
TCP为什么可靠?
目录
前言
实现一个可靠的协议?
滑动窗口
顺序、丢包问题
确认和重发机制
流量控制
拥塞控制
前言
上一篇记录了TCP三次握手四次挥手的细节以及为什么会在TIME_WAIT状态停留时间为2MSL。
一直说TCP是可靠的协议,那么它靠什么成为一个可靠的传输协议?
实现一个可靠的协议?
顺序性: 每个包都有一个序号,在建立连接时,双方确定起始序号,然后按需发送
不丢包: 对于发送的包都要进行应答,但不是发一个应答一个,而是应答某一个,而这个序号之前的包,表示都收到了,这种模式成为累计确认或者累计应答
滑动窗口
TCP使用的被称为滑动窗口协议的另一种形式的流量控制方法,该协议允许发送方在停止并等待确认前可以连续发送多个分组。
由于发送方不必每发一个分组就停下来等待确认,因此该协议可以加速数据的传输。
为记录所有发送和接收的包,TCP需要发送端和接收端分别都有缓存来保存这些记录
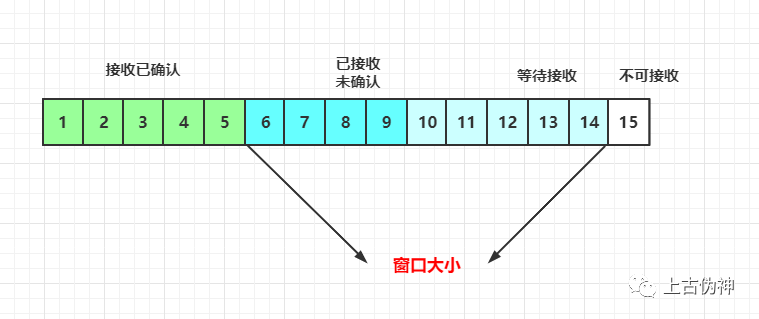
发送端的缓存里时按照包的序号一个个排列,按照处理情况分为四个部分:
(1)发送并已确认 (2)发送但未确认 (3)没发送但等发送 (4)没发送但暂不发送
滑动窗口的大小是由接收端提供的,也即是上述 【 第二点 + 第三点 】,超过这个大小,接收端处理不过来
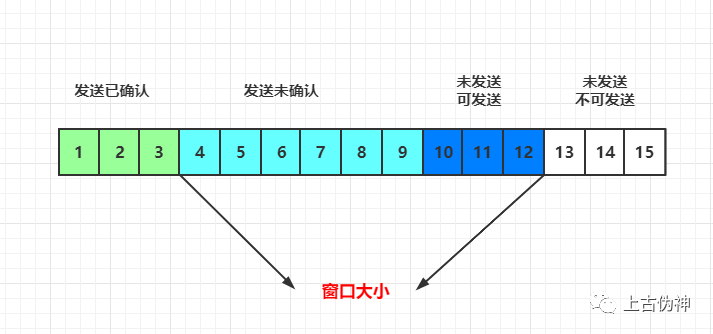
对接收端来说,缓存里记录的内容如下:
(1)接收并已确认 (2)已接收但未确认 (3)等待接收的 (4)不能接收的,超过窗口大小
书中例子:
数据传输过程中滑动窗口的变化
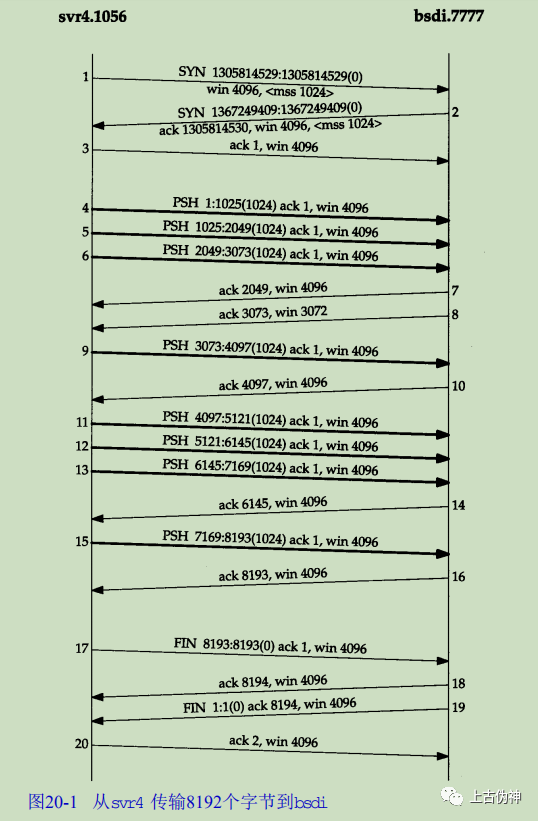
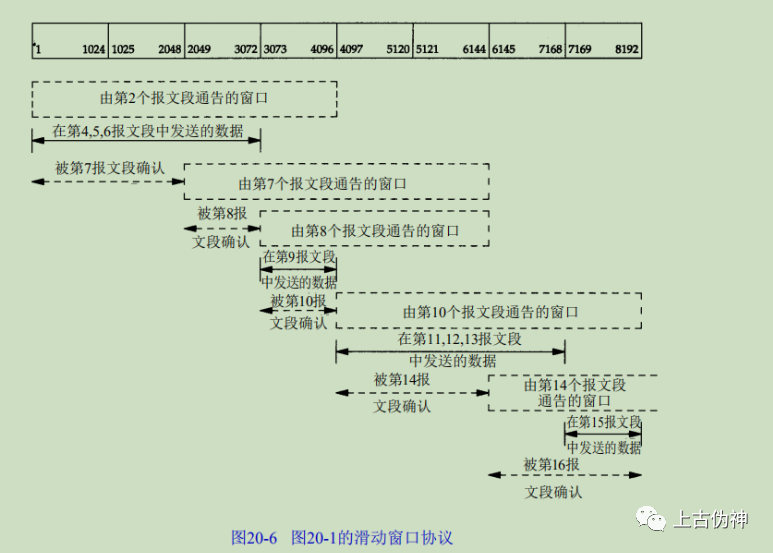
顺序、丢包问题
发送端:
接收端:
分析如下:
(1)包1、2、3双方都达成了一致
(2)包4、5接收方确认了,但是发送方还没收到接收方的确认,有可能丢了或者在路上
(3)包6、7、8、9已经发送,但是包8、9已经到接收端,包6、7没到,此时会出现乱序,所以包8、9只能放在缓存中,不能进行ACK。
确认和重发机制
超时重传
对每一个发送了但是没有确认的包,都设定一个定时器,超过定时,就重新尝试。
超时时间不宜过短,必须大于往返时间RTT,否则会有不必要的重传
估计往返时间,需要TCP通过采样RTT的时间,然后进行加权平均,算出一个值,而且这个值是不断变化的,因为网络状况在不断的变化,除了采用RTT,还要采用RTT的波动范围,计算出一个估计的超时时间。由于重传时间是不断变化的,称为自适应重传算法。
TCP的策略是超时间隔加倍,每当遇到依次超时重传的时候,都会将下一次超时时间间隔设为先前值的两倍,两次超时,说明网络环境差,不宜频繁反复发送。
快速重传:
当接收方收到一个序号大于下一个所期望的报文段时,就会检测到数据流中的一个间隔,于是它就会发送冗余的 ACK,冗余 ACK 的是期望接收的报文段。而当客户端收到三个冗余的 ACK 后,就会在定时器过期之前,重传丢失的报文段。
例如:接收方发现 6 收到了,8 也收到了,但是 7 还没来,那肯定是丢了,于是发送 6 的 ACK,要求下一个是 7。接下来,收到后续的包,仍然发送 6 的 ACK,要求下一个是 7。当发送端收到 3 个重复 ACK,就会发现 7 的确丢了,不等超时,马上重发。
流量控制
在对包的确认中,同时会携带一个窗口的大小
发送端发送的每一个数据包,服务端都要给一个确认包(ACK),确认它收到了。
服务端给发送端发送的确认包(ACK包)中,同时会携带一个窗口的大小,
此窗口大小就代表目前服务器端的处理能力(接收端最大缓存量 - 接收端已确认但未被应用层读取的部分)
此窗口大小也是时刻变化的,可能接收方在发送数据包4的ACK时候,窗口大小为9,此时应用层程序已经读取确认了缓存4个数据的,接收方再发送数据包5的ACK的时候,窗口的大小就变为14
例如:窗口不变,始终为9
初始情况:
注意:点点框起来的是窗口
发送端:
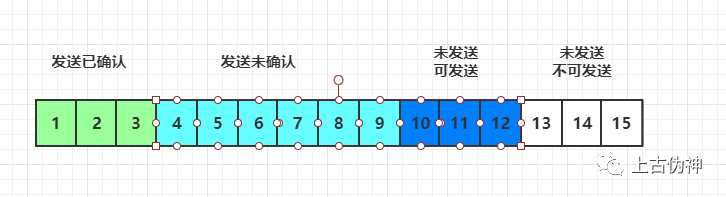
当收到ACK4时,窗口右移,此时第13个包也可以发送
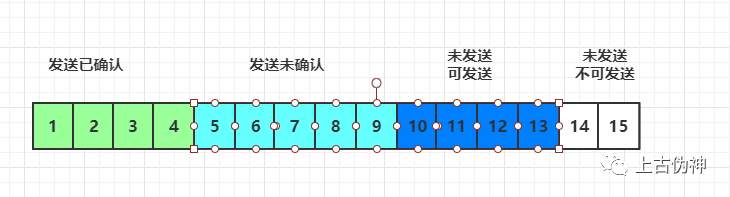
此时发送端发送较快,将包10、11、12、13 全部发送,此时未发送可发送部分为0
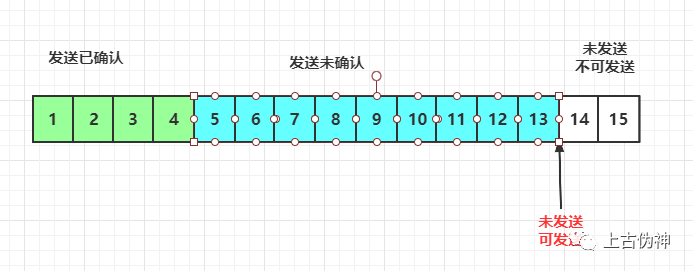
当收到ACK5时,窗口向右滑动一格,此时14可发送
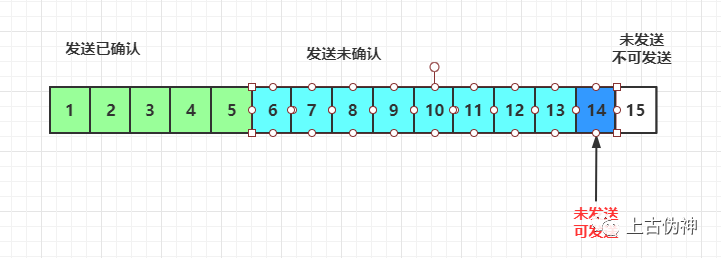
如果接收方处理速度比不上发送方发送速度,导致缓存中没有空间,可通过确认信息修改窗口大小,甚至可设置为0,则发送方将暂时停止发送
假设接收方应用一直不读取缓存中数据,当ACK6到达发送方后,此时携带的窗口大小变成了8
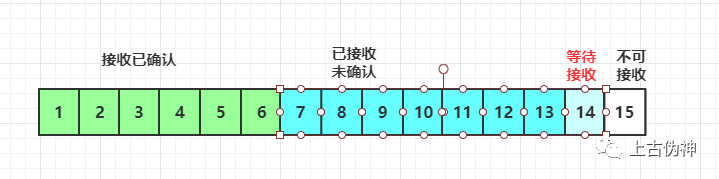
此时发送方仅仅是将左边进行右移,窗口大小从9改成了8
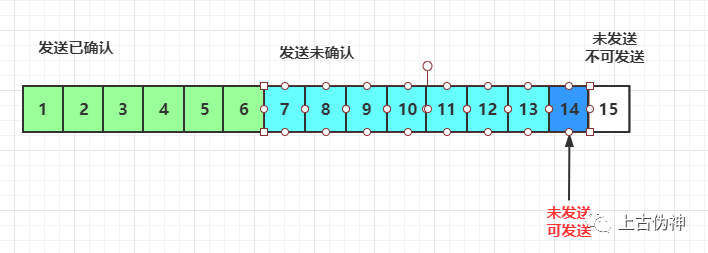
接收端应用一直不读取数据,那么就会一直发送ACK给发送端,直到窗口大小为0
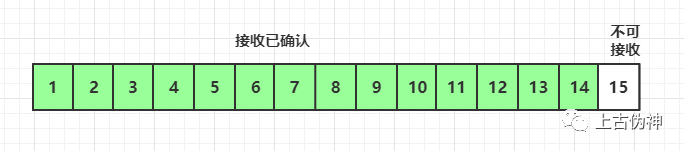
当ACK14到达时,窗口为0,停止发送
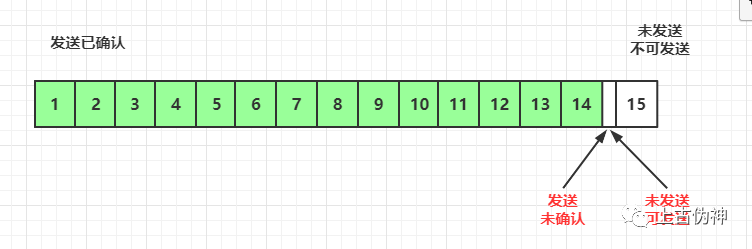
此时发送方会定时发送窗口探测数据包,看是否有机会调整窗口大小。
拥塞控制
