
多图详解:如何不停服分库分表
JAVA前线
欢迎大家关注公众号「JAVA前线」查看更多精彩分享,主要内容包括源码分析、实际应用、架构思维、职场分享、产品思考等等,同时也非常欢迎大家加我微信「java_front」一起交流学习
1 理论知识
1.1 分库分表是否必要
分库分表确实可以解决单表数据量大这个问题,但是并非首选。因为分库分表至少引入了三个必须解决的突出问题。
第一是分库分表方案本身具有的复杂性。第二是本地事务失效问题,原本在同一个数据库中可以保证强一致性业务逻辑,分库之后事务失效。第三是难以聚合查询问题,因为分库分表后查询条件中必须带有shardingKey,所以限制了很多查询场景。
在之前文章《面试官问单表数据量大是否必须分库分表》介绍过解决单表数据量过大问题,可以按照删、换、分、拆、异、热这六个字顺序进行处理,而不是首选分库分表。
删是指删除历史数据并进行归档。换是指不要只使用数据库资源,有些数据可以存储至其它替代资源。分是指读写分离,增加多个读实例应对读多写少的互联网场景。拆是指分库分表,将数据分散至不同的库表中减轻压力。异指数据异构,将一份数据根据不同业务需求保存多份。热是指热点数据,这是一个非常值得注意的问题。
1.2 分库分表两大维度
假设有一个电商数据库存放订单、商品、支付三张业务表。随着业务量越来越大,这三张业务数据表也越来越大,查询性能显著降低,数据拆分势在必行,那么数据拆分可以从纵向和横向两个维度进行。
1.2.1 纵向拆分
纵向拆分就是按照业务拆分,我们将电商数据库拆分成三个库,订单库、商品库。支付库,订单表在订单库,商品表在商品库,支付表在支付库。这样每个库只需要存储本业务数据,物理隔离不会互相影响。
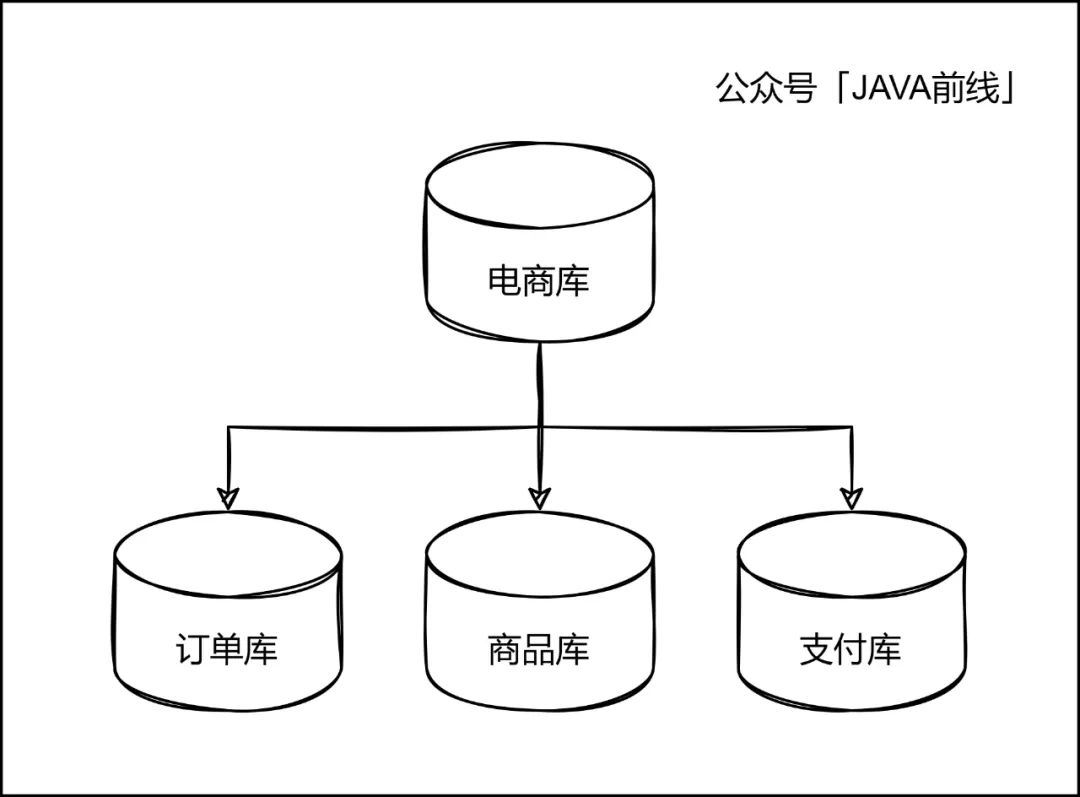
1.2.2 横向拆分
