
知乎有很多好玩的微信8.0状态视频,用Python一键下载
于是我就想把这些视频下载下来,也玩一玩。本文讲述如何使用 Python 一键下载知乎某个回答下的所有视频。
思路:分析知乎回答页面 -> 定位视频 -> 寻找视频播放的 url -> 下载。其实就两步:找到 url,然后下载。
寻找 url
一个回答下面可能有多个视频,先分析一个视频,打开谷歌浏览器的开发者工具窗口,找到 network,勾选 preserve log、disable cache,选择 xhr,刷新,很容易找到如下图所示的接口:
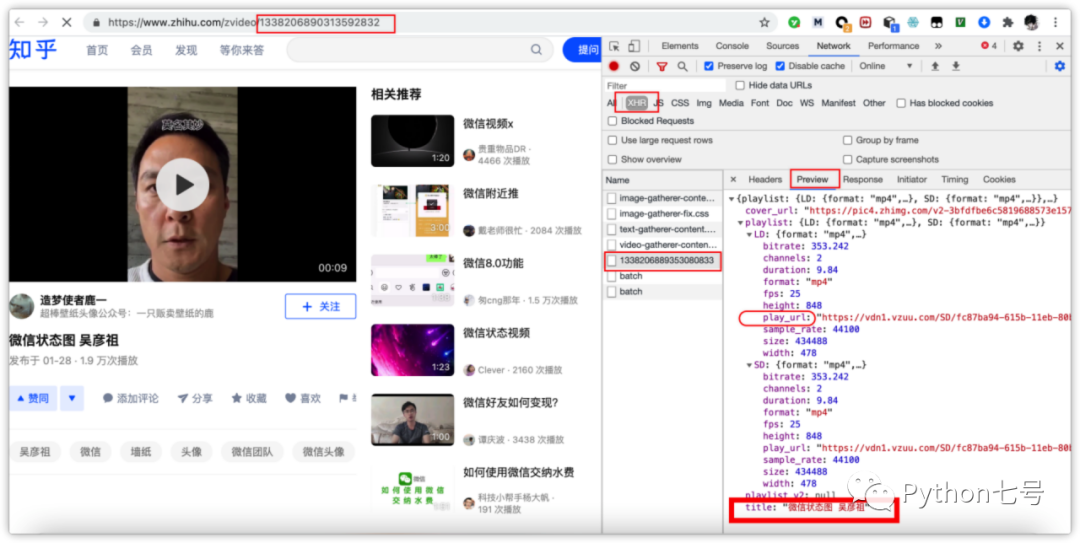
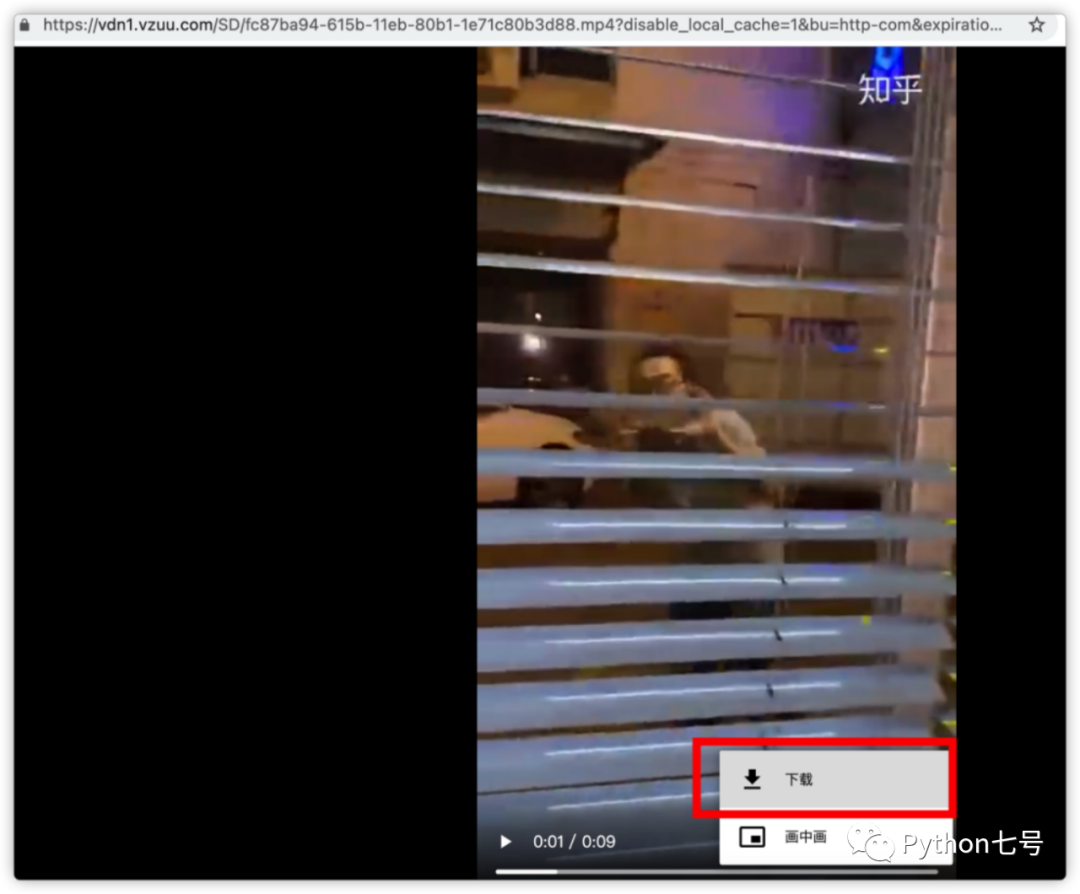
从上图接口返回的数据就可以获取视频播放的 url、标题、格式等信息,这就够了,复制 play_url,放在浏览器上看一下,发现可以直接下载,说明那么这个 url 就是我们需要的。
接下来,写代码,获取接口返回的数据:
def get(url: str) -> list:
"""
获取知乎视频的 url
返回格式
[{'url':'', 'title','format':'',},{}]
"""
data = []
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
}
with requests.get(url, headers=headers, timeout=10) as rep:
if rep.status_code == 200:
ids = re.findall(r"www.zhihu.com/zvideo/(\d{1,})", rep.text)
ids = list(set(ids)) # 去掉重复元素
else:
print(f"网络连接失败,状态码 { rep.status_code }")
return []
if not ids:
print("视频获取失败,可能是这个页面没有视频")
return []
for id in ids:
print(id)
with requests.get(
f"https://www.zhihu.com/api/v4/zvideos/{id}/card",
headers=headers,
timeout=10,
) as rep:
if rep.status_code == 200:
ret_data = rep.json()
playlist = ret_data["video"]["playlist"]
title = ret_data.get("title")
temp = playlist.get("ld") or playlist.get("sd")
if temp:
sigle_video = {}
sigle_video["url"] = temp.get("play_url")
sigle_video["title"] = title
sigle_video["format"] = temp.get("format")
data.append(sigle_video)
else:
print(f"网络连接失败,状态码 { rep.status_code }")
return []
return data
下载视频
这个比较简单了,直接请求视频播放的 url,将流式的内容保存到文件中,最多再加个进度条的展示。部分视频获取的 title 为空,这时就使用时间戳来命名文件。
