
Hudi 集成 | 超详细步骤!整合 Apache Hudi + Flink + CDH

1. 环境准备
各组件版本如下
Flink 1.13.1
Hudi 0.10
Hive 2.1.1
CDH 6.3.0
Kafka 2.2.1
1.1 Hudi 代码下载编译
下载代码至本地
steven@wangyuxiangdeMacBook-Pro ~ git clone https://github.com/apache/hudi.gitCloning into 'hudi'...remote: Enumerating objects: 122696, done.remote: Counting objects: 100% (5537/5537), done.remote: Compressing objects: 100% (674/674), done.remote: Total 122696 (delta 4071), reused 4988 (delta 3811), pack-reused 117159Receiving objects: 100% (122696/122696), 75.85 MiB | 5.32 MiB/s, done.Resolving deltas: 100% (61608/61608), done.
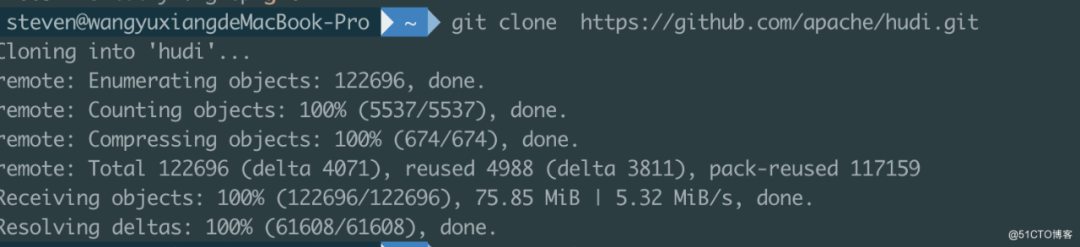
使用Idea打开Hudi项目,更改packging/hudi-flink-bundle的pom.xml文件,修改flink-bundle-shade-hive2 profile下的hive-version为chd6.3.0的版本
使用命令进行编译
mvn clean install -DskipTests -DskipITs -Dcheckstyle.skip=true -Drat.skip=true -Dhadoop.version=3.0.0 -Pflink-bundle-shade-hive2注意:
1.因为chd6.3.0使用的是hadoop3.0.0,所以要指定hadoop的版本2.使用hive2.1.1的版本,也要指定hive的版本,不然使用sync to hive的时候会报类的冲突问题

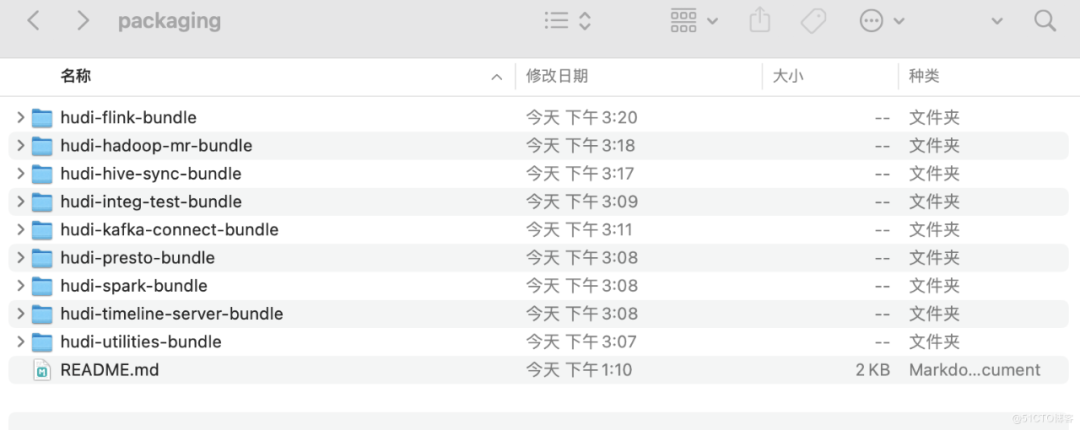
在packaging下面各个组件中编译成功的jar包
将hudi-flink-bundle_2.11-0.10.0-SNAPSHOT.jar放到flink1.13.1的lib目录下可以开启Hudi数据湖之旅了。
1.2 配置Flink On Yarn模式
flink-conf.yaml的配置文件如下