按照纵向拆分方案,现在我们已经有三个库了,平稳运行了一段时间。但是随着业务增长,每个单库单表的数据量也越来越大,逐渐到达瓶颈。
这时我们就要对数据表进行横向拆分,所谓横向拆分就是根据某种规则将单库单表数据分散到多库多表,从而减小单库单表的压力。
横向拆分策略有很多方案,最重要的一点是选好ShardingKey,也就是按照哪一列进行拆分,怎么分取决于我们访问数据的方式。
(1) 范围分片
如果选择的ShardingKey是订单创建时间,那么分片策略是拆分四个数据库,分别存储每季度数据,每个库包含三张表,分别存储每个月数据:

这个方案的优点是对范围查询比较友好,例如我们需要统计第一季度的相关数据,查询条件直接输入时间范围即可。这个方案的问题是容易产生热点数据。例如双11当天下单量特别大,就会导致11月这张表数据量特别大从而造成访问压力。
(2) 查表分片
查表法是根据一张路由表决定ShardingKey路由到哪一张表,每次路由时首先到路由表里查到分片信息,再到这个分片去取数据。我们分析一个查表法思想应用实际案例。
Redis官方在3.0版本之后提供了集群方案RedisCluster,其中引入了哈希槽(slot)这个概念。一个集群固定有16384个槽,在集群初始化时这些槽会平均分配到Redis集群节点上。每个key请求最终落到哪个槽计算公式是固定的:
SLOT = CRC16(key) mod 16384
一个key请求过来怎么知道去哪台Redis节点获取数据?这就要用到查表法思想:
(1) 客户端连接任意一台Redis节点,假设随机访问到节点A
(2) 节点A根据key计算出slot值
(3) 每个节点都维护着slot和节点映射关系表
(4) 如果节点A查表发现该slot在本节点,直接返回数据给客户端