请看代码:
def download( file_url, file_name=None, file_type=None, save_path="download", headers=None, timeout=15,):
"""
:param file_url: 下载资源链接
:param file_name: 保存文件名,默认为当前日期时间
:param file_type: 文件类型(扩展名)
:param save_path: 保存路径,默认为download,后面不要"/"
:param headers: http请求头
"""
if file_name is None or file_name == "":
file_name = str(datetime.now())
if file_type is None:
if "." in file_url:
file_type = file_url.split(".")[-1]
else:
file_type = "uknown"
file_name = file_name + "." + file_type
if headers is None:
headers = {
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B137 Safari/601.1"
}
if os.path.exists(save_path):
pass
else:
os.mkdir(save_path)
# 下载提示
if os.path.exists(f"{save_path}/{file_name}"):
print(f"\033[33m{file_name}已存在,不再下载!\033[0m")
return True
print(f"Downloading {file_name}")
try:
with requests.get(
file_url, headers=headers, stream=True, timeout=timeout
) as rep:
file_size = int(rep.headers["Content-Length"])
if rep.status_code != 200:
print("\033[31m下载失败\033[0m")
return False
label = "{:.2f}MB".format(file_size / (1024 * 1024))
with click.progressbar(length=file_size, label=label) as progressbar:
with open(f"{save_path}/{file_name}", "wb") as f:
for chunk in rep.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
progressbar.update(1024)
print(f"\033[32m{file_name}下载成功\033[0m")
except Exception as e:
print("下载失败: ", e)
return True
执行代码下载:
import os, sys
import re
import click
import requests
from datetime import datetime
def get(url: str) -> list:
#见上文
...
