
Ceph分布式存储系统架构研究综述



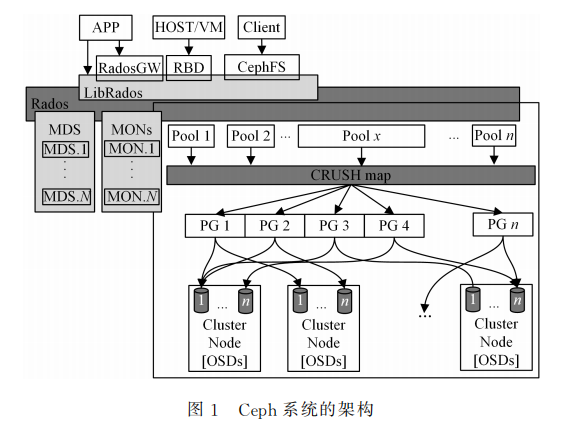
Ceph存储系统的设计目标是提供高性能、高可扩展性、 高可用的分布式存储服务。它采用 RADOS在动态变化和异构的存储设 备集群上,提供了一种稳定、可扩展、高性能的单一逻辑对象 存储接口和能够实现节点自适应和自管理的存储系统。数据的放置采取 CRUSH 算法,客户端根据算法确定对象的位置并直接访问存储节点,不需要访 问元数据服务器。CRUSH算法具有更好的扩展性和性能。本文介绍Ceph 的集群架构、数据放置方法以及数据读写路径,并在此基础上分析其性能特点和瓶颈。
RADOS可提供高可靠、高性能和全分布式的对象存储 服务。对象的分布可以基于集群中各节点的实时状态,也可以自定义故障域来调整数据分布。块设备和文件都被抽象包装为对象,对象则是兼具安全和强一致性语义的抽象数据类型,因此 RADOS可在大规模异构存储集群中实现动态数据 与负载均衡。
对象存储设备(OSD)是 RADOS 集群的基本存储单元,它的主要功能是存储、备份、恢复数据,并与其他 OSD之间进行负载均衡和心跳检查等。一块硬盘 通常对应一个 OSD,由 OSD对硬盘存储进行管理,但有时一 个分区也可以成为一个 OSD,每个 OSD皆可提供完备和具有强一致性语义的本地对象存储服务。MDS是元数据服务器,向外提供 CephFS在服务时发出的处理元 数据的请求,将客户端对文件的请求转换为对对象的请求。RADOS中可以有多个 MDS分担元数据查询的工作。
RADOS取得高可扩展性的关键在于彻底抛弃了传统存 储系统中的中心元数据节点,另辟蹊径地以基于可扩展哈希 的受控副本分布算法——CRUSH 来代替.通过 CRUSH 算法,客户端可以计算出所要访问的对象所在的 OSD。
与以往 的方法相比,CRUSH 的数据管理机制更好,它把工作分配给 集群内的所有客户端和 OSD 来处理,因此具有极大的伸缩性。CRUSH 用智能数据复制来确保弹性,更能适应超大规模存储。如图所示,从文件到对象以及PG(Placement Group)都 是逻辑上的映射,从PG到OSD的映射采用CRUSH 算法,以保证在增删集群节点时能找到对应的数据位置。
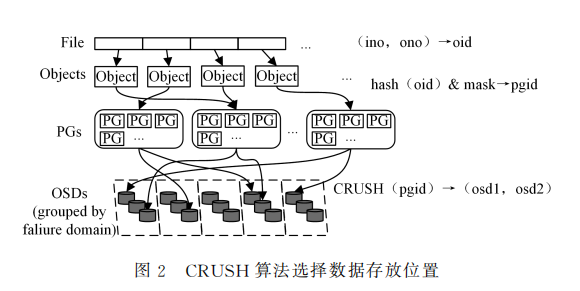
根据Weil的研究,CRUSH算法具有相当好的可扩展性,在数千个 OSD的情况下仍然能保证良好的负载平衡。但这更多的是理论层面上,目前还没有研究人员给出在数 PB 规模的生产环境中的测试结果。
CRUSH算法是Ceph最 初 的 两 大 创 新 之 一,也是整个RADOS的基石。CRUSH在一致性哈希的基础上很好地考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如 跨机房、机架感知等。同时,CRUSH 算法支持多副本和纠删码这两种数据冗余方式,还提供了4种不同类型的 Bucket (Uniform、List、Tree、Straw),充分考虑了实际生产过程中硬 件的迭代式部署方式。
CRUSH 虽然提供了快速数据定位方法,但也有一定的缺陷。首先,在选择OSD 时会出现权重失衡的情况,即低权重的OSD虽然在实际中可用,但是与其他复制节点相差较大且需二次哈希;其次,在增删OSD时会有数据的额外迁移;最后,完全依赖哈希的随机性可能会导致OSD的容量使用率不均衡,在实际环境中出现过超过40%的差异。因此,从2017年发布的Luminous版本起,Ceph提供了被称为upmap的新机制,用于手动指定PG的分布位置来达到均衡数据的效果。
