
你在享受十一长假时,Python 已悄悄地变了

文 | 太阳雪
来源:Python 技术「ID: pythonall」

Python 3.9 在经历了将近一年的试用期后,于 10月5日(2020年)发布了稳定版,意味着,在下一版本发布之前,不会在做改动,童鞋们可以放心大胆地更新了。享受完惬意的十一长假后,我们快来看看新版本带来了哪些惊喜
先附上一个 16 岁印度小哥哥整理的特性图:
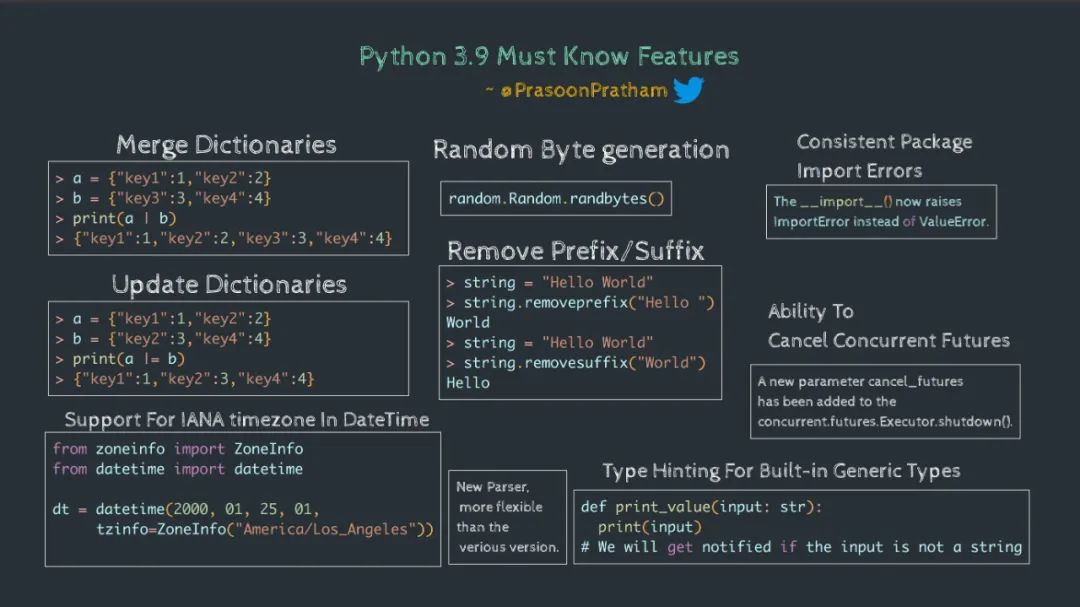
节能篇
这次版本最喜人的特性事节能,不仅节省电能,更重要的是节省了敲代码的次数,以及我们宝贵的时间
字典的合并与更新
毫无疑问,字典对象(Dict)是日常编程中最常用到的数据结构,从存储键值对到支持复杂算法,都依赖于字典对象,而且常用一些字段的合并、更新等操作,虽然 Python 中已经提供了字段更新的方法和字典展开操作符( ** ),但是仍然不够简洁,我理解,在你看到新版本中的更新之前,不会感觉有什么不简洁的
原来的合并:
d1 = {'a': 'A', 'b': 'B', 'c': 'C'}
d2 = {'d': 'D', 'e': 'E'}
d3 = {**d1, **d2} # 使用展开操作符,将合并结果存入 d3
print(d3) # {'a': 'A', 'b': 'B', 'c': 'C', 'd': 'D', 'e': 'E'}
d1.update(d2) # update 方法,将 d1 d2 合并,且更新 d1
print(d1) # {'a': 'A', 'b': 'B', 'c': 'C', 'd': 'D', 'e': 'E'}
现在的合并:
d1 = {'a': 'A', 'b': 'B', 'c': 'C'}
d2 = {'d': 'D', 'e': 'E'}
d3 = d1 | d2 # 效果等同于展开操作符
print(d3) # {'a': 'A', 'b': 'B', 'c': 'C', 'd': 'D', 'e': 'E'}
d1 |= d2 # 等同于 update
print(d1) # {'a': 'A', 'b': 'B', 'c': 'C', 'd': 'D', 'e': 'E'}
|操作符,除了对数值的与操作之外,现在还可以做字典对象的合并|=如果要用合并的结果更新前面的字典对象,在合并操作符后加赋值号就行
是不是简洁多了,不仅简洁了,而且更容易理解了
这还没完,合并赋值操作符(|=)除了字典之间的合并,还可以合并类字典对象
先看一段代码:
d1 = {'a': 'A', 'b': 'B', 'c': 'C'}
l1 = [('d', 'D'), ('e', 'E')]
d1 |= l1
print(d1) # {'a': 'A', 'b': 'B', 'c': 'C', 'd': 'D', 'e': 'E'}
l1 是一个列表对象,其中的元素是二维元组 这里的特别之处在于二维元组对象,合并时,第一个元素被看成字典的 Key,第二个被看成字典的 Value,如果不是这样,则会报错
如果遇到这种特殊的场景,合并运算简直太方便了,你能想到有哪些类似场景吗?欢迎留言
拓扑排序
首先需要理解什么是拓扑图,简单来说就是一定空间内若干个点之间的关系,例如对于一项工作来说,包含有若干个任务,任务之间有相互依赖的关系,任务加上它们之间的关系,就构成了一个拓扑结构图
拓扑排序,就是对一个拓扑图中的点按照点之间的相互关系的一种排序
例如这样一个拓扑图
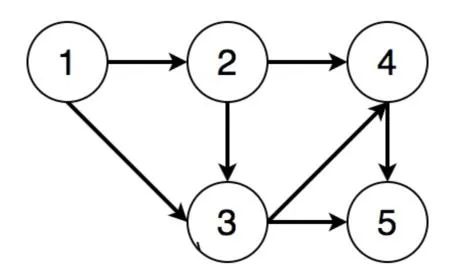
拓扑排序为
1、2、3、4、5
如果用算法生写的话,需要十行以上,而且还不包括调试时间,以及为各种适应性做的改善所花的时间
现在,排序只需要一行代码:
from graphlib import TopologicalSorter
tg = {5: {3, 4}, 4: {2, 3}, 3: {2, 1}, 2: {1}}
ts = TopologicalSorter(tg)
print(list(ts.static_order())) # [1, 2, 3, 4, 5]
首先从 graphlib 中引入拓扑排序组件 TopologicalSorter 然后定义一个拓扑结构图,这里是用字典加集合的方式定义的,表示节点的前序节点是哪些 接着用排序组件对拓扑结构进行排序,即创建一个排序对象 最好调用排序对象的 static_order方法展示排序结果
实际上最核心的就是创建排序对象的代码,新特性提供了优雅的封装
说到封装,你可能猜到他的功能并不单一,确实,排序组件 TopologicalSorter 不仅能对以及定义的结果排序,还可以对动态结构排序,例如
from graphlib import TopologicalSorter
ts = TopologicalSorter()
ts.add(5, 3, 4)
ts.add(4, 2, 3)
ts.add(3, 2, 1)
ts.add(2, 1)
print(list(ts.static_order())) # [1, 2, 3, 4, 5]
也就是说,可以逐步的将依赖添加进去,在迭代处理的情况下很方便,
需要注意的是 static_order 方法只能掉用一次,再次排序的话,需要重新创建 TopologicalSorter 对象
另外,如果拓扑图结构是个循环的,排序会报 CycleError 循环依赖错误
随机字节码
之前要产生随机字节码,需要先产生随机数,然后从定义的字符序列中获取对应位置的字符,最好再转换为字节,是挺麻烦的,现在,一行代码搞定
import random
print(random.randbytes(10)) # b'\x0fzf\x17K\x00\xfb\x11LF' 随机的,每次结果可能不同
最小公倍数
之前的 Python 版本中已经实现了最大公约数的计算,虽然可以用最大公约数求得最小公倍数,不过需要写多行代码(实际上我不记得怎么推送了)
现在,一行代码搞定:
import math
math.lcm(49, 14) # 98
是不是方便多了,不信的话,和下面生算对比下:
def lcm(num1, num2):
if num1 == num2 == 0:
return 0
return num1 * num2 // math.gcd(num1, num2)
lcm(49, 14) # 98
功能篇
功能方面,Python 3.9 也做出了很多改善,下面来了解下
字符串去前缀后缀
本来字符串在 Python 中的操作已经够强大了,很难想到它会把去前后缀的功能作为更新,先看看效果吧
"three cool features in Python".removesuffix(" Python")
# three cool features in
"three cool features in Python".removeprefix("three ")
# cool features in Python
"three cool features in Python".removeprefix("Something else")
# three cool features in Python
很简单,很容易想到用其他方式实现,代码也不会多,例如用 字符串的 strip 方法:
"three cool features in Python".strip(" Python")
# ree cool features i
很明显,最终的效果并不是我们想要的,strip 会将前后遇到的字符模式一并修剪!