execution.target: yarn-per-job#execution.target: localexecution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION#进行checkpointing的间隔时间(单位:毫秒)execution.checkpointing.interval: 30000execution.checkpointing.mode: EXACTLY_ONCE#execution.checkpointing.prefer-checkpoint-for-recovery: trueclassloader.check-leaked-classloader: falsejobmanager.rpc.address: dbos-bigdata-test005# The RPC port where the JobManager is reachable.jobmanager.rpc.port: 6123akka.framesize: 10485760bjobmanager.memory.process.size: 1024mtaskmanager.heap.size: 1024mtaskmanager.numberOfTaskSlots: 1# The parallelism used for programs that did not specify and other parallelism.parallelism.default: 1env.java.home key: /usr/java/jdk1.8.0_181-clouderahigh-availability: zookeeperhigh-availability.storageDir: hdfs:///flink/ha/high-availability.zookeeper.quorum: dbos-bigdata-test003:2181,dbos-bigdata-test004:2181,dbos-bigdata-test005:2181state.backend: filesystem# Directory for checkpoints filesystem, when using any of the default bundled# state backends.#state.checkpoints.dir: hdfs://bigdata/flink-checkpointsjobmanager.execution.failover-strategy: regionenv.log.dir: /tmp/flinkhigh-availability.zookeeper.path.root: /flink
配置Flink环境变量