(5) 如果节点A查表发现该slot不在本节点,返回给客户端一个重定向命令,告诉客户端应该去哪个节点请求这个key的数据
(6) 客户端向正确节点发起连接请求
查表法方案优点是可以灵活制定路由策略,如果我们发现有的分片已经成为热点则修改路由策略。缺点是多一次查询路由表操作增加耗时,而且路由表如果是单点也可能会有单点问题。
(3) 哈希分片
相较于范围分片,哈希分片可以较为均匀将数据分散在数据库中。我们现在将订单库拆分为4个库编号为[0,3],每个库包含3张表编号为[0,2],如下图如所示:
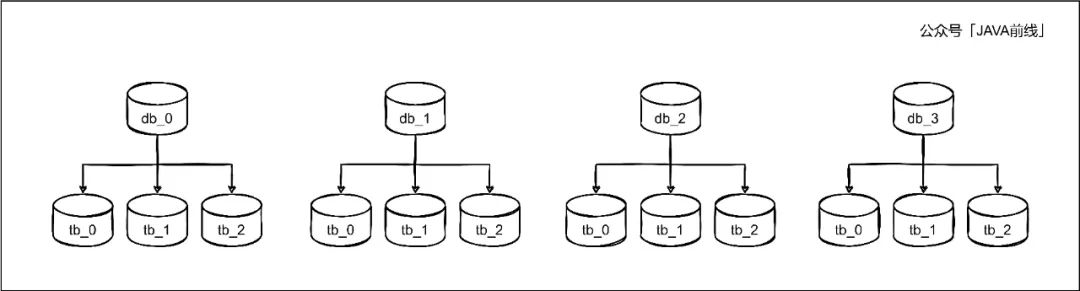
我们选择使用orderId作为ShardingKey,那么orderId=100这个订单会保存在哪张表?因为是分库分表,第一步确定路由到哪一个库,取模计算结果表示库表序号:
db_index = 100 % 4 = 0
第二步确定路由到哪一张表:
table_index = 100 % 3 = 1
第三步数据路由到0号库1号表:

在实际开发中路由逻辑并不需要我们手动实现,因为有许多开源框架通过配置就可以实现路由功能,例如ShardingSphere、TDDL框架等等。
2 分库分表准备工作
2.1 计算库表数量
分几个库和几张表是在分库分表工作开始前必须要回答的问题,我们首先看看阿里巴巴开发手册的建议:单表行数超过500万行或者单表容量超过2GB才推荐进行分库分表,如果预计3年后数据量根本达不到这个级别,请不要在创建表时就分库分表。我们提取出这个建议的两个关键词:500万、3年,作为预估库表数的基线。假设业务数据日增量60万,那么应该如何预估需要分多少个库和多少张表呢?
日增量60万计算3年后数据总量:
三年数据总量 = 60 * 365 * 3 = 65700