如果用其他方式,比如字符串查找,正则匹配等,也能实现,不过没有现成的方法方便,更重要的是,这个特性避免了自己不小心的犯错
时区支持
对我们中国来说,时区问题不大,特别是只做在国内使用的应用的话,但是如果在每个,或者其他地方,时区会是个问题,之前,可以通过将时间转换为 UTC 格式再转为其他时区的时间,现在可以方便的用 zoneinfo 模块实现了
zoneinfo 模块为标准库引入了 IANA 时区数据库
from zoneinfo import ZoneInfo
from datetime import datetime
dt = datetime(2020, 10, 1, 1, tzinfo= ZoneInfo("America/Los_Angeles"))
如代码所示,可以为本地时间设置时区,将时间转化为指定时区的时间
注意:使用 ZoneInfo 获取时区属性之前,需要安装 tzdata 模块
其他
数据类型提示
Python 本身是弱类型语言,但在一些大型项目中容易因为数据类型引入 bug,为了改善这一点,对声明了数据类型的形参,如果实参与形参类型不符,执行时会得到警告提醒,例如
def fun(input: str):
print(str)
fun(10) # 此时会得到数据类型不匹配的警告
更强悍的解析器
Python 3.9 重构了解析器,虽然在日常编程中几乎感觉不到,但这个更新确是最重要的,就行如果你感觉如履平地,必然有人在默默付出一样
Python 之前一直使用 LL(1) 解析器将源代码解析为解析树,类似于一次读取一个字符,并解释源代码而无需回溯的解析器。
新解释器是基于 PEG(parsing expression grammar) 实现的,既高效,又灵活,不过需要使用更多的内存
import()特性修改
__import__() 在之前的版本中,可能引发 ValueError 异常,按官方解释:ValueError 曾经会在相对导入超出其最高层级包时发生 (不知所云),在新的版本中,异常时会抛出 ImportError,这样更加合理
反正我没遇到过,可能是没有用过这种高级用法,就当是学习了
总结
“人生苦短,用我 Python” —— Python 不但这么说,也这么做,当我们享受惬意的双节长假时,Python 默默的优化自己,只能让我们苦短的人生,更加精彩
还等什么,赶紧升级到 Python3.9 试试吧
参考
https://zhuanlan.zhihu.com/p/262914368 https://developer.51cto.com/art/202010/627903.htm https://blog.csdn.net/qq_42554007/article/details/107075651 https://www.sohu.com/a/422827870_114760 https://docs.python.org/zh-cn/3/whatsnew/3.9.html
PS:公号内回复「Python」即可进入Python 新手学习交流群,一起 100 天计划!
老规矩,兄弟们还记得么,右下角的 “在看” 点一下,如果感觉文章内容不错的话,记得分享朋友圈让更多的人知道!


【代码获取方式】