
一文了解滴滴与蚂蚁金服开源共建的SQLFlow
导读:SQFlow利用SQL语言构建机器学习和深度学习,致力于“Make AI as simple as SQL”,愿景是推进人工智能大众化、普及化,也就是只要懂商业逻辑就能用上人工智能,让懂业务的人能自由地使用人工智能。本文带你快速了解开源的工程化的自助式数据科学平台SQLFlow。
SQLFlow利用SQL语言构建机器学习和深度学习,致力于“Make AI as simple as SQL”,愿景是推进人工智能大众化、普及化,也就是只要懂商业逻辑就能用上人工智能,让懂业务的人能自由地使用人工智能。SQLFlow具备三大核心要素,即数据描述商业逻辑、AI赋能深度数据分析和易于使用。
SQLFlow致力于帮助业务提升效能,SQLFLow支持的模型库较为丰富,主要模型包括DNN神经网络预测模型、Shap+XGBoost可解读模型、基于自编码器的无监督聚类模型、基于LSTM的时间序列模型等,更多详细内容可查看SQLFlow官方模型库,地址:https://github.com/sql-machine-learning/models。
人工智能作为近10年里极具代表性的技术突破,已经广泛应用于各行各业。无论是图像处理技术在安全监控、自动驾驶领域内的成功落地, 还是自然语言处理技术在智能客服、内容生成等领域获得的巨大进步, 都预示着人工智能将在未来给社会的发展带来无限可能。
与此同时,在人工智能落地的过程中也面临着一系列实际问题,最常见的就是相关人才需要极为丰富的知识储备,例如高等数学、统计学、概率论以及熟练的编程技能。与此同时,在知识和技能相互融合的过程中还需要对业务逻辑拥有深度理解,才可以保证技术能够带来真实可靠的业务提升。
这些要求无疑提高了人工智能赋能业务的门槛,同时也制约了人工智能产业的发展速度。SQLFlow正是为了解决上述问题诞生的,它容易上手,方便使用,支持多种数据来源和机器学习框架,能够快速地将想法落地,成为开发者的开发利器。
SQLFlow是由滴滴数据科学团队和蚂蚁金服合作开源的一款连接数据和机器学习能力的分析工具,旨在抽象出从数据到模型的研发过程,同时配合底层的引擎适配及自动优化技术,使得具备基础SQL知识的技术人员也可以完成大部分的机器学习模型训练、预测及应用任务。
SQLFlow希望通过简化和优化整个研发过程将机器学习的能力赋予业务专家,从而推动更多的人工智能应用场景被探索和使用。
将SQL与AI进行连接的这个想法并非SQLFlow独创。Google在2018年发布的BigQueryML、TeraData的SQL for DL以及微软基于SQL Server的AI扩展,同样旨在打通数据与人工智能之间的连接障碍,使数据科学家和分析师能够通过SQL语言实现机器学习功能并完成数据预测和分析任务。