vim /etc/profile以下是环境变量,根据自己的版本进行更改#set default jdk1.8 envexport JAVA_HOME=/usr/java/jdk1.8.0_181-clouderaexport JRE_HOME=/usr/java/jdk1.8.0_181-cloudera/jreexport CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/libexport HADOOP_CONF_DIR=/etc/hadoop/confexport HADOOP_CLASSPATH=`hadoop classpath`export HBASE_CONF_DIR=/etc/hbase/confexport FLINK_HOME=/opt/flinkexport HIVE_HOME=/opt/cloudera/parcels/CDH-6.3.0-1.cdh6.3.0.p0.1279813/lib/hiveexport HIVE_CONF_DIR=/etc/hive/confexport M2_HOME=/usr/local/maven/apache-maven-3.5.4export CANAL_ADMIN_HOME=/data/canal/adminexport CANAL_SERVER_HOME=/data/canal/deployerexport PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin:${FLINK_HOME}/bin:${M2_HOME}/bin:${HIVE_HOME}/bin:${CANAL_SERVER_HOME}/bin:${CANAL_ADMIN_HOME}/bin:$PATH
检查Flink是否正常

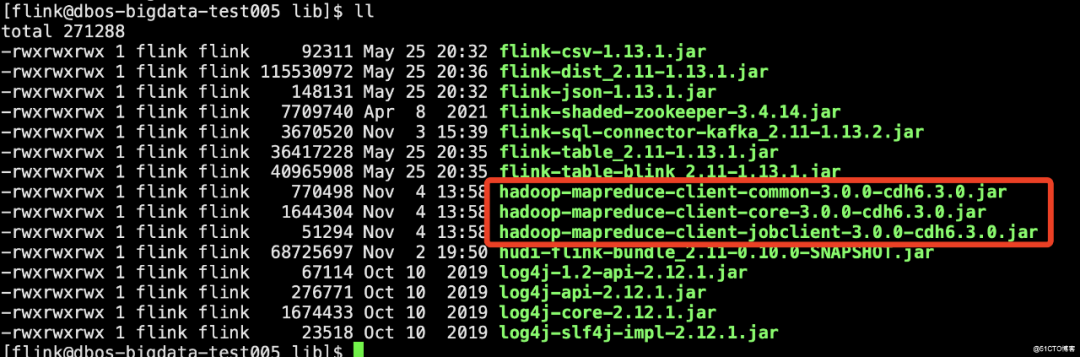
Hudi编译好的jar包和kafka的jar包放到Flink的lib目录下
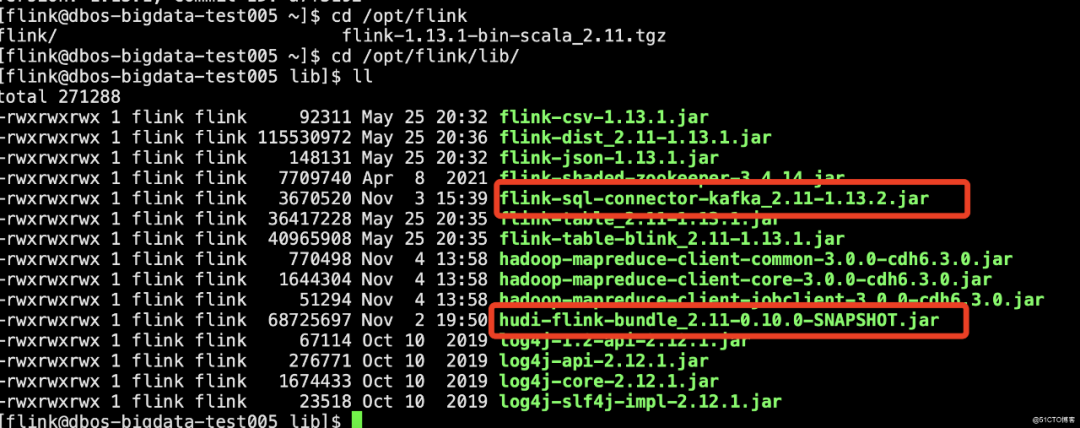
以下三个包也要放到Flink的lib下,否则同步数据到Hive时会报错
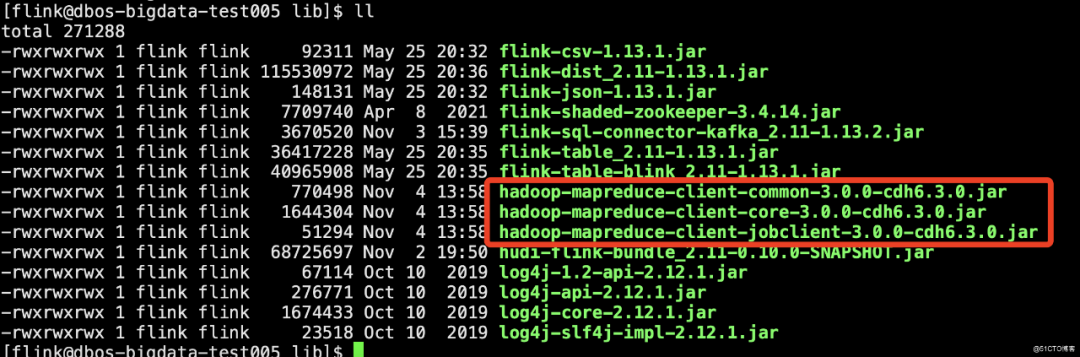
1.3 部署同步到Hive的环境
将hudi-hadoop-mr-bundle-0.10.0-SNAPSHOT.jar包放入到以下路径
[flink@dbos-bigdata-test005 jars]$ pwd/opt/cloudera/parcels/CDH-6.3.0-1.cdh6.3.0.p0.1279813/jars


进入到hive lib目录,每一台hive节点都要放置jar包