随着后续业务发展日增量会超过60万,所以我们要对数据总量进行冗余,冗余指数是多少根据业务情况而定,本文按照3倍冗余:
三年数据总量三倍冗余 = 65700 * 3 = 197100
单表500万并向上取整至2的幂次计算表数量:
表数量 = 197100 / 500 = 394.2 向上取整 = 512
所有表放在一个库并不合适,因为随着数据量增大,访问并发量也会呈正相关增大,一个数据库实例是难以支撑的。本文按照一个数据库实例包含32张表计算库数量:
库数量 = 512 / 32 = 16
2.2 shardingKey
确定shardingKey非常关键,因为作为分片指标,当数据拆分至多个库表之后,代理层只能根据shardingKey进行表路由。
假设我们设置了userId作为shardingKey,那么后续DML操作都必须包含userId字段。但是现在有一种场景只有orderId作为查询条件,那么我们应该如何处理这种场景呢?
第一种方案是设计orderId包含userId相关特征,这样即使只有订单号作为查询条件,也可以截取userId特征进行分片:
订单号 = 毫秒数 + 版本号 + userId后六位 + 全局序列号
第二种方案是数据异构,核心思想是以空间换时间,一份数据根据不同维度存储到多个数据介质,数据异构一般分为如下类型。
数据异构至MySQL:我们可以选择orderId作为shardingKey存储至另一个数据库实例,那么orderId就可以作为条件进行查询。
数据异构至ES:如果每一个维度都新建一个数据库实例也是不现实的,所以我们可以将数据同步至ES满足多维度查询需求。
数据异构至Hive:MySQL和ES可以满足实时查询需求,Hive可以满足离线分析需求,数据分析工作无需通过主库,而是可以通过Hive进行。