拥塞控制也是通过窗口的大小控制的,流量控制的滑动窗口rwnd是怕发送方把接收方缓存塞满,而拥塞窗口cwnd,是怕把网络塞满
rwnd:receiver window,接收方滑动窗口,用于防止接收方缓存占满 cwnd:congestion window,拥塞窗口,用于控制将带宽占满
发送方怎么判断网络是不是慢?
对于TCP协议来说,他不知道整个网络路径都会经历什么,TCP发送包常被比喻为往一个水管里面灌水,而TCP的拥塞控制就是在不堵塞、不丢包的情况下,尽量发挥带宽。
网络有带宽,端到端有时延
通道的容量= 带宽 * 往返延迟
如果设置发送窗口,使得发送但未确认的包为通道的容量,就能撑满整个管道。
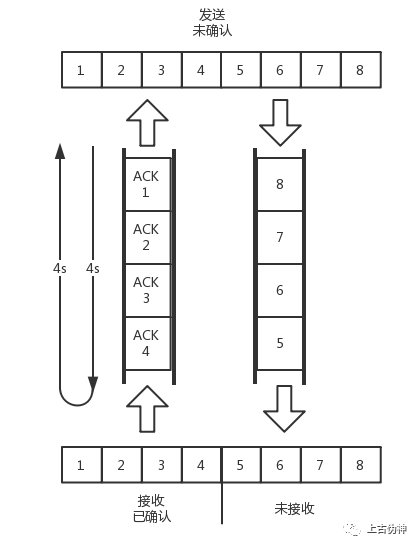
假设往返时间为8s,去4s,回4s,每秒发送一个包,每个包1024byte。
8s后8个包全发出去了,其中前4个包已经到达接收端,但是ACK还没返回,不算发送成功,5-8个包还在路上没被接收,此时整个管道正好撑满。
在发送端,已发送未确认的有8个包,正好等于带宽,也即是每秒发送一个包,乘于往返时间8s。
如果在此基础上调大窗口,单位时间可发送更多的包,那么单位时间内,会有更多的包到达中间设备,但设备在单位时间的处理速度跟不上,多出来的包就会被丢弃。
此时,可以在中间设备上添加缓存,此时包不会丢失,但是会增加时延,如果时延到达一定成都,会进行超时重传。
所以TCP的拥塞控制主要避免两种现象:包丢失和超时重传。
出现这两个现象就说明发送速度过快,需要慢一点。
如果发送速度从慢开始,发现可以加快速度的发,这叫慢启动。类似于车的加速。
一条TCP连接开始,cwnd设置为1个报文段,一次只能发1个,当收到这一个确认时候,cwnd加1,此时可以一次发2个,当这两个确认到来时,每确认一个,cwnd加1,此时cwnd为4,可以发4个。这是指数型增长。