[flink@dbos-bigdata-test005 lib]$ pwd/opt/cloudera/parcels/CDH-6.3.0-1.cdh6.3.0.p0.1279813/lib/hive/lib//建立软链接[flink@dbos-bigdata-test005 lib]$ ln -ls ../../../jars/hudi-hadoop-mr-bundle-0.10.0-SNAPSHOT.jar hudi-hadoop-mr-bundle-0.10.0-SNAPSHOT.jar

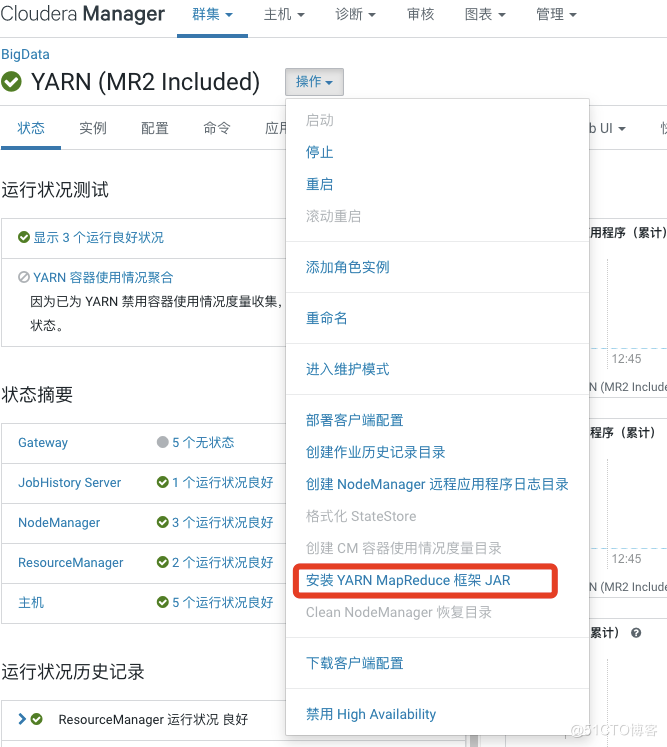
1.4. 安装 YARN MapReduce 框架 JAR
进入平台操作,安装YARN MapReduce框架JAR
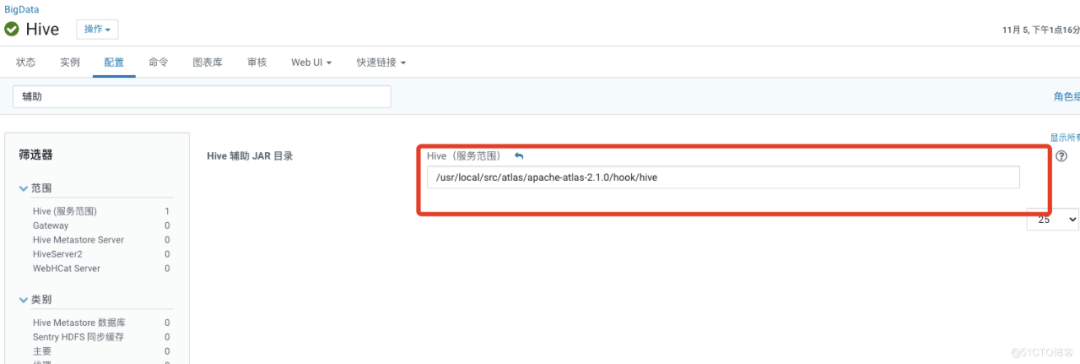
设置Hive辅助JAR目录
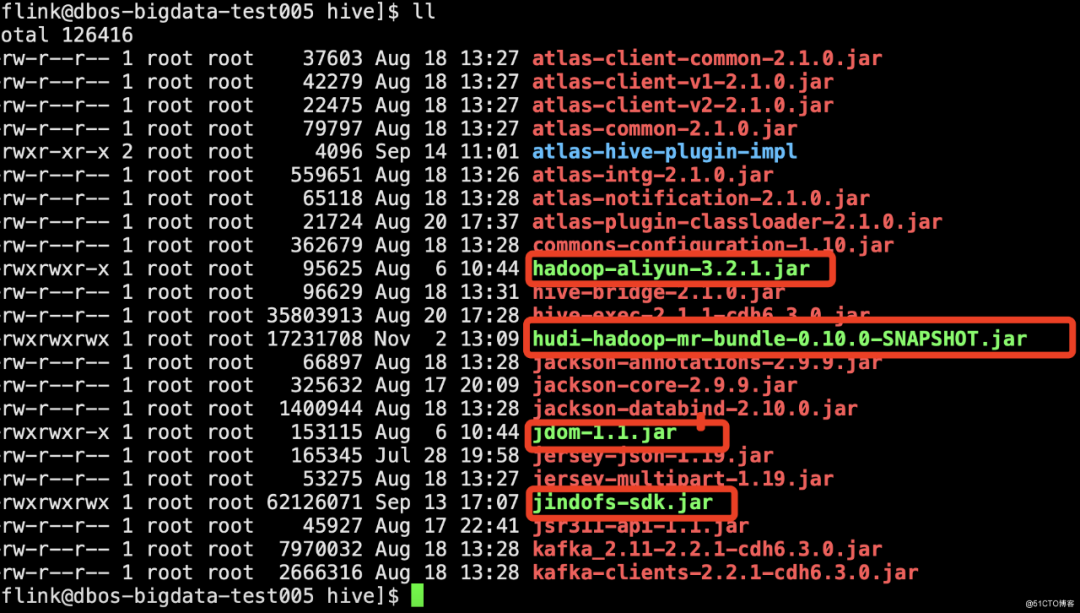
因为后面考虑到hudi的数据存到oss,所以要放这几个包进来(关于oss的配置详细可参考oss配置文档)
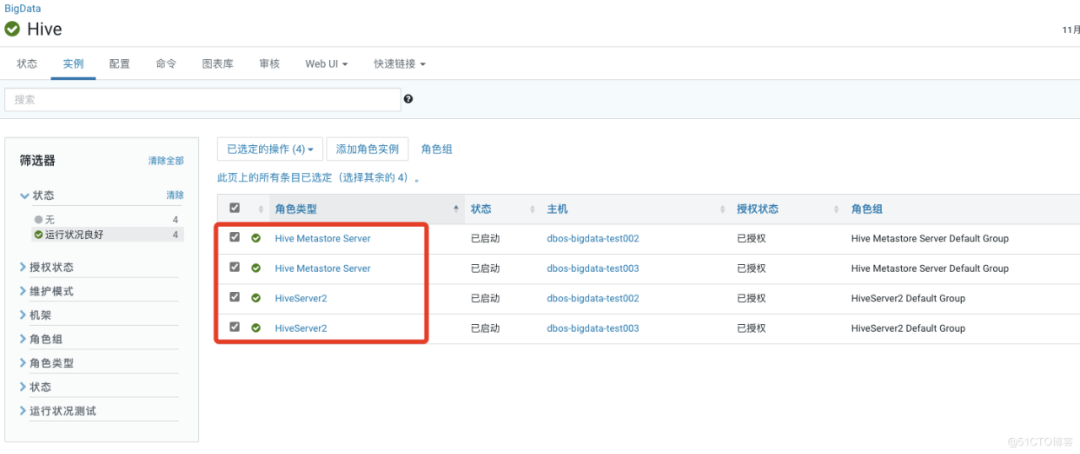
重启Hive,使配置生效
2. 测试demo
创建kafka数据
//创建topickafka-topics --zookeeper dbos-bigdata-test003:2181,dbos-bigdata-test004:2181,dbos-bigdata-test005:2181/kafka --create --partitions 4 --replication-factor 3 --topic test//删除topickafka-topics --zookeeper dbos-bigdata-test003:2181,dbos-bigdata-test004:2181,dbos-bigdata-test005:2181/kafka --delete --topic test//生产数据kafka-console-producer --broker-list dbos-bigdata-test003:9092,dbos-bigdata-test004:9092,dbos-bigdata-test005:9092 --topic test//直接复制数据{"tinyint0": 6, "smallint1": 223, "int2": 42999, "bigint3": 429450, "float4": 95.47324181659323, "double5": 340.5755392968011,"decimal6": 111.1111, "boolean7": true, "char8": "dddddd", "varchar9": "buy0", "string10": "buy1", "timestamp11": "2021-09-13 03:08:50.810"}