RADOS提供了分布式对象存储能力,并在此基础上扩展了块存储和文件存储功能。RADOS中单个对象的大小根据配置文件指定(一般为4M)。LIBRADOS提供的库可以访问任意对象的内容。RGW提供了一个基于Bucket的对象存储服务。RGW提供的服务兼 容AWS(Amazon WebServices)的S3 以及Openstack的Swift。RGW的对象可大于4M,当其大小超过4M时,RGW会将该对象分为首对象和多个数据对象。
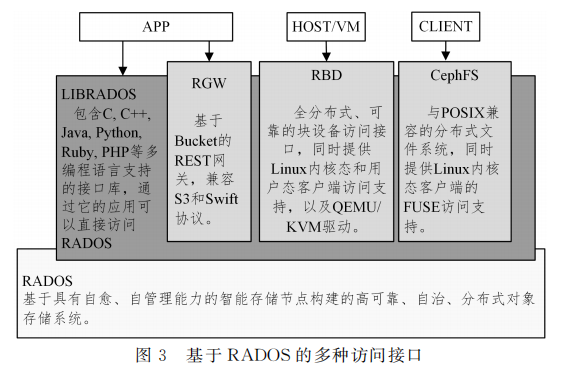
块存储接口提供类似磁盘的连续字节序列的存储能力,这是存储数据应用最广泛的形式。磁盘阵列、存储区域网络、iSCSI都可以提供块存储功能。Ceph的块存储利用 RADOS 功能,支持复制、快照、一致性和高可用等特性。块设备是精 简配置的,并且可调整大小。Ceph的RBD可使用内核模块或librbd与OSD进行交互。RBD设备默认在名为rbd的资源池中。每个rbd在创建后会生成一个 名为rbdName。
文件系统接口是通过 CephFS实现的。CephFS文件系 统中的数据(文件内容)和元数据(目录、文件)都以对象的形 式被保存在 OSD上。客户端可以使用ceph fuse挂载为应用 层模式或者使用内核的mount ceph挂载为内核模式。两种模式都是与 MDS通信,以获得文件系统的目录结构信息,并访问对应的OSD。CephFS的元数据也被保存在对象中,其对象的前缀为msd_,保存的内容包括文件系统的索引节点、元数据日志和快照等。MDS在启动时会读取文件系统元数据对象并将其缓存在内存中,客户端需要与之通信以查询 或更新元数据信息。
Ceph是一个通用的分布式文件系 统,适 用 于 不 同 的 场 景.内部机制的优化对所有的场景都会产生性能的提升,但是优化的难度和复杂度也最高。
在分布式存储系统中,数据被分散在大量的存储服务器上,大部分分布式存储系统都直接使用本地文件系统来存储 数据,如HDFS,Lustre等。 高性能、高可靠的分布式存储系统离不开高效、一致、稳定、可靠的本地文件系统。本地文件系统的代码已经过长时间的测试和性能优化,对于数据持久化和空间管理也有相应的方案。文件系统提供了 POSIX接口,通过这个接口,分布式文件系统可以切换不同的本地文件系统。
Ceph早期的版本采用将对象存储在本地文件系统的存储后端的方式,该方式被称为 FileStore。FileStore通过POSIX接口将对象和对象属性放在本地文件系统上,如 XFS、ext4、btrfs等。最初,对象属性被存储在POSIX扩展文件属性(xattrs)中,但当后来对象属性超出xattrs的大小或计数限制时,FileStore就在LevelDB中存放对象属性。本地文件系统不能很好地适配 Ceph的对象存储需求的原因主要包括以下几个方面。
1)数据和元数据分离不彻底,导致对象寻址慢。FileStore根据对象前缀将其放置在不同目录下,对象在进行访问时需要多次寻址,且同一目录下的文件也没有排序。
2)本地文件系统不支持对象的事务操作。FileStore为了支持写事务的特性,通过写前日志功能来保证事务的原子性。这导致了数据“双写”的问题,造成了一半磁盘性能的浪费。
3)本地文件系统也有日志等保证一致性的操作,这进一步导致了写放大。
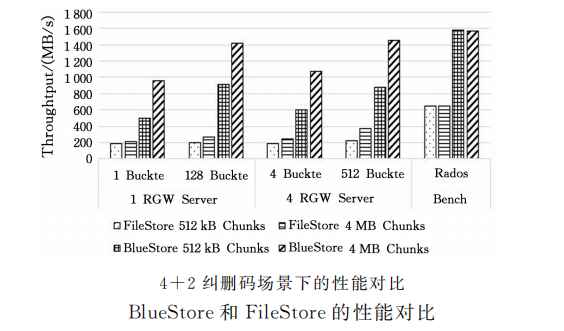
