
麦肯锡:优秀数据科学家的5个特征!
本文约3700字,建议阅读5分钟 本文总结了成为优秀数据科学家的五大关键准则。
1. 使用金字塔原则沟通是成功的钥匙
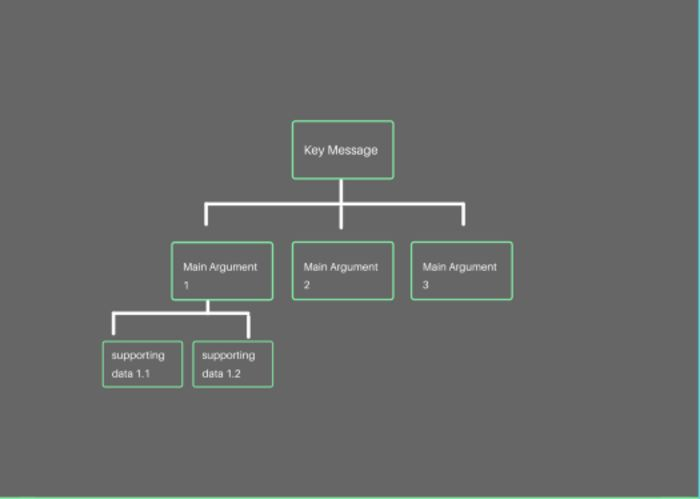
1. 不管你的实际内容有多深奥,使用金字塔原则可以帮助你的听众更好理解你的观点。通常学术论文、或企业报告的开头都会有个摘要,总结整篇文章或材料的中心思想。这样的作法可以确保读者在没办法理解、记住所有文章细节的情况下,也能理解其核心思想。
2. 你是数据的“翻译官”
3. 时刻把解决实际问题放在第一位
4. 有时候可以为了模型的可解释性而适当牺牲模型的准确率。
5. 在开始前,确保自己有个假设场景,但是不要仅局限于一个假设。
原文标题:5 Lessons McKinsey Taught Me That Will Make You A Better Data Scientist
原文链接:https://towardsdatascience.com/5-lessons-mckinsey-taught-me-that-will-make-you-a-better-data-scientist-66cd9cc16aba?gi=2242e432865c
转自:数据派THU 公众号;
整理不易,点赞三连↓
评论