
微博更经济的异地容灾方案是怎么搞的
写在前面
中国的互联网独角兽的体量都是非常大的,由于中国人口众多,任何一家互联网企业想在中国的互联网圈子立足,都需要生长到一个非常大的规模,也就是说这家独角兽企业承载的数据与服务的量都相当巨大。
在如此巨大的体量和数据下,解决各种黑天鹅事件,保障公司业务正常发展非常重要。
层出不穷的黑天鹅
对于互联网企业技术团队来说,什么是黑天鹅?
机房大面积断电,整个可用区不可用,火灾、挖掘机都有可能是你的稳定性杀手。
这些极端情况发生时,为维持互联网业务可用,就需要解决容灾问题。
互联网系统可以分成:服务层与数据层。
对于服务层来说我们可以理解成是无状态的;而数据层是有状态的;无状态服务的容灾更多是解决快速的扩缩容与负载均衡就可以了,相对来说有状态的数据层做好容灾成本就会很高。
容灾
对于容灾来说,最简单的法则就是“冗余、备份”。数据通过备份和冗余度提升容灾。而不同的数据有不同的重要程度、恢复时效要求,这些决定了数据的备份策略。
比如日志类的数据,重要程度低,时效要求不高,可以采用离线冷备;而金融类的数据,重要程度高,时效要求也高,一般采用多副本热备;
如果更高级别核心数据可以采用321备份原则,即:至少3个副本、2个不同存储介质、1个offsite。
321备份
数据备份的要求是:
数据的一致性;
数据的完整性;
单个文件的数据一致性通过数据摘要进行动态存储验证,使用纠错码处理bit反转静默存储错误;
数据完整性使用大块存储结合Merkle Hash Tree解决。所有数据文件都拆分或组合成1gb的数据块。数据备份元数据由《版本号、业务线、数据类型、数据块列表》组成,这样备份服务可以实现按指定业务和数据类型自定义备份了。
数据备份采用snapshot全量备份+streaming增量备份方式。引入watch机制,数据容量累积到一定程度或超时,会把增量数据进行一次checkpoint。
snapshot通常是天级别,checkpoint一般是小时级别。
在微博使用的资源中,一类是类似 Redis,读写量非常高,增量数据产生的 operation streaming 量非常大,但这类资源的单实例容量一般控制在 10GB 级别,可以提升 snapshot 的频率,降低两个 checkpoint 之间的数据量以提升恢复效率。
另一类是 MySQL,单实例容量非常大,通常在 TB 级别,写入量较低,可以降低 snapshot 的频率,提升 checkpoint 的频率,以在存储成本与数据恢复效率上达到平稳。
数据服务服务通过 checkpoint 机制,将数据备份转换成了数据块的存储与备份。
微博在数据备份上遵循了 321 策略:
1)所有的数据备份都至少包含 2 个热备,2 个冷备;
2)在线热备数据存储在 SSD 设备,冷备数据存储在独立的 OSS 集群;
3)数据会在异地离线存储,通过专线进行数据同步与传输;
数据备份服务存储中心选择的是在云原生场景下应用广泛的对象存储 OSS。
在逻辑上,恢复中心由管理端与存储端组成,且二者逻辑上是独立的。
存储端支持多物理存储,支持在物理上各个机房内的自己 OSS 存储集群,同时还支持接入云厂商的 OSS 服务;由管理端来统一调度。