启动flink-sql
[flink@dbos-bigdata-test005 hive]$ cd /opt/flink[flink@dbos-bigdata-test005 flink]$ lltotal 496drwxrwxr-x 2 flink flink 4096 May 25 20:36 bindrwxrwxr-x 2 flink flink 4096 Nov 4 17:22 confdrwxrwxr-x 7 flink flink 4096 May 25 20:36 examplesdrwxrwxr-x 2 flink flink 4096 Nov 4 13:58 lib-rw-r--r-- 1 flink flink 11357 Oct 29 2019 LICENSEdrwxrwxr-x 2 flink flink 4096 May 25 20:37 licensesdrwxr-xr-x 2 flink flink 4096 Jan 30 2021 log-rw-rw-r-- 1 flink flink 455180 May 25 20:37 NOTICEdrwxrwxr-x 3 flink flink 4096 May 25 20:36 optdrwxrwxr-x 10 flink flink 4096 May 25 20:36 plugins-rw-r--r-- 1 flink flink 1309 Jan 30 2021 README.txt[flink@dbos-bigdata-test005 flink]$ ./bin/sql-client.sh
执行Hudi的Demo语句
Hudi 表分为 COW 和 MOR两种类型COW 表适用于离线批量更新场景,对于更新数据,会先读取旧的 base file,然后合并更新数据,生成新的 base file。MOR 表适用于实时高频更新场景,更新数据会直接写入 log file 中,读时再进行合并。为了减少读放大的问题,会定期合并 log file 到 base file 中。
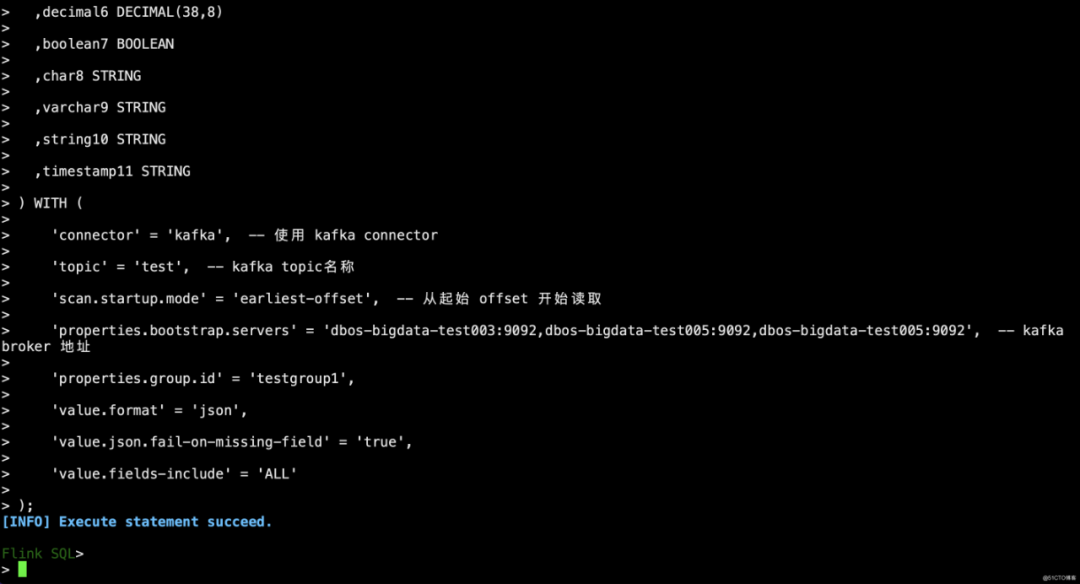
//创建source表CREATE TABLE k (tinyint0 TINYINT,smallint1 SMALLINT,int2 INT,bigint3 BIGINT,float4 FLOAT,double5 DOUBLE,decimal6 DECIMAL(38,8),boolean7 BOOLEAN,char8 STRING,varchar9 STRING,string10 STRING,timestamp11 