
这个txt文档每章后面都有个这个特殊字符,如何提取出来删除掉?
回复“书籍”即可获赠Python从入门到进阶共10本电子书
一、前言
前几天在Python白银交流群【Python狗】问了一个Python正则表达式处理的问题,提问截图如下:
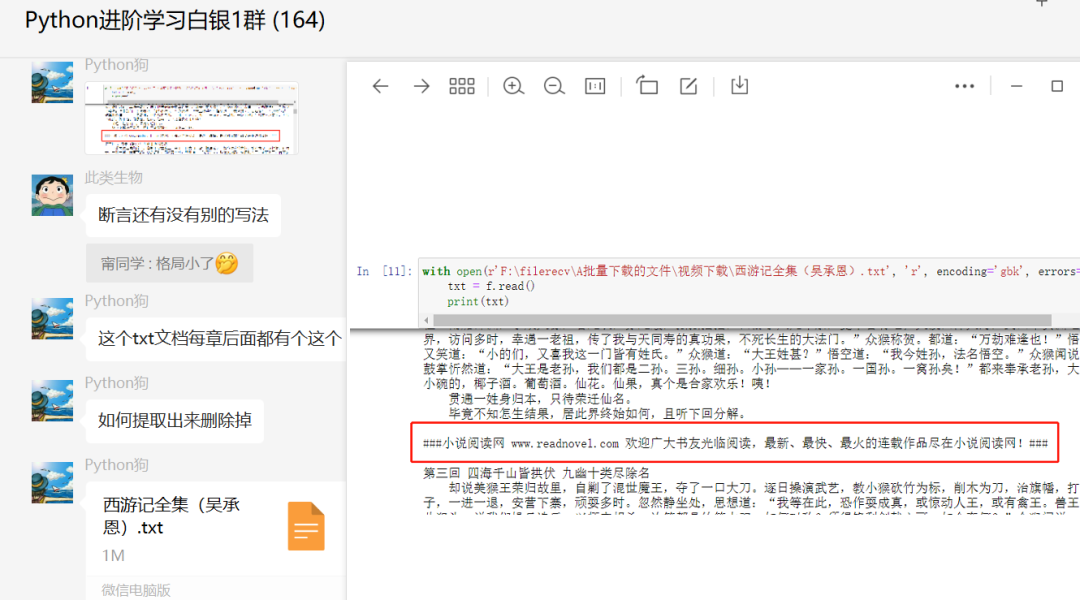
如果我是他的话,我会直接一步到位,使用notepad++打开文件,然后调出替换界面,全部替换即可,不需要代码实现也欧克的。不过这里使用Python的方式进行实现,一起来看看吧!
二、实现过程
这里【瑜亮老师】给了一份代码,如下所示:
import re
filename = '西游记全集(吴承恩).txt'
with open(filename, 'r', encoding='gbk') as f:
data = f.read()
result = re.sub(r'\#.*?\#', '', data)
with open(filename, 'w', encoding='gbk') as f2:
f2.write(result)
代码截图:

如果仅仅是粉丝截图发的那些需要替换的话,上面的代码是完全可以满足需求的,不过后来他又新增了一个新需求。
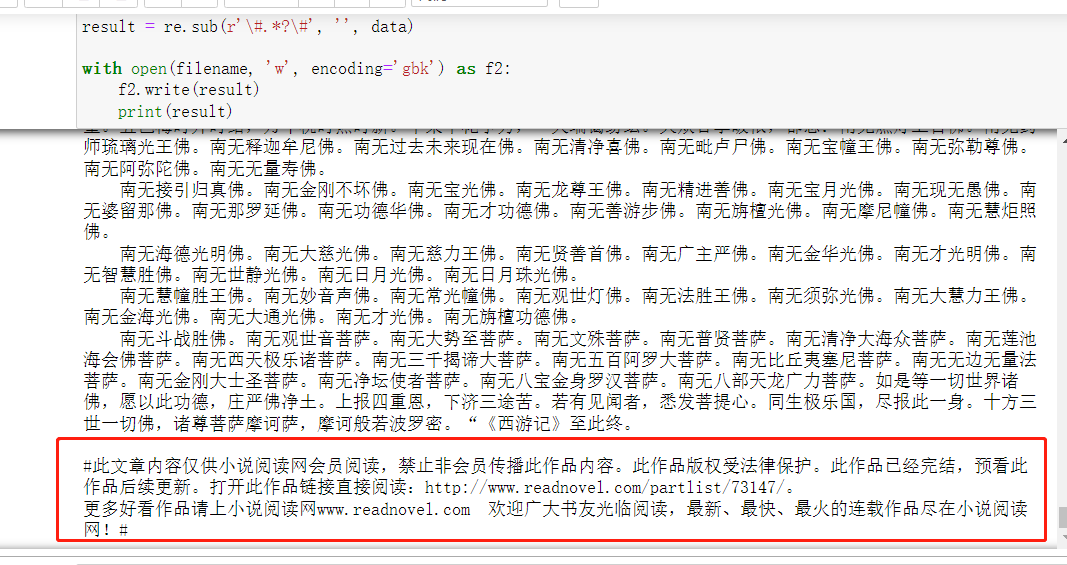
能不能把范围扩大点把最后的这个也匹配进去?答案在下面了。
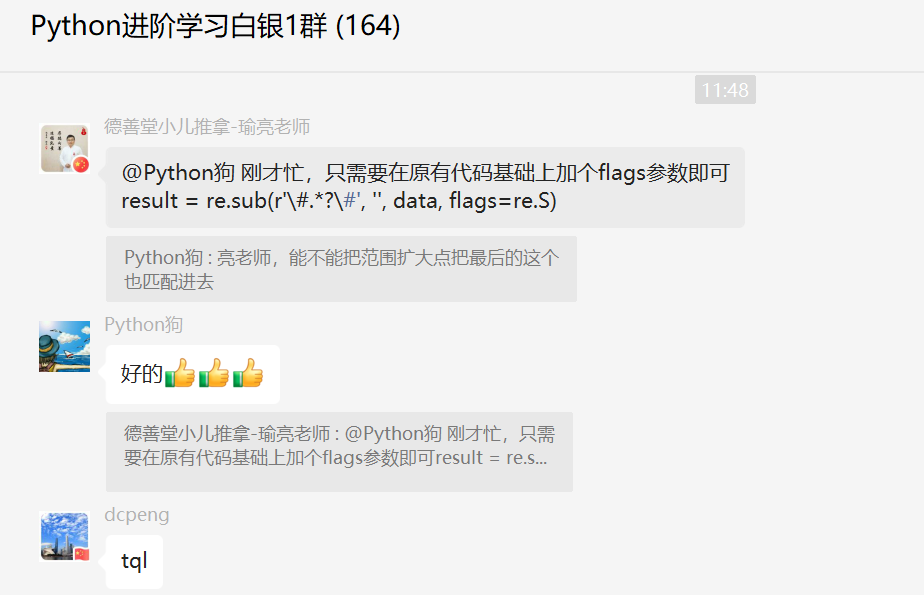
加参数,匹配换行。使用re.S参数以后,正则表达式会将这个字符串作为一个整体,将\n当做一个普通的字符加入到这个字符串中,在整体中进行匹配。
三、总结
大家好,我是Python进阶者。这篇文章主要盘点了一个Python正则表达式处理的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【Python狗】提问,感谢【瑜亮老师】给出的思路和代码解析,感谢【dcpeng】等人参与学习交流。
大家在学习过程中如果有遇到问题,欢迎随时联系我解决(我的微信:pdcfighting),应粉丝要求,我创建了一些高质量的Python付费学习交流群,欢迎大家加入我的Python学习交流群!

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~