管理端本身亦支持异地多活。
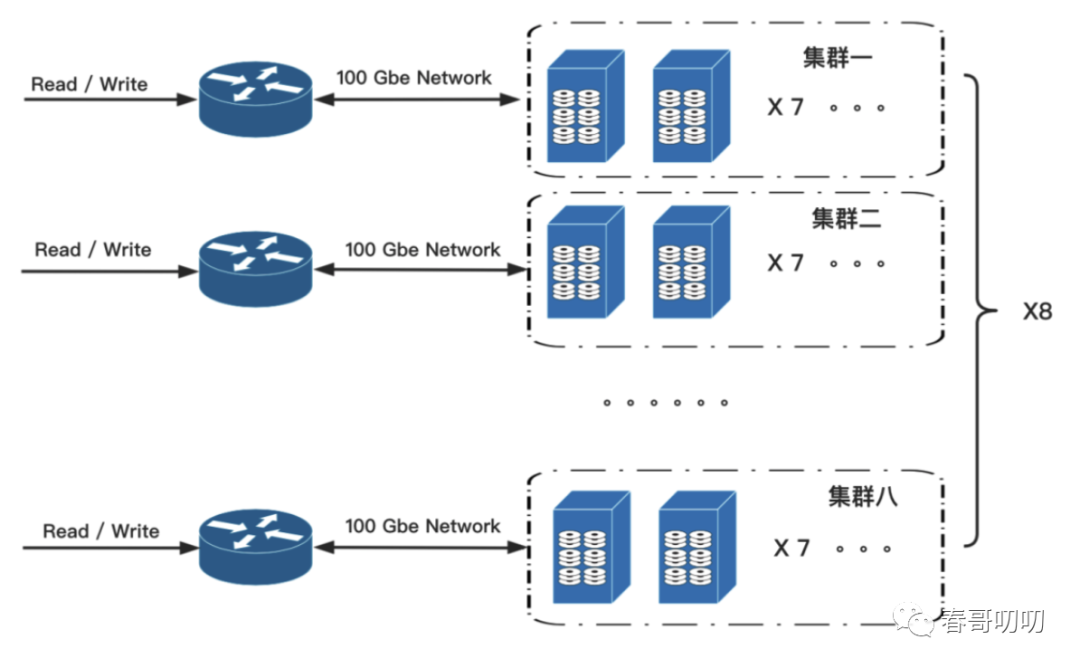
自建存储共 8 个集群,每个小集群 7 台存储主机,单机容量 20T,单集群容量 140T, 8 个集群 1120 TB。集
群对外网络带宽为 100Gbps。
自建存储集群示意图如下,能够支撑 PB 级别的数据备份与快速读取。
微博特点
微博是媒体属性非常强的社交产品,对于微博本身,如果这部分数据不可用对于微博的影响是巨大的。所以对于微博来说,数据的备份只是手段,更进一步的诉求是,数据的快速恢复,其实对于所有的在线业务应该都适用,如果不能承诺在线能力的持续可用,就是有损的。而一些统计类,允许T+1类的数据场景,备份及恢复要求就不会那么高。
微博根据自己的经验,和实际情况。推导出在极端情况,希望在线数据完全损毁时,1小时内在异地重建一个完整的微博单元链路实例,同时保证新建单元内服务的数据完整。
这种十万量级资源部署,业务1小时异地重建是非常牛逼的。这种比热备更经济的方案,在业界还算是首例,挑战巨大。
我们再看下微博的体量,2020年10月,微博MAU为5.23亿,日产生数据量PB级,核心业务线数据到100PB。存储方式涵盖,图片、视频、镜像文件、mysql、redis、原始二进制文件等。
为满足异地数据恢复,同时考虑到可用性、经济成本、安全性、效率等问题,整个设计过程中,所有的设计都围绕于恢复时效性展开,把数据和恢复链路中所涉及的所有环节都进行标准化与自动化。
标准化与自动化
标准化
就像前文所说,数据本身的重要性是有差异的。如果不划分需要恢复的100pb级数据,无论成本还是效率都是无法承受的。所以我们需要对数据进行标准化的重要程度划分。
微博采用垂直和水平两个方向进行数据优先级划分:
垂直方向:按业务的重要程度划分核心与非核心。核心业务需要结合业务与链路判定。
水平方向:数据访问本身是有时效性的,在微博场景下7日内访问量超过98%。极少超过一年的数据会被回调回来,所以可以按照数据访问的热力值判定数据。
经过以上两个方向的拆分,核心热门数量级的规模下降到PB级别,这使得1小时内重建数据成为可能。
自动化
第一个自动化是围绕于资源服务拓扑构建的。有了数据分级标准后,找出不同分级的数据。由于数据是服务产生的,所以根据数据分级可以找到对应的服务,也就有了服务分级的概念,数据备份变成了服务备份。
之后通过流量追踪的方式,找到数据指标的依赖路径,串联多个服务节点,建立拓扑,完成整改网络拓扑的构建。
需要注意,核心业务不依赖于非核心业务。微博通过mesh实现了服务的注册,形成服务依赖拓扑,包括:服务、mysql、redis等。通过mesh agent发现并注册到所属的服务池。
第二个自动化是围绕于数据备份。不同类型数据备份方式不同,流量会贯穿四层与七层、RPC、Mysql、Redis等。所有接入数据恢复中心的服务,都需要提供snapshot+streaming两个api。
snapshot用于生成数据快照;streaming提供上一次快照之后的增量操作;
当服务提供两个api之后,数据恢复中心就可以自动完成数据备份了,实现了备份与业务的解耦。
如何实现1小时异地重建?
全站的异地重建主要是为了应对极端的灾难,也就是说站内所有数据都处于不可用状态,所有的数据恢复与构建都需要在1小时内完成。这就要求每个环节都可以自动化处理,核心操作流程如下:
第 1 分钟:实现系统自举
第 13 分钟:基础设施的部署与准备
第 53 分钟:服务启动与数据分发
第 58 分钟:服务自检、自动注册与负载均衡变更
第 60 分钟:完成流量迁移
系统自举
部署在 offsite 的 event-listener 收到恢复事件后,首先开启备份数据自检流程。主要包括:
加载对应版本的备份元数据。元数据包含备份的整体统计信息,包括服务的版本、数量、规格以及服务依赖,用于在服务恢复时构建拓扑信息及加速分发。
恢复混合云平台服务 DCP。DCP 作为混合云的 IaaS 层,后续所有的物理机资源都通过 DCP 创建。为了减少 DCP 恢复时的依赖,提升 DCP 的恢复速度,DCP 部署涉及的所有的二进制包、存储等支持单机部署,所有实例都部署在一台高配机器(256C/2TB 内存)上,可以做到 1 分钟以内完成 DCP 的恢复。
基础设施的部署
DCP 启动后作为 IaaS 设备混合云提供平台,借助云厂商 5 分钟扩容 2000 台神龙裸金属的能力,相当于 8 万台 ECS 服务器。
DCP 启动后,读取备份元数据中 IaaS 设备的规格、数量,快速扩容指定数量机器,并完成包括 Docker、kubelet 等初始化(初始化过程需要花费 2min 左右时间)。
服务启动与数据分发
完整的服务启动与数据分发包括服务拓扑解析、服务镜像拉取与启动以及数据分发等几个阶段。
服务依赖树解析:offsite 解析模块开始解析灾备待恢复服务元数据,将服务依赖关系解析到服务依赖树。各个服务树全速并行恢复,服务与资源按照存储在拓扑图中的距离就近甚至同机部署,最大程度上提升带宽吞吐,在机器上挂载磁盘时每业务一块盘,提升整体磁盘顺序写入 IO 带宽。
服务恢复流程:微博构建了以 Kubernetes、Docker 为代表的容器调度混合云平台,为业务提供 serverless 服务。容器调度平台可以快速适配待恢复服务所需运行时环境。为了解决待恢复服务对 CPU、内存、磁盘、带宽等五花八门运行时环境的诉求,我们将其抽象提炼到规格,根据规格匹配锁定 IaaS 层节点设备,在锁定节点上拉取镜像,启动容器服务。
业务数据分发:在服务恢复过程中,当容器启动后,对于同一份数据需要分发多次的场景,例如服务的应用的可执行文件、镜像,使用 P2P 的分发方式,多点并行分发,大幅提高分发效率,同时降低存储 server 的负载。
服务自检、自动注册与负载均衡变更
所有纳入到 weibo-mesh 管理的服务及资源,都实现了标准的回调 API:服务注册、健康检查、预热以及启动心跳保持。
服务在启动完成首先会健康检查,健康检查通过后调用预热接口,避免系统冷启动导致的大量超时;冷启动完成后,服务实例会自动注册到分布式配置中心(微博自建的服务:vintage),启动心跳汇报功能完成服务的注册。
四、七层的启动过程与普通的服务并无差异,以 nginx 为例:在 nginx 完成部署部署启动后,nginx-upsync-module 会自动从分配式配置中心 vintage 同步其相关的配置并进行动态 reload,完成 upstream 的同步更新与 backend 的注册。
流量迁移
数据恢复中心通过检查分配式配置中心 vintage 并与服务拓扑进行比对,所有服务启动完成后,则变更出口 DNS,以实现流量的迁移,完成最终的异地构建。
后记
完成一个数据恢复中心需要多个独立系统紧密衔接,如:
1)IaaS 层的基础设施管理 DCP,抹平了公有云、自建 IDC 等异构基础设施差异,向上提供 5 分钟 2000 台机器的闪电交付能力,后续基于神龙裸金属可以提供 5 分钟相当于 8 万台机器的交付能力;
2)把所有的物理机资源看成一个超大的 CPU、内存与存储池,由 KRS(自研的基于 K8S 的容器编排调度系统)实现服务的全网调度,有效利用了超大规格机器(目前重点使用 256C/2TB 规格)百 Gb 级别的高带宽吞吐等能力,实现全网服务与数据的极速分发;
3)把 Redis、MySQL、RPC、代码、二进制和四七层等所有都看成资源,提供 RaaS(Resource as a Service)的抽象,每一类资源实现标准的 backup、prestop、poststart、register 等接口,都能够自动接入数据恢复中心,做到整个过程零参与;
4)微博的热点联动系统在系统完成冷启动后,自动依赖流量的变更,快速扩容,完成业务的重建过程。
整个异地重建项目过程中,每一个环节都可能会成为瓶颈,如数据备份的可靠性、基础设施的自动化部署与快速构建、基于 P2P 的数据快速分发等等。所以整体功能可行性的验证也非常重要,但如果搭建一套1:1规模的基础设施来验证构建,成本是非常大的。