
Python3 源代码 | 抓取任意小红书话题笔记,并下载高清无水印图片
欢迎关注公众号「月小水长」,唯一笔者是 BuyiXiao,又名小布衣、肖不已。
BuyiXiao,何许人也?本衡州一乡野村夫,身高八尺不足,年方二十有余;弱冠之年曾求学于潭州,为谋生计,背井离乡,远赴京畿,我本南人,不习北土,兼有故友,威逼利诱,急于星火,遂下岭南,打工未半,中道创业,所为何业?赛博朋克,智能硬件;假工程师之名,行农民工之实,满腹经纶,无用书生,善于自黑,贻笑大方。
笔者水平有限,可能暂时无法将非常干货的教程讲的不拖泥带水又不哗众取宠,公众号文章诸多遗漏或不妥之处,可以加月小水长微信「2391527690」备注「学校专业/研究方向/工作岗位」进行交流。
另外,文末点下「赞」和「在看」,这样每次新文章推送,就会第一时间出现在你的订阅号列表里。
在一个小红书笔记的底部,通常会有类似 #蔚来 这样的 hashtag,用来将本条帖子纳入蔚来这个话题,而今天要说的代码,就是小红书话题爬虫。
在 app 里点开#蔚来,会进入到话题合集页
将这个页面复制分享地址(页面右上角)后在浏览器打开,会重定向到如下的地址:
https://www.xiaohongshu.com/page/topics/5bfd5dcb0af6350001652788?fullscreen=true&naviHidden=yes&xhsshare=CopyLink
其中的 5bfd5dcb0af6350001652788 就是这个话题的唯一 id。今天发布的这个话题爬虫,就是根据这个话题 id 开始抓取的。
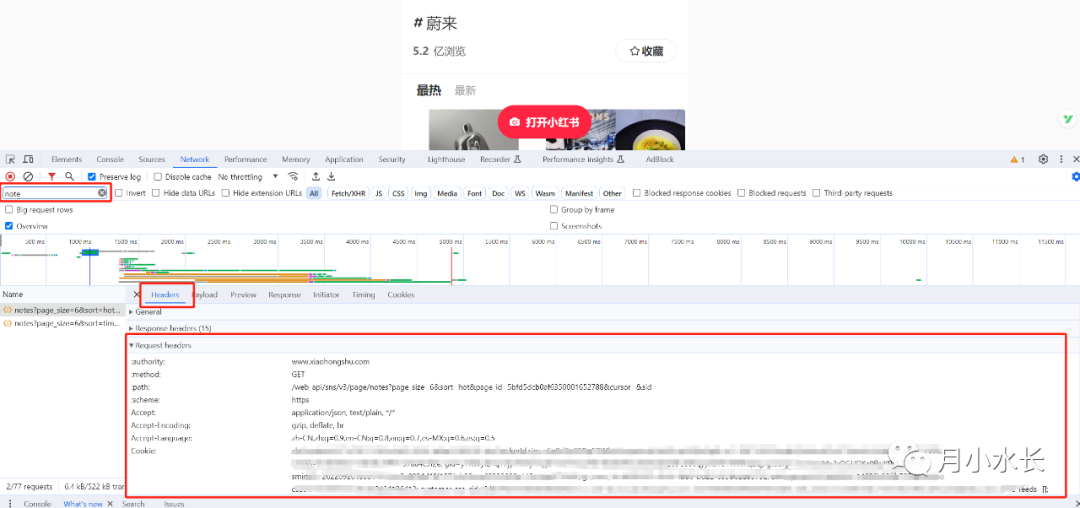
在浏览器按 f12,刷新页面,抓包 /v3/page/notes 请求(如下图红框输入 note 即可),复制这个请求的 headers。
有了 headers 和想要抓取的话题 id 后,就可以利用下面这份代码开始抓取话题下的笔记了,抓取结果保存在 csv 文件中,字段信息包括笔记的 ID、发布时间、标题、点赞数、收藏数、高清图片链接列表和作者昵称和主页链接等,每次追加写入,自动按照笔记 ID 去重。
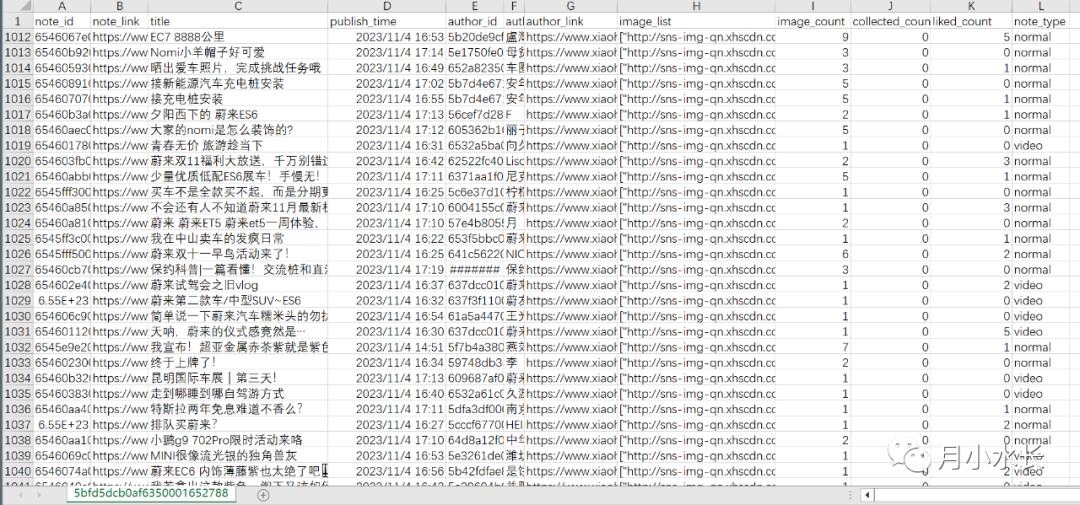
实测一次最多可以抓取几百条到1千条,但是代码可追加去重,不用担心多次运行后有重复数据。而且可以设定参数来抓取最新的话题笔记。
params = {
'page_size': '6',
'sort': 'hot', # time 时间排序,hot 热度排序
'page_id': f'{topic_id}',
'cursor': '',
'sid': '',
}
比较推荐的方法是,第一次抓取某个话题的笔记时,sort参数设置成hot,之后再设置成 time就行。
在一个话题抓完后,运行下载高清无水印图片的代码,可以将刚才抓取到的笔记 csv 里面的高清无水印图片下载到本地,无论运行多少次下载图片,同一张图片只会被下载一次不会重复下载,下次直接快速跳过。
本次的代码包括话题笔记抓取和笔记高清无水印图片下载两个功能,一共 3 个 Python3 文件,全部放在我的面包多~,地址如下:
https://mbd.pub/o/bread/ZZaUk5xw
点击下方阅读原文直达该地址~