
快手Y-tech:GAN在短视频中的AI特效实践
导读
近年来,以GAN为代表的生成式技术在学术界取得蓬勃发展。在工业界,基于生成式技术的真实感效果也引领了一批爆款特效和应用。快手Y-tech在国内率先将GAN落地于短视频特效制作,并积累了丰富的实践经验,为快手各类人脸爆款特效提供有力技术支持。本文主要介绍快手在高精度人脸属性编辑方面的实践,包括性别、年龄、头发、表情等的生成。
文章来源 快手Ytech 编辑 智东西公开课
背景介绍
人脸特效是辅助短视频内容生产的重要组成部分,生动好玩的特效有利于促进短视频内容的消费。传统的人脸特效主要依赖于人脸二维和三维的语义理解,并结合图形图像处理、优秀的产品设计达到吸引用户的目的,但该特效制作存在真实感缺失的局限。
近些年,生成式技术如VAE、GAN、AutoRegressive Model、Normalizing Flow Model等[1]在学术界取得了蓬勃发展。在这其中,GAN[2]是杰出的代表,GAN通过生成器和判别器的相互博弈,使得生成器生成的数据分布接近真实数据分布。自2014年GAN提出以来,GAN生成效果逐渐逼真和高清,广泛应用于图像翻译、图像修复和增强、图像和视频合成等领域[1]。
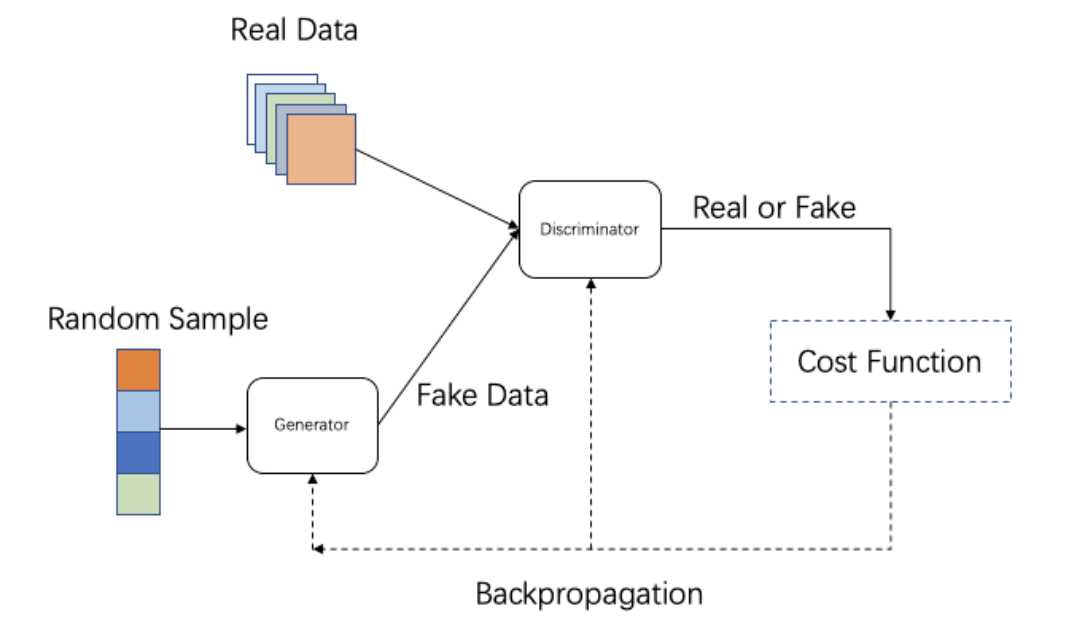
GAN技术对于特效生产具有重要意义。第一,GAN生成效果真实感强、清晰度高,可以做到传统特效无法实现的效果。第二, GAN是端到端的效果输出,可节约特效制作成本。第三,GAN可进一步实现自动化的图片和视频生产,降低短视频生产的门槛。
在工业界,GAN技术造就一批爆款特效和应用,海外如FaceAPP的变老、Snapchat的变性别,在国内,快手是最早将GAN落地于短视频特效制作的公司,本文从高精度人脸属性编辑方面介绍GAN在快手的实践工作,如性别、年龄、头发、表情等的生成和变化。
业务应用
目前,生成式技术在高精度人脸属性方面,主要应用于快手、一甜相机等App的特效模块。
第一,快手魔表。在快手手机端魔表拍摄功能上,我们自2019年8月陆续推出多款魔表,如变小孩、我的一生、变性别、大笑嘟嘴等表情, 给大家带来新奇体验。

变小孩

我的一生

变性别
表情套系
第二,一甜相机的服务端头发自然生长。发型对于人的美感及形象是至关重要的。与脸型和五官适配的发型可以修饰面部的缺陷,提高一个人的气质与魅力。但是,人们往往没办法很快的改变自己的发型,比如自己本身是短发,想看看变成长发是否能为自己的形象气质加分,那就需要等待数月来让头发长长。传统特效采用假发贴片效果很假,侧脸角度容易露怯,利用生成式技术可实现高精度的真实感头发生成。







