况。为何此时 Webpack5 会报出警告呢?因为从通常情况来说,module 分属于两个 Entrypoint 或者异步模块,module 应该被提取为公共模块的,如果 module 被归属于 A,那么 B 模块如果单独加载,就无法成功了。
不过,一般来说,出现这样的指定,如果不是配置错误,那就是 A、B 之间已经有明确的加载顺序。但是这个加载顺序,Webpack 并不知道。对于 entrypoint,webpack5 中,允许通过 dependOn 属性,指定 entry 之间的依赖关系。但是对于异步模块,则没有这么遍历的设置。当然,笔者也可以通过自定义插件,在 optimize 之前,对已有的模块依赖关系以及修改,保证 webpack 能够知晓额外的信息:
compiler.hooks.thisCompilation.tap("DependOnPlugin", (compilation) => {compilation.hooks.optimize.tap("DependOnPlugin", () => {forEach(this.dependencies, (parentNames, childName) => {const child = compilation.namedChunkGroups.get(childName);if (child) {parentNames.forEach((parentName) => {const parent = compilation.namedChunkGroups.get(parentName);if (parent && !child.hasParent(parent)) {parent.addChild(child);child.addParent(parent);}});}});});});
5.1.2.plugin 依赖的 api 已删除
Webpack5 发布后,各大主流 plugin 都已经相继适配,大家只要将插件更新到最新版本即可。不过,也有一些插件因为诸多缘由,一些插件并没有及时更新。(PS:目前,没有匹配的插件大多已经比较小众了。)总之,这个问题是比较无解的,不过可以适当等待,应该在近期,大部分插件都会适配 webpack5,事实上 webpack5 也是用了不少改名大法,部分接口进行转移,调用方式发生了改变,倒也没有全部翻天覆地的变化,所以,实在等不及的小插件不妨试试自己 fork 修改一下。
5.2.Module Federation 初体验
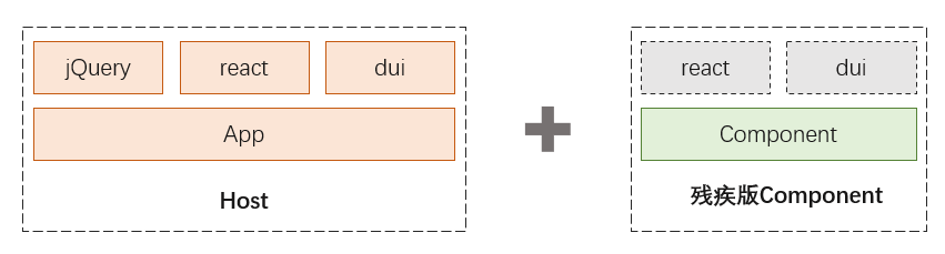
通常,对于一个大型项目来说,笔者会抽取很多公共的组件来提高项目间的模块共享,但是,这些模块之间,难免会有一些共同依赖,比如 React、ReactDOM,JQuery 之类的基础库。这样,就容易造成一个问题,公共组件抽取后,项目体积膨胀了。随着公共组件的增多,项目体积的膨胀变得十分可怕。在传统打包模型上,笔者摸索出了一套简单有效的方法,对于公共组件,笔者使用 external,将这些公共部分抠出来,变成一个残疾的组件。
但是,随着组件的增多,共享组件的 Host 增多,这样的方式带来了一些问题:
Component 需要为 Host 专门打包,它不是一个可以独立运行的组件,每一个运行该 Component 的 Host 必须携带完整的运行时,否则 Component 就需要为不同的 Host 打出不同的残疾包。
Component 与 Component 之间如果存在较大的共享模块,无法通过 external 解决。
这个时候,Module Federation 出现了,它是 Webpack 从静态打包到完整运行时的一个转变,Module Federation 中,提出了 Host 和 Remote 的概念。Remote 中的内容可以被 Host 消费,而在这个消费过程中,可以通过 webpack 的动态加载运行时,只加载其中需要的部分,对于已经存在的部分,则不作二次加载。(下图中,由于 host 中已经包含了 jQuery、react 和 dui,Webpack 的运行时将只加载 Remote1 中的 Component1 和 Remote2 中的 Component2。)
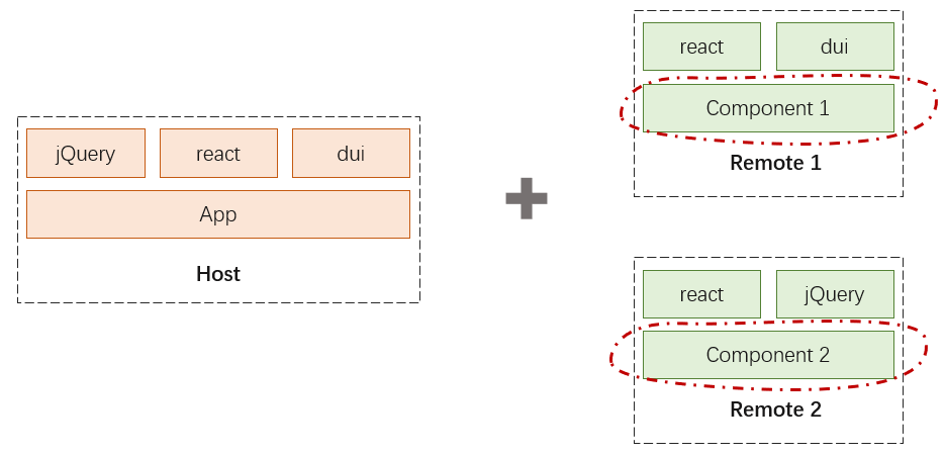