使用本地文件系统作为后端存储的弊端导致了FileStore的性能很差。我们测试的结果表明,在三副本条件下的块存储服务写性能甚至达不到硬盘自身性能的1/3。
针对 FileStore的缺陷,Ceph社区于2015年重新开发了BlueStore。两种存储后端的逻 辑结构如图所示。BlueStore通过直接管理裸设备,缩短了IO 路径。Ceph社区设计了一个简化的文件系统 BlueFS,该文件系统绕过了本地文件系统层,解决了文件系统层次结构遍历效率低的问题。它通过使用KV索引来存储元数据,严格分离元数据和数据,提高了索引效率。这些改进解决了日志“双写”的问题,带来了较大的读写性能提升。
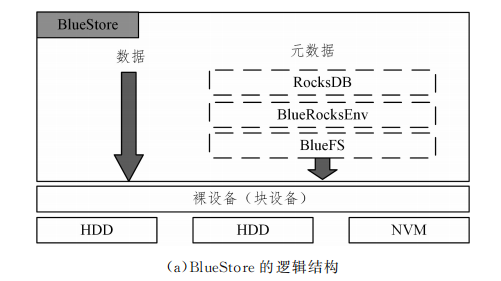
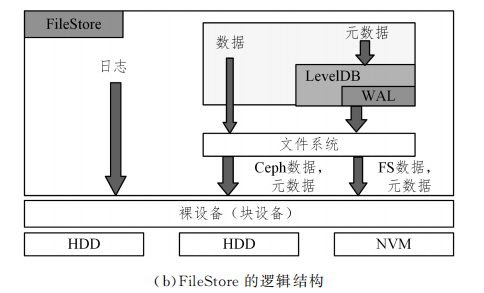
虽然BlueStore在设计时考虑了与SSD及 NVMeSSD闪 存的适配,但其对新硬件或混合存储的支持不佳。除此之外,BlueStore的设计也存在一些问题,如数据和元数据被存储在不同的位置,元数据结构和IO逻辑都较复杂,在IO较小的情况下可能存在双写问题,同时元数据占用内存较大。
闪存盘在写入前需要将原有数据擦除。现有的NVMe设备并未记录哪些地址在写入前需要被擦除,因此导致设备内部的垃圾回收效率低下。原则上,异步的垃圾回收可以提高写入效率,若不修改磁盘布局则垃圾回收的粒度较小,但 是实际上该操作在设备和中间层实现的效果并不佳。针对闪存盘的特点,Ceph社区提出了一种新的磁盘布局方式 SeaStore,该布局在较高层次的驱动上进行垃圾回收。其基本思想是将设备空间分为多个空闲段,每个段的大小为100MB 到10GB,所有数据顺序地被流式传输到设备的段上,在删除数据时仅做标记不进行垃圾回收,当段中的利用率降低至某个利用率阈值时,会将其中的数据移到另一个段中。
清理工作和写入工作混合在一起,以避免写延迟的波动。当数据全部清理完成后就丢弃整个段,设备可以擦除和回收这个段。SeaStore主要应用于NVMe设备,使用 SeaStore框架进行基于未来规划模型的编程方式来实现 run-to-completion模型,当其与SPDK 和 DPDK结合使用时,可以在网络消息层实现读写路径上的零(最小)拷贝。目前该 存储引擎还在开发中,性能提升效果尚不明确。
国内的深信服公司设计了一个基于 SPDK的用户态本地存储引擎——PFStore来满足高性能分布式存储的需求,对数据使用追加写的方式,将元数据修改增量写入日志,在后 期定时刷盘时再把数据写入RocksDB中。另外,该引擎启动多个实例来分别管理SSD的不同分区,启动多个 OSD来提升性能的方法。
近几年,随着Openchannel SSD、3DXPoint、非易失内存、 SMR等新型硬件的成熟和市场,出现了一些针对特定硬件的存储后端优化技术,我们将在下一次内容中详细介绍面向新型硬件的优化技术。
转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。
推荐阅读
更多架构相关技术知识总结请参考“架构师全店铺技术资料打包”相关电子书(37本技术资料打包汇总详情可通过“阅读原文”获取)。
全店内容持续更新,现下单“全店铺技术资料打包(全)”,后续可享全店内容更新“免费”赠阅,价格仅收198元(原总价350元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。