现在又引出一个新问题,业务不可能每次都将数据写入多个数据源,这样会带来性能和数据一致性问题,所以需要一个管道进行各数据源之间同步,阿里开源canal组件可以解决这个问题。
3 分库分表实例
在完成准备工作之后,我们可以开始分库分表工作了。分库分表方法有很多种,但是说到底都是在处理两类数据:存量和增量。存量表示旧数据库已经存在的数据,增量表示不存在于旧数据库待新增或者变更的数据。根据存量和增量这两种类型,我们可以将分库分表方法分为停服拆分和不停服拆分。
3.1 停服拆分
停服是指停止服务,系统不再接收新业务数据,那么旧数据在分库分表这个时间段内是静止不变的,数据全部变为了存量数据。停服拆分一般分为三个阶段。
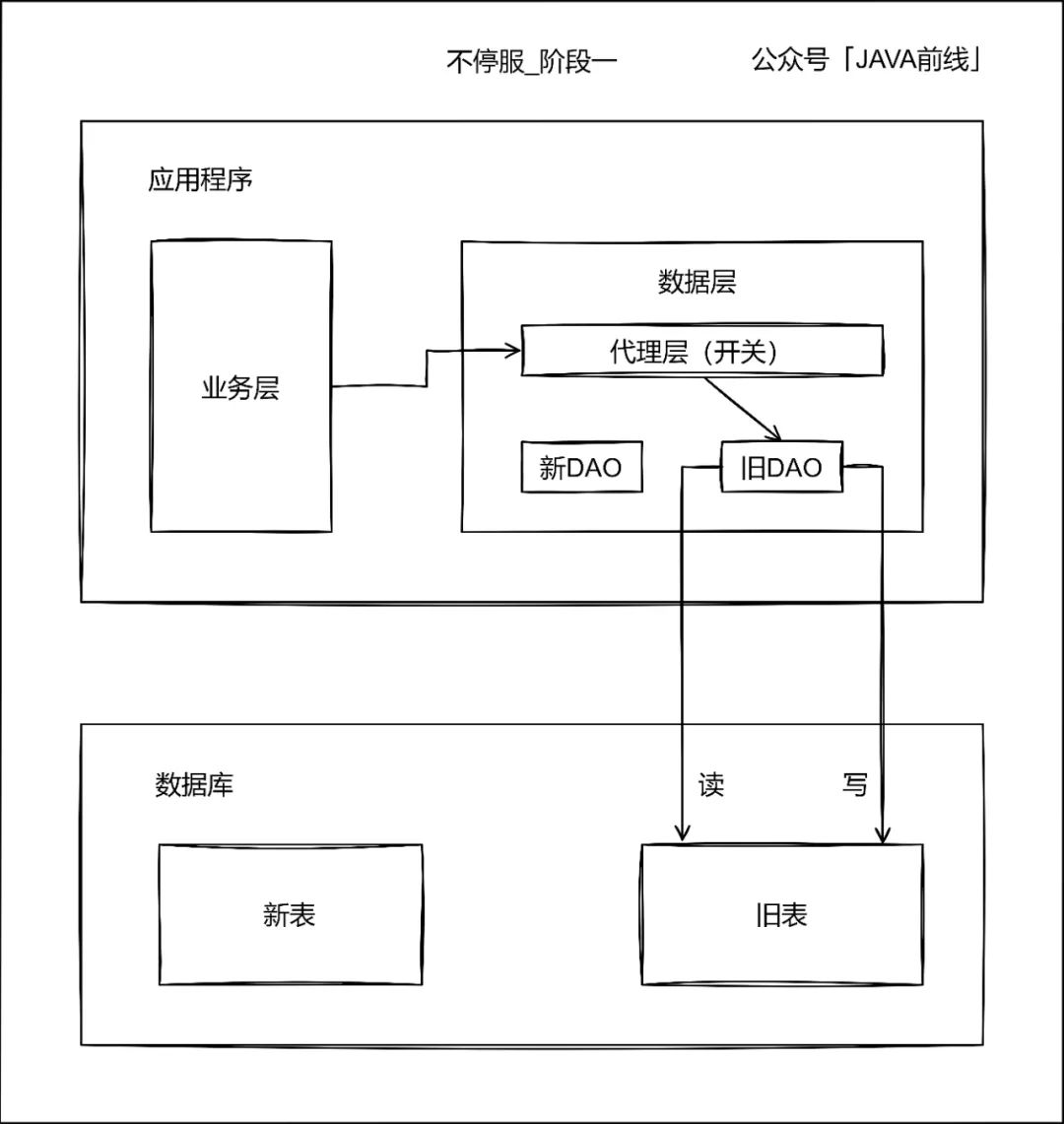
第一阶段首先编写代理层和新DAO,代理层通过动态开关决定访问旧表还是新表,此时流量还是全部访问旧表:

第二阶段停止服务,整个应用都没有流量,旧表数据已经处于静止状态,通过脚本将存量数据分页从旧表迁移至新表:

第三阶段通过代理层访问新表:

3.2 不停服拆分
停服拆分方案比较简单,但是在分表这段时间没有业务流量,对业务是有损的,所以我们一般采用不停服拆分方案,一边有流量访问,一边进行分库分表,此时数据不仅有存量还有增量,相对而言会复杂一些。
第一阶段首先编写代理层和新DAO,代理层通过动态开关决定访问旧表还是新表,此时流量还是全部访问旧表:
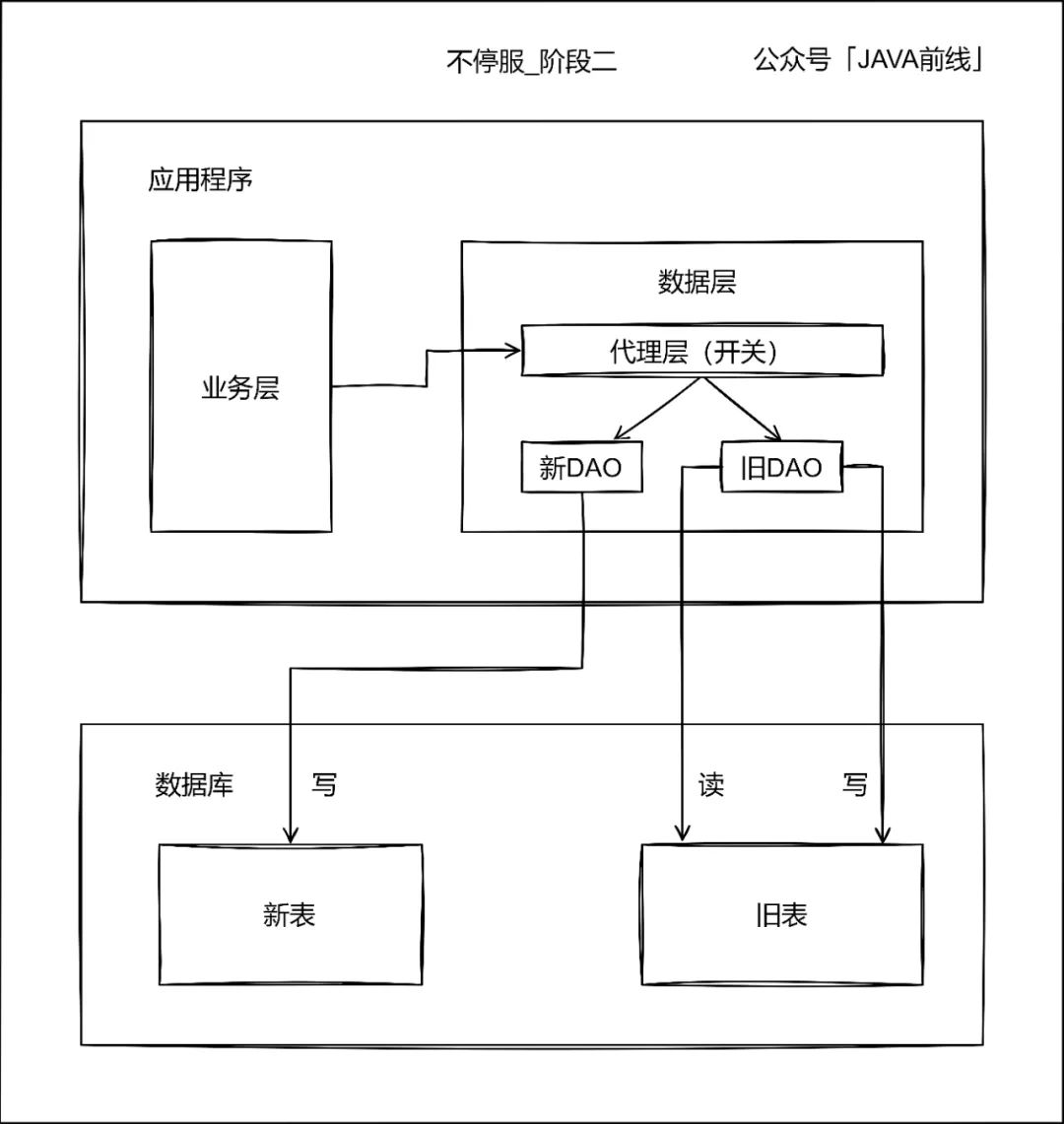
第二阶段开启双写,增量数据不仅在旧表新增和修改,也在新表新增和修改,日志或者临时表记录写入新表ID起始值,旧表中小于这个值的数据就是存量数据:
第三阶段进行存量数据同步,通过脚本将存量数据分页写入新表:

第四阶段停读旧表改读新表,此时新表已经承载了所有读写业务,但是不要立刻停写旧表,需要保持双写一段时间。