STRING) WITH ('connector' = 'kafka', -- 使用 kafka connector'topic' = 'test', -- kafka topic名称'scan.startup.mode' = 'earliest-offset', -- 从起始 offset 开始读取'properties.bootstrap.servers' = 'dbos-bigdata-test003:9092,dbos-bigdata-test005:9092,dbos-bigdata-test005:9092', -- kafka broker 地址'properties.group.id' = 'testgroup1','value.format' = 'json','value.json.fail-on-missing-field' = 'true','value.fields-include' = 'ALL');
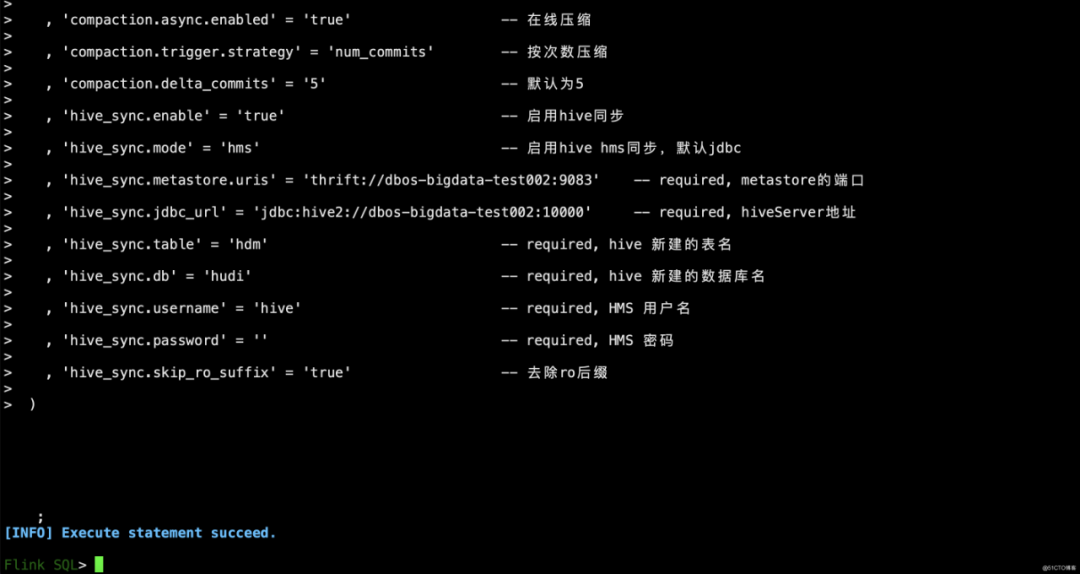
// 创建Hudi(cow)sink表CREATE TABLE hdm(tinyint0 TINYINT,smallint1 SMALLINT,int2 INT,bigint3 BIGINT,float4 FLOAT,double5 DOUBLE,decimal6 DECIMAL(12,3),boolean7 BOOLEAN,char8 CHAR(64),varchar9 VARCHAR(64),string10 STRING,timestamp11 TIMESTAMP(3))PARTITIONED BY (tinyint0)WITH ('connector' = 'hudi', 'path' = 'hdfs://bigdata/hudi/hdm', 'hoodie.datasource.write.recordkey.field' = 'char8' -- 主键, 'write.precombine.field' = 'timestamp11' -- 相同的键值时,取此字段最大值,默认ts字段, 'write.tasks' = '1', 'compaction.tasks' = '1', 'write.rate.limit' = '2000' -- 限制每秒多少条, 'compaction.async.enabled' = 'true' -- 在线压缩, 'compaction.trigger.strategy' = 'num_commits' -- 按次数压缩, 'compaction.delta_commits' = '5' -- 默认为5, 'hive_sync.enable' = 'true' -- 启用hive同步, 'hive_sync.mode' = 'hms' -- 启用hive hms同步,默认jdbc, 'hive_sync.metastore.uris' = 'thrift://dbos-bigdata-test002:9083' -- required, metastore的端口, 'hive_sync.jdbc_url' = 'jdbc:hive2://dbos-bigdata-test002:10000' -- required, hiveServer地址, 'hive_sync.table' = 'hdm' -- required, hive 新建的表名, 'hive_sync.db' = 'hudi' -- required, hive 新建的数据库名, 'hive_sync.username' = 'hive' -- required, HMS 用户名, 'hive_sync.password' = '' -- required, HMS 密码, 'hive_sync.skip_ro_suffix' = 'true' -- 去除ro后缀);// 创建Hudi(mor)sink表CREATE TABLE hdm(tinyint0 TINYINT,smallint1 SMALLINT,int2 INT,bigint3 BIGINT,float4 FLOAT,double5 DOUBLE,decimal6 DECIMAL(12,3),boolean7 BOOLEAN,char8 CHAR(64),varchar9 VARCHAR(64),string10 STRING,timestamp11 TIMESTAMP(3))PARTITIONED BY (tinyint0)WITH ('connector' = 'hudi', 'path' = 'hdfs://bigdata/hudi/hdm', 'hoodie.datasource.write.recordkey.field' = 'char8' -- 主键, 'write.precombine.field' = 'timestamp11' -- 相同的键值时,取此字段最大值,默认ts字段, 'write.tasks' = '1', 'compaction.tasks' = '1', 'write.rate.limit' = '2000' -- 限制每秒多少条, 'table.type' = 'MERGE_ON_READ' -- 默认COPY_ON_WRITE, 'compaction.async.enabled' = 'true' -- 在线压缩, 'compaction.trigger.strategy' = 'num_commits' -- 按次数压缩, 'compaction.delta_commits' = '5' -- 默认为5, