
CHIP2021|临床术语标准化第三名方案开源
比赛简介
本次DataArk参加了CHIP2021中的三个评测,最终获得一个第一,一个第三,具体如下表:
| 评测任务名称 | 所获名次 | 评测网站 |
|---|---|---|
| 医学对话临床发现阴阳性判别任务 | 第一(a榜第一) | http://cips-chip.org.cn/2021/eval1 |
| 临床术语标准化任务 | 第三(没有a榜) | http://cips-chip.org.cn/2021/eval3 |
临床术语标准化任务
本次CHIP2021的临床术语标准化任务是没有A榜的,所以代码调试都是在天池的中文医疗信息处理数据集CBLUE的临床术语标准化任务上完成的。
现在的主流做法是将临床术语标准化任务分解成 召回 + 排序 + 个数预测 三个子任务。我们使用的是这个做法,本次测评的前两名也都是。总体来说在子任务分解上并没有过多的改进,主要的区别在于实现上的一些细节。
整体方案
本篇文章首先介绍一下临床术语标准化任务主流的实现思路,如下图所示。
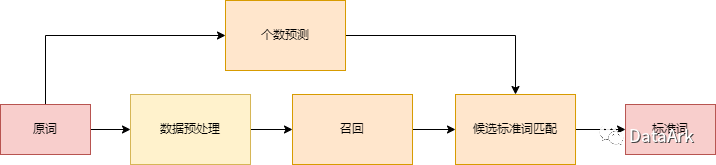
数据预处理主要的目的是扩大召回。
规范化
阿拉伯数字、中文数字、罗马数字归一化成阿拉伯数字 希腊字母转英文 部分特殊符号清洗,如“ 根据训练集中的英文数据,修改标准名
输入 原始标准名 修改后标准名 he:人附睾蛋白 未特指的错he 未特指的错人附睾蛋白 缩写不重要的定语
原始标准名 修改后标准名 未特指的霍乱 未指霍乱 多路召回
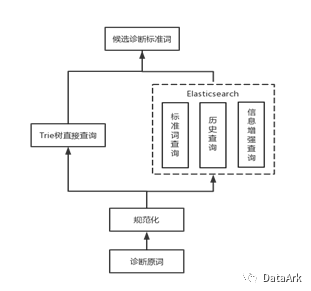
使用Trie树对诊断原词进行高效切词,同时通过Elasticsearch使用上述的三种查询方式进行Top200召回,合并两者结果获取多路召回的候选诊断标准词。
Tries树直接查询:使用ICD-10中的诊断标准词构建Trie树获取查询的诊断原词中包含的诊断标准词作为召回;
标准词查询:将ICD-10中的诊断标准词直接写入Elasticsearch创建索引,并通过BM25算法计算查询的诊断原词和诊断标准词的相似度进行召回;
历史查询:将训练集中的诊断原词写入Elasticsearch创建索引。计算查询的诊断原词与训练集中的诊断原词的相似度,召回与查询的诊断原词相近的训练集中的诊断原词所对应的诊断标准词;
信息增强查询:对ICD-10中的诊断标准词进行规范化和信息扩展处理后获得信息增强后的诊断标准词,并将其写入Elasticsearch创建索引。在召回阶段,查询与诊断原词相近的信息增强后的诊断标准词,获取其对应的诊断标准词。
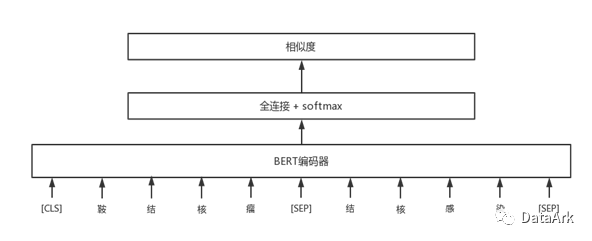
候选标准词匹配主要是文本匹配任务,用于候选标准词集的排序
常见的方法是将拼接诊断原词+候选标准词,进行0-1分类。
我们增加了过滤的步骤:记一个原词与全部候选项的相似预测结果集合为S。
Max(S)>0.5,以0.5作为阈值过滤掉小于0.5的候选项; 0.5>=Max(S)>0.3,选取S的中位数作为阈值,过滤小于中位数的结果; Max(S)<0.3,计算诊断原词与全部候选项jaro距离作为相似概率,得到新的集合,选取当前集合的中位数作为阈值,过滤小于中位数的结果。
个数预测主要针对的是诊断原词和诊断标准词存在的”一对多“的问题
常见的方法是对诊断原词直接做多分类任务,标签设定为0-1个;1-2个;大于2个。
通过个数预测的结果进行解码:记一个原词词的个数预测结果为K,经过过滤后的候选集合为S_n。
K <= 2,返回S_n中top-K的标准词; K > 2,按照得分排序,返回S_n。
最终的结果
在个数预测和候选标准词匹配环节均采用Ernie1.0作为预训练模型,同时选用AdamW作为优化器 。
参数 验证集 测试集 个数预测 76.9 - 候选标准词匹配 74.2 - 标准化 66.4 59.7
模型实现的部分细节
引入指数移动平均(EMA)对模型参数进行累计平均,并且采用FGM[12]方法对嵌入向量进行攻击
十折交叉验证 使用投票法进行集成,针对票数相同的结果,选择结果在每个模型的预测rank最靠前的作为结果 EMA 在于利用滑动平均的参数来提高模型在测试数据上的健壮性 FGM 提高模型应对恶意对抗样本时的鲁棒性; 作为一种regularization,减少overfitting,提高泛化能力。
实现的代码
所有的代码都是基于我们开源的ark-nlp 0.0.2实现。
ark-nlp地址:https://github.com/xiangking/ark-nlp
方案开源地址:https://github.com/DataArk/CHIP2021-Task3-Top3