与上述各个系统不同的是,SQLFlow着力于连接更广泛的数据引擎和人工智能技术框架,并不局限于某个公司产品内的封闭技术。更为重要的是,SQLFlow是一个面向全世界开发者的开源项目,只要是对这一领域感兴趣的开发者都可以参与其中,项目的组织者希望借助开发者和使用者的力量共同建设社区,促进这一领域的健康发展。
作为连接数据引擎和AI引擎的桥梁,SQLFlow目前支持的数据引擎包括MySQL、Hive和MaxCompute,支持的AI引擎不仅包括业界流行的TensorFlow,还包括XGBoost、Scikit-Learn等传统机器学习框架,如下表所示。
表 SQLFlow支持的数据引擎和AI引擎简介


接下来我们使用Docker镜像中的Iris案例来说明SQLFlow的工作原理。
Iris数据集也称为鸢尾花数据集,是机器学习领域常用的分类实验数据集。该数据集包含150个数据样本,分为3类,每类包含50个样例,每条样例包含花萼长度、花萼宽度、花瓣长度和花瓣宽度。数据集通过这4个属性判断鸢尾花样例属于山鸢尾(setosa)、杂色鸢尾(versicolour)、维吉尼亚鸢尾(virginica)中的哪一类。
我们预先将数据存储至iris.train表中,前4列表示训练样例的特征,最后一列代表训练样本的标签。
分类模型以DNN分类器为例。DNN分类器默认具有双隐藏层,每层的隐藏节点数均为10,分类数为3,默认优化器和学习率分别为Adagrad和0.1,损失函数则默认配置为tf.keras.losses.sparse_categorical_crossentropy。
从iris.train表中获取数据并训练对应DNN分类器模型的训练语句如代码清单1所示。
代码清单1 基于iris数据集训练DNN分类器SELECT * FROM iris.trainTO TRAIN DNNClassiferWITH hidden_units = [10, 10], n_classes = 3, EPOCHS = 10COLUMN sepal_length, sepal_width, petal_length, petal_widthLABEL classINTO sqlflow_models.my_dnn_model;
SQLFlow解析接收到的SQL命令,其中SELECT语句传递给对应数据引擎获取数据,而TRAIN和WITH语句则分别指定了使用的模型种类、模型结构和训练所需的超参数,COLUMN和LABEL部分分别用于训练的各特征列名称和标签列名称。
SQLFlow将TRAIN和WITH语句中的内容解析为对应的Python程序,整体流程如下图所示。
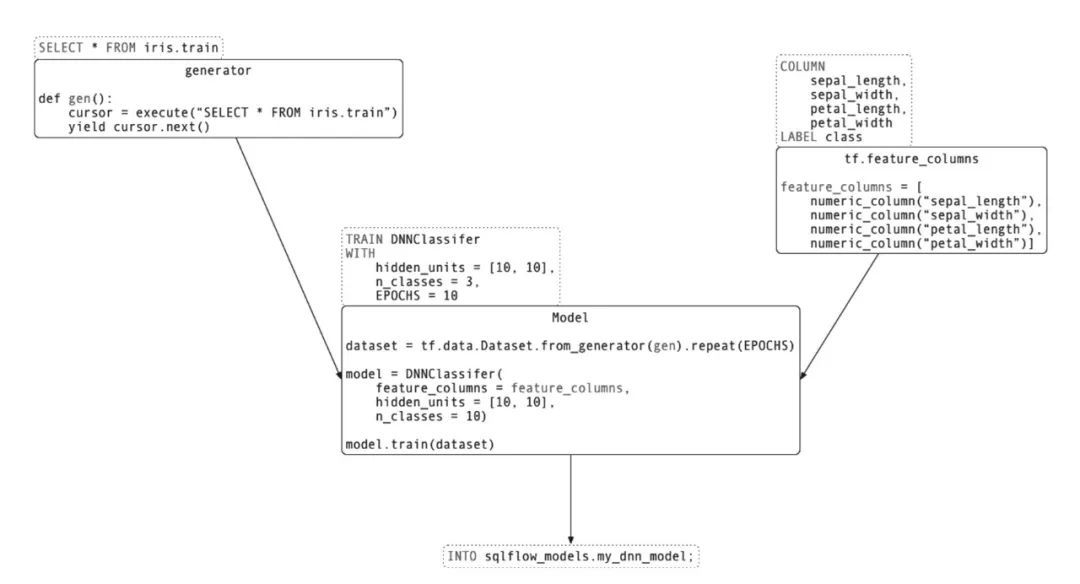
图 SQLFlow工作原理
本文摘编于《数据科学工程实践》,经出版方授权发布。
推荐阅读
(点击标题可跳转阅读)
《机器学习暑期前沿学校》课程视频及ppt分享
下载 | 经典著作《机器学习:概率视角》.pdf
【小抄】机器学习常见知识点总结(2021)
从贝叶斯定理到概率分布:详解概率论老铁,三连支持一下,好吗?↓↓↓