
LSP,强得离谱!
大家好,我是 Jack。
LSP ,全称是 Live Speech Portraits,实时肖像演讲,简称 LSP。
想歪的,跟我一起面壁。
这个 LSP 可不简单,是一个比较新的算法。
功能是,根据声音,驱动人的头像说话,满足实时性要求。
我们直接看效果吧。
女生版:
男生版:
左下角是说话的人,上面是被驱动说话的画面。
虽然画面有时,看起来略显生硬,不过已经进步很多了。
再结合上两天发过的,AI 声音模仿算法。
声音模仿算法 + LSP 算法。。技术再发展发展,着实需要当心了。
我能做的就是,做好科普,让大家都了解这些新技术。
LSP
算法原理
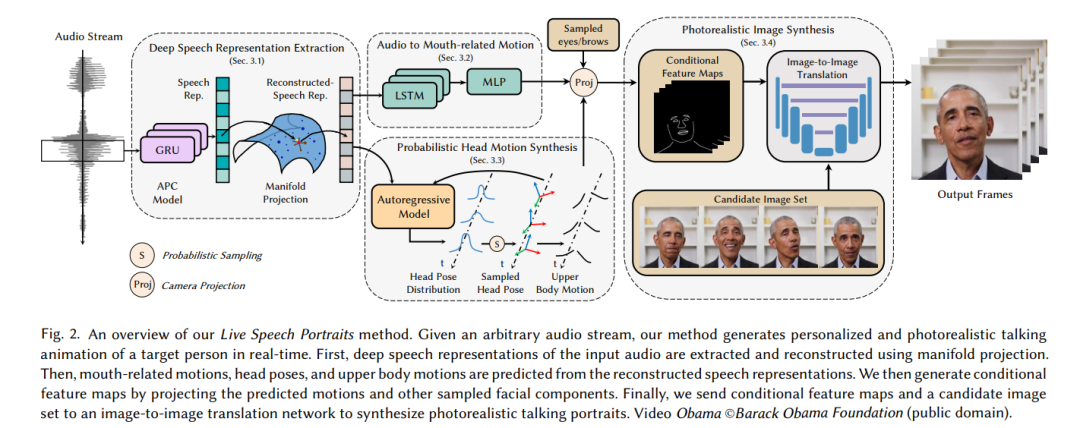
LSP 由南京大学 Yuanxun Lu 等人发表。
LSP 算法的实现整体分为四个阶段:
Deep Speech Eepresentation Extraction
采用深度神经网络,提取音频特征和流形投影,将这些特征投射到目标人的语音空间。
Audio to Mouth-related Motion
根据音频特征中学习面部的运动,用的是 LSTM 和 MLP。
Probabilistic Head Motion Synthesis
根据音频特征,预测头部姿势,上半身的运动。
Photorealistic Image Synthesis
根据前几个阶段的结果,生成条件特征图,然后使用 Image to Image 算法进行驱动,生成真实的面部细节,包括皱纹、牙齿等。
更详细的算法原理,可以直接看论文:
https://yuanxunlu.github.io/projects/LiveSpeechPortraits/resources/SIGGRAPH_Asia_2021__Live_Speech_Portraits__Real_Time_Photorealistic_Talking_Head_Animation.pdf
算法测试
LSP 算法已经开源,项目地址:
https://github.com/YuanxunLu/LiveSpeechPortraits
LSP 的开发环境配置起来也不麻烦,安装个 ffmpeg,其它第三方库按照 requirements.txt 安装即可。
权重文件放在了 Google 云盘,2G 左右的文件,考虑到很多小伙伴下载不方便。
我帮大家下载好了,公众号后台回复「lsp」即可获取。
将下载好的内容,拷贝到项目的 data 目录下即可。
运行如下指令:
python demo.py --id May --driving_audio ./data/Input/00083.wav --device cuda
根据指定的音频文件,进行驱动,我们可以替换这个音频。
生成的结果放在 results 目录下。
最后
感兴趣的小伙伴可以试试这个算法。
哦,对了,说个题外话,最近看不少读者在学 Python,所以出了一期视频。
B 站视频已发,我花费了大量精力整理的 Python 学习路线,全面的知识点,包含每个阶段的学习目标和学习资料,一些我看过的视频、书籍、网站、文档的推荐。
Python 学习路线一条龙,自学编程不迷茫,有需要的可以去看下:
https://www.bilibili.com/video/BV1Xf4y1j7Np
好了,就说这么多吧,我是 Jack,我们下期见!