也就是说,公共组件作为一个 Remote,它包含了完整的运行时,Host 无需知道需要准备什么样的运行时才可以运行 Remote,但是 Webpack 的加载器保证了共享的代码不作加载。如此一来,就避免了传统 external 打包模式下的诸多问题。事实上,一个组件可以同时是 Host 和 Remote,也就是说,一个程序既可以作为主程运行,也可以作为一个在线的 sdk 仓库。关于 Module Federation 的实现原理,此处不再赘述,大家感兴趣可以参考《探索 webpack5 新特性 Module federation 在腾讯文档的应用》中的解析,也可以多多参考 module-federation-examples 这个仓库中的实例。
Webpack5 的 Module Federation 是依赖于其动态加载机制的,因此,在它的演示实例中,你都可以看到这样的结构:
// bootstrap.jsimport App from "./App";import React from "react";import ReactDOM from "react-dom";ReactDOM.render(<App />, document.getElementById("root"));// index.jsimport("./bootstrap.js");
而 Webpack 的入口配置,都设置在了 index.js 上,这里,是因为所有的依赖都需要动态判定加载,如果不把入口变成一个异步的 chunk,那如何去保障依赖能够按顺序加载内?毕竟实现 Moudle Federation 的核心是 基于 webpack_require 的动态加载系统。
由于 Module Federation 需要多个仓库的联动,它的推进必然是相对漫长的过程。那么笔者是否有必要将现有的项目直接改造为 index-bootstrap 结构呢?事实上,笔者依然可以利用 Webpack 的插件机制,动态实现这一个异步化过程:
private bootstrapEntry(entrypoint: string) {const parsed = path.parse(entrypoint);const bootstrapPath = path.join(parsed.dir, `${parsed.name}_bootstrap${parsed.ext}`);this.virtualModules[bootstrapPath] = `import('./${parsed.name}${parsed.ext}')`;return bootstrapPath;}
在上述的 bootstrapEntry 方法中,笔者基于原本的 entrypoint 文件,创建一个虚拟文件,这个文件的内容就是:
import("./entrypoint.ts");再通过 webpack-virtual-modules 这个插件,在相同目录生成一个虚拟文件,将原本的入口进行替换,就完成了 module-federation 的结构转换。这样,配合一些其他的相应配置,笔者就可以通过一个简单参数开启和关闭 module-federation,把项目变成一个 Webpack5 ready 的结构,当相关项目陆续适配成功,便可以一起欢乐的上线了。
6.后记
对编译的大重构是笔者蓄谋已久的事情,犹记得加入团队之时,第一次接触到编译链路如此复杂的项目,深感自己的项目经历太浅,接触的编译和打包都如此简单,如今亲自操刀才知道,这中间除了许多技术难题,大项目必有的祖传配置也是阻碍项目进步的一大阻力。
Webpack 5 的 Beta 周期很长,所以在 Webpack5 发布之后,兼容问题还真不如预想的那么多,不过 Webpack5 的文档有些坑,如果不是使用 NodeApi 的时候,有类型声明,笔者绝对无法发现官方不少文档的给的参数还是 webpack4 的旧数据,对不上号。于是不得不埋着头调试源代码,寻找正确的配置方式,不过也因此收获良多。
同时 Webpack5 还在持续迭代中,还存在一些 bug,比如 Module Federation 中使用了不恰当的配置,可能会导致奇怪的编译结果,并且不会报错。所以,遇到问题大家要大胆的提 issue。本次重构的经验就暂时说到这儿,如有不当之处,欢迎斧正。
最后,腾讯文档大量招人,如果你也想来研究这么有趣的技术,欢迎加入腾讯文档的大家庭,欢迎联系笔者glendonzli@qq.com。
最后
面试交流群持续开放,分享了近 许多 个面经。
加我微信: DayDay2021,备注面试,拉你进群。