直到cwnd达到ssthresh=65535个字节的时候,就需要慢下来。
此时每收到一个确认后,cwnd增加1/cwnd,一次发送8个,8个确认一共是8*(1/8)=1,于是此时可以发送9个,变成了线性增长。
拥塞的一种表现形式是丢包,需要超时重传,此时,将sshresh设为cwnd/2,将cwnd设为1,重新开始慢启动,此时传输速度就会立马慢下来,造成网络卡顿。
快速重传算法。当接收端发现丢了一个中间包的时候,发送三次前一个包的 ACK,于是发送端就会快速地重传,不必等待超时再重传。TCP 认为这种情况不严重,因为大部分没丢,只丢了一小部分,cwnd 减半为 cwnd/2,然后 sshthresh = cwnd,当三个包返回的时候,cwnd = sshthresh + 3,也就是没有一夜回到解放前,而是还在比较高的值,呈线性增长。
例如,此时cwnd为6,有一个包迟迟没返回ACK,此时cwnd变成3,ssthresh=cwnd,当收到三个请求发送这个包的ACK时,cwnd = ssthresh + 3 = 6
这样就不会一下导致网络卡顿。
TCP 的拥塞控制主要来避免的两个现象都是有问题的
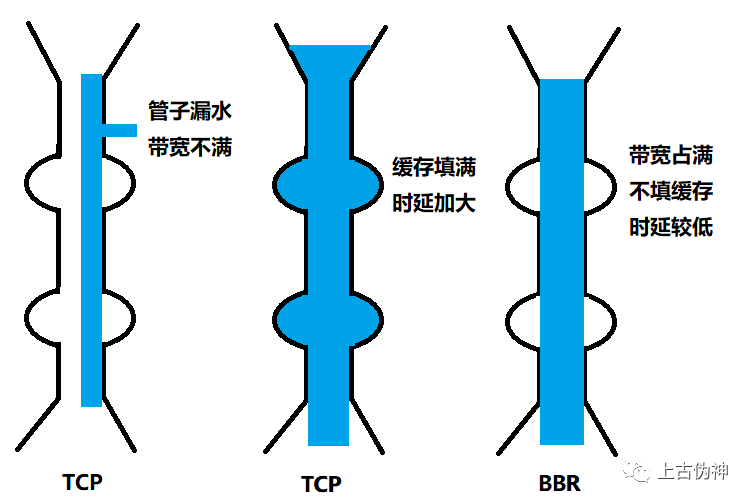
第一个问题是丢包并不代表着通道满了,也可能是管子本来就漏水。例如公网上带宽不满也会丢包,这个时候就认为拥塞了,退缩了,其实是不对的。 第二个问题是 TCP 的拥塞控制要等到将中间设备都填充满了,才发生丢包,从而降低速度,这时候已经晚了。其实 TCP 只要填满管道就可以了,不应该接着填,直到连缓存也填满。
为了优化这两个问题,后来有了 TCP BBR 拥塞算法。它企图找到一个平衡点,就是通过不断地加快发送速度,将管道填满,但是不要填满中间设备的缓存,因为这样时延会增加,在这个平衡点可以很好的达到高带宽和低时延的平衡。

往期推荐:
DNS域名解析系统