 (a) 原图 (b) faceapp结果 (c) 快手结果
(a) 原图 (b) faceapp结果 (c) 快手结果
问题分析
在落地实践中, 需要解决如下几个关键问题。
第一,GAN训练不稳定,容易出现斑点、伪影、局部区域扭曲等问题。在落地过程中,我们将GAN模型分为两个阶段,分别为造数据模型和pixel2pixel模型。GAN训练不稳定会导致造数据阶段生成的配对数据失败率高,无法造出大量合格数据提供给后续的pixeltopixel模型,影响了项目的整体进度。
第二,不同落地终端和场景对效果要求不一。
(1)服务端。服务端算力足,可采用离线处理方式,时延要求不高。但服务端上传用户图片清晰度和分辨率不一、光照角度等复杂性高。故服务端方案需要做到高清、鲁棒性好。
(2)手机端。从算力角度看,手机端算力不一,算法需跨越几百块手机到上万块手机性能,需解决低延迟和算力低的矛盾。从拍摄场景看,大部分是近距离、正常光照、小角度自拍。故需设计不同机型的细分方案,保证效果的良好体验。
第三,用户体验决定算法目标和优先级。特效最终服务于用户,拍摄体验决定算法优化方案的目标和优先级,比如头发生长需要考虑头发蓬松度和长度,变老需要考虑真实感和美观度的统一。
技术实践
接下来我们介绍具体落地环节遇到的难点和解决方案。特效生产涉及到数据准备、算法开发、工程部署、素材设计和制作、产品玩法包装、运营推广等各方面,参与环节多,需整体考虑各环节对用户体验影响。
第一,数据准备。在实践过程中,我们无法收集到合理的配对数据,比如一个人从小到老的相同pose下的图片,同一个男性变成女性的照片,大部分人脸属性的变化只能收集到非配对的数据。数据收集的质量、多样性、数量影响了最终的效果。以头发生成为例, 收集头发图片的清晰度和美感等质量决定生成效果的理论上限。用户头发的长度、颜色、走向、厚薄、弯曲程度等都不一样,要求收集数据需涵盖各种发型,否则模型泛化性效果较差。数据的数量也影响了造数据模型的泛化性。在该环节中,需多方联合把控数据的整体质量。作为算法人员,需要关注数据分布情况是否能涵盖实际落地场景,可使用数据扩增、StyleGAN[3]产生的虚拟数据等方式扩充数据的多样性和数量,有效利用数据增强、人工修图等多种方式提升数据质量。
非配对人脸数据收集

非配对头发数据收集
第二, 造数据模型生产效率和成品率提升, 经过人工审核后得到合格配对数据。人脸属性变化本质上是图像翻译的问题,在拿到unpairs数据后, 我们有三种方式生成pairs数据。
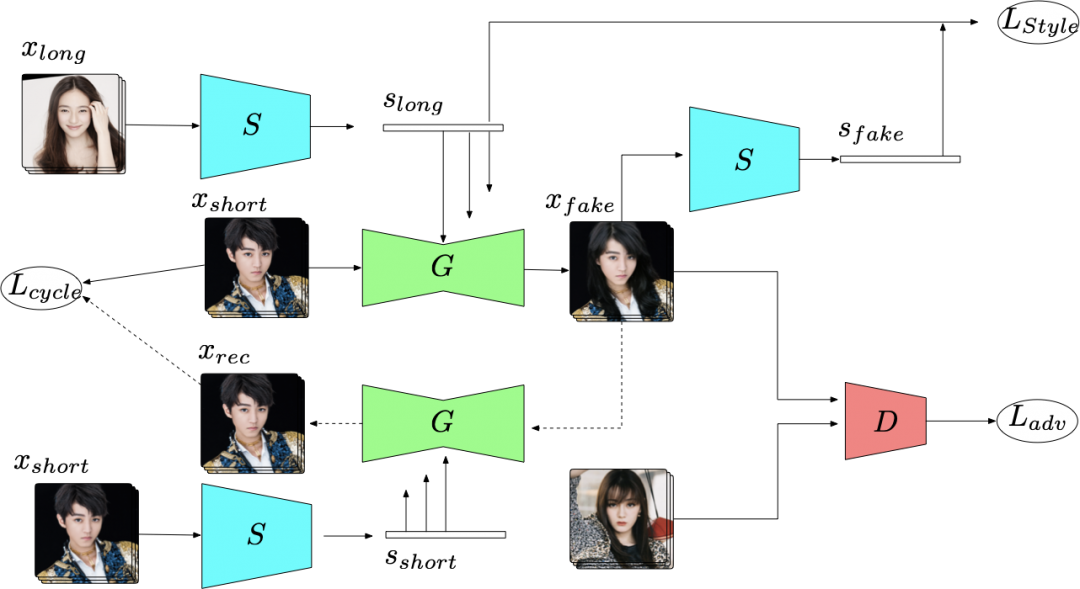
(1)domain translation methods,常见如cyclegan[4]、MUNIT[5]、ugatit[6]、starganV2[7]等,此类技术将数据划分为不同的domain,通过对每个domain设计单独的生成器、单独的style、单独的分支等来实现domain之间的变换,比如可实现性别变换、季节变换等。该方法相对成熟,在实践中,我们针对人脸和头发生成项目做了一系列改进。
在人脸变化上,引入自适应空间注意力机制,让模型更关注变化区域,引入人工筛选得到合格pairs数据,半监督自循环训练模型,提升模型的收敛速度、训练稳定性和成品率。
在固定发型生成上,头发的多样性以及缺乏准确的参数化描述方式使得想要精细控制生成的头发比较困难,但是如果不能精细控制头发的形状、颜色、发丝走向,那么在实时拍摄时生成的头发就会抖动,缺乏真实性。我们提出了相应的解决方案,引入了设计师绘制的3D发型模板,并将3D发型抽象为代表形状的mask、代表发丝走向的edge,通过将这些抽象的信息与真实图像进行融合来达到控制生成头发的目的。在该方案中,我们通过deform操作来改善生成头发与脸部的贴合度,并通过高低频分离的方式将纹理与颜色解耦,从而保证了实时情况下生成头发的纹理与颜色都是稳定的,该方法可以扩展至多种应用,详情可见我们的论文[8]。
在头发自然生长上,我们将头发数据划分为短发和长发两个domain,每个domain有自己的style code,并利用其来控制StyleGAN,从而得到对应domain的输出图像。在该方案中,我们采用了局部-全局优化策略实现了人脸与头发解耦,保证头发生长的同时脸部不发生变化;使用了multi-scale的生成器来得到细致的头发纹理;采用半监督训练提升了数据成品率。
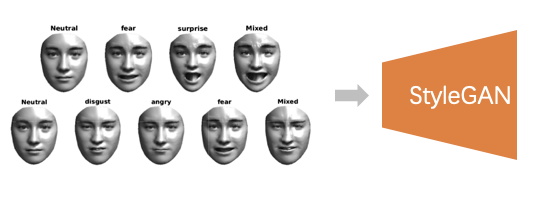
(2)基于StyleGAN的隐变量操控方法,如论文[9-11]通过在stylegan中对隐变量施加相关人脸属性控制,使得生成图片满足指定的属性变化。基于此类方法,我们自研了基于视频的可微分3DMM,更好解耦表情参数和人脸形状参数,并加入StyleGAN隐变量控制中,实现各种表情的生成。
(3)Mask guided methods:这类方法主要有MaskGAN[12],SEAN[13],MichiGAN[14]等,他们的核心是用mask限定了待编辑区域的范围,以SEAN为例,其对一张图像的五官及头发分区域提取style得到style matrix,并将其与各区域的mask作为semantic region-adaptive normalization模块的输入,从而达到分区域控制生成结果的目的。

第三,基于合格的配对数据训练pixel2pixel模型。利用知识蒸馏思想,将unpairs模型转化为pairs模型,模型效果更稳定和鲁棒。为保证模型能在不同算力手机的实时效果,我们做了如下优化。
(1)基于自研的ycnn手机端高效推理引擎,针对不同底层架构如NPU、METAL、DSP、OpenCL、NEON等适配高效网络结构模型。
(2)提升判别器效果:在对抗训练阶段中引入预训练特征以提升判别器对细节纹理的判断能力,同时稳定判别器的训练过程,最终强化模型对细节纹理的生成能力;采用多尺度、全局-局部判别器进一步优化局部清晰度。(3)设计计算高效的逐像素空间注意力机制, 改进生成器网络的浅层和深层特征融合方式,在领域特征变化的同时保留更多原图细节特征。

第四,模型部署和素材制作。素材制作可使用轻量级的操作让模型的最终效果更上一层楼,比如美颜、美型、美妆、锐化、氛围添加等常见操作,提升用户对美的感受。素材操作可以是落地的最后一环,也可以作为造数据模型的必要环节,提升造数据阶段的数据质量。比如,在变小孩造数据阶段引入美型可以降低图像翻译过程中的形变带来的学习困难,提升造数据成功率。
总结
近年来,GAN在人脸属性变化上的研究众多,似乎GAN对于人脸属性的变换和生成是一个已解决的问题,但在实际应用过程中,要想在有限的项目周期内达到极致的用户体验还有很多技术挑战。在算法方面,我们持续研发基于少量数据的StyleGAN属性操控方案,进一步缩短算法研发周期。在用户体验方面,我们使用超分、美颜、多模型融合等方法提升数据质量,使用合理的数据扩增和训练方式提升低画质生成效果。在有限算力和内存情况下,我们紧密结合工程和模型设计,提升低算力设备的性能和效果体验。未来, 这些方面都需要我们紧跟学术发展,持续的创新和认真细致的努力, 创作更优质和有吸引力的短视频内容。
引用
猜您喜欢:
附下载 |《TensorFlow 2.0 深度学习算法实战》