def download( file_url, file_name=None, file_type=None, save_path="download", headers=None, timeout=15,):
#见上文
...
if __name__ == "__main__":
videos = get(sys.argv[1])
for video in videos:
download(file_url = video['url'],file_name= video['title'] ,file_type= video['format'],save_path='./download')
执行结果如下图所示:
最后的话
网站可能会发生变更,因此本文的代码可能随着时间变化而无法使用,请自行调节一些正则表达式和参数。爬取的思路是通用的,无非就是找到视频的流式数据,进行保存。思路有了,编写代码就是体力活了。
此外,如果你只是想要一些酷炫、搞笑、可爱的视频资源,玩一下微信 8.0 的状态,请在公众号「Python七号」回复「视频」,即可获取微信 8.0 的状态视频合集的下载链接:
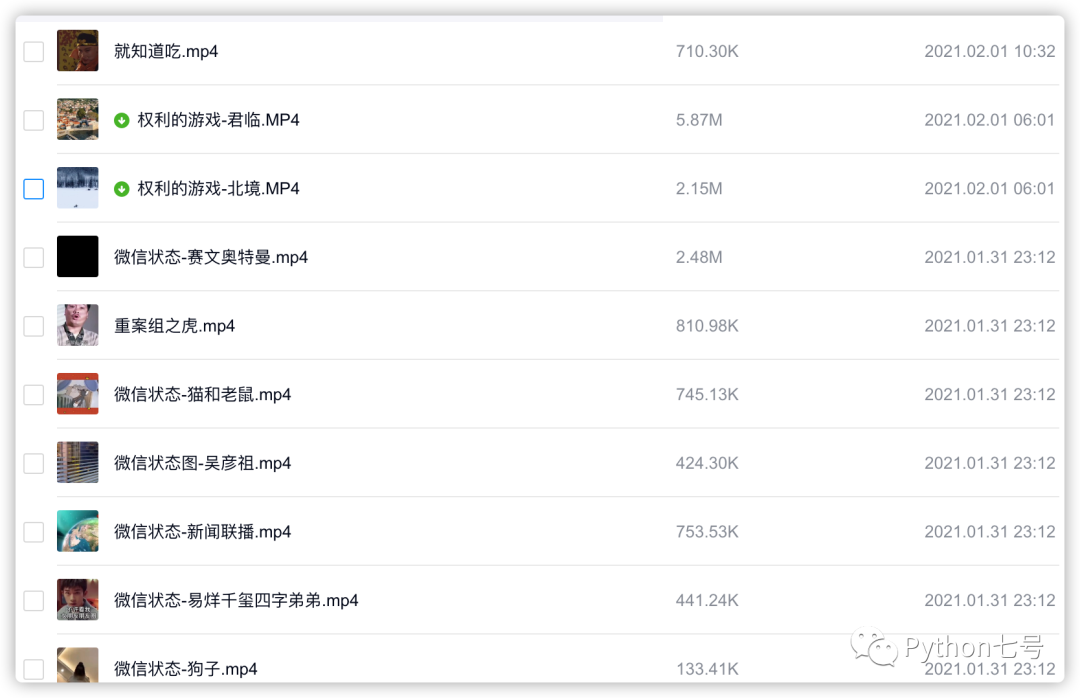
该关键词不定期更新一些有趣好玩的视频。后面会更新其他网站用Python 爬取视频的方法,敬请关注「Python七号」,设为星标,第一时间接收更新。
资料
有没有微信8.0状态沙雕又可爱的视频或图片?: https://www.zhihu.com/question/441253090
留言讨论
评论