不停写旧表有两个原因:第一是因为如果读新表出现问题,还可以将读流量切回旧表。第二是因为可以进行数据校对,例如新表和旧表数据都同步至Hive,选取几天的数据进行校对,从而验证数据同步准确性。
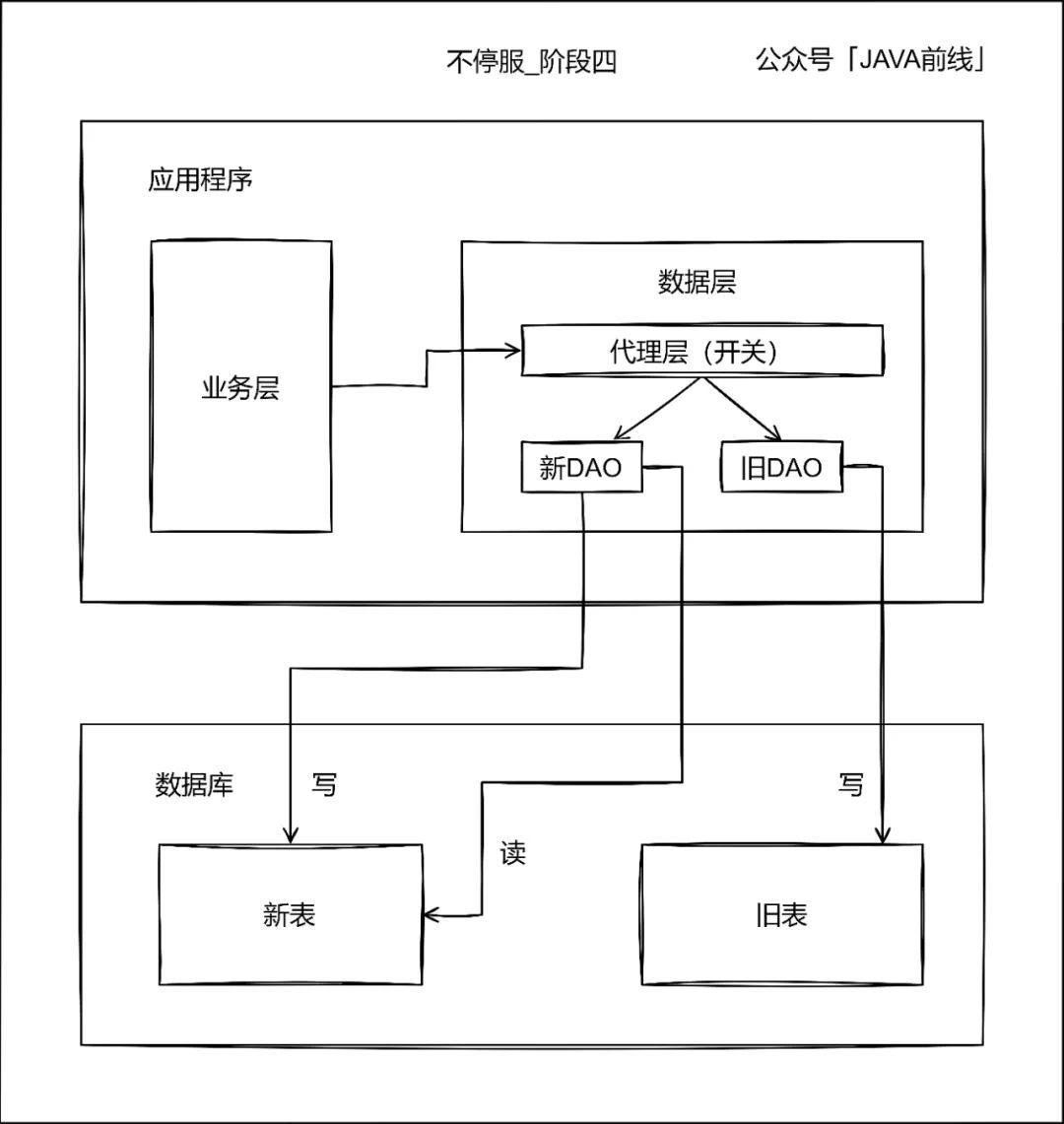
第五阶段当读写新表一段时间之后,没有发生业务问题则可以停写旧表:
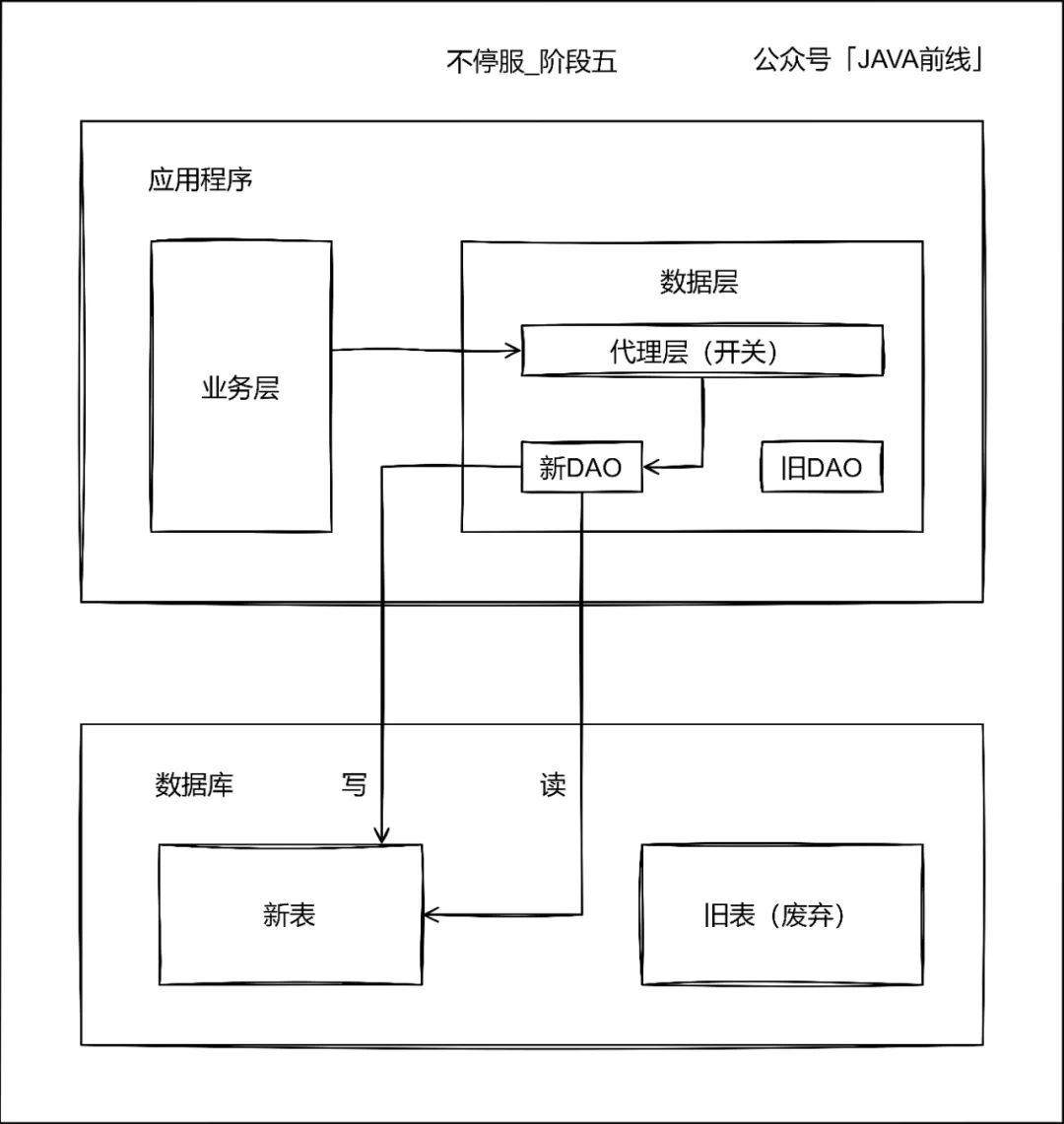
3.3 代理层实现
代理层实现了新旧数据源切换,需要尽量减少业务层代码的侵入性,而适配器模式可以有效减少对业务层的侵入性。我们首先看看旧数据访问对象和业务服务:
// 订单数据对象
public class OrderDO {
private String orderId;
private Long price;
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public Long getPrice() {
return price;
}
public void setPrice(Long price) {
this.price = price;
}
}
// 旧DAO
public interface OrderDAO {
public void insert(OrderDO orderDO);
}
// 业务服务
public class OrderServiceImpl implements OrderService {
@Resource
private OrderDAO orderDAO;
@Override
public String createOrder(Long price) {
String orderId = "orderId_123";
OrderDO orderDO = new OrderDO();
orderDO.setOrderId(orderId);
orderDO.setPrice(price);
orderDAO.insert(orderDO);
return orderId;
}
}
引入新数据源访问对象:
// 新数据对象
public class OrderNewDO {
private String orderId;
private Long price;
}
// 新DAO
public interface OrderNewDAO {
public void insert(OrderNewDO orderNewDO);
}
适配器模式减少业务代码侵入性:
// 代理层
public class OrderDAOProxy implements OrderDAO {
private OrderDAO orderDAO;
private OrderNewDAO orderNewDAO;
public OrderDAOProxy(OrderDAO orderDAO, OrderNewDAO orderNewDAO) {
this.orderDAO = orderDAO;
this.orderNewDAO = orderNewDAO;
}
@Override
public void insert(OrderDO orderDO) {
if(ApolloConfig.routeNewDB) {
OrderNewDO orderNewDO = new OrderNewDO();
orderNewDO.setPrice(orderDO.getPrice());
orderNewDO.setOrderId(orderDO.getOrderId());
orderNewDAO.insert(orderNewDO);
} else {
orderDAO.insert(orderDO);
}
}
}
// 业务服务
public class OrderServiceImpl implements OrderService {
@Resource
private OrderDAO orderDAO;
@Resource
private OrderNewDAO orderNewDAO;
@Override
public String createOrder(Long price) {
String orderId = "orderId_123";
OrderDO orderDO = new OrderDO();
orderDO.setOrderId(orderId);
orderDO.setPrice(price);
new OrderDAOProxy(orderDAO, orderNewDAO).insert(orderDO);
return orderId;
}
}
4 文章总结
分库分表具有三个必须面对的突出问题:方案本身复杂性、本地事务失效问题、难以聚合查询问题,所以分库分表方案并非解决海量数据问题的首选方案,这一点非常值得注意。
如果必须分库分表,我们首先进行容量预估并选择合适的shardingKey,其次根据实际业务选择停服或者不停服方案,如果选择不停服方案,注意保持新表和旧表双写一段时间,从而验证数据准确性,希望本文对大家有所帮助。
5 延伸阅读
JAVA前线
欢迎大家关注公众号「JAVA前线」查看更多精彩分享,主要内容包括源码分析、实际应用、架构思维、职场分享、产品思考等等,同时也非常欢迎大家加我微信「java_front」一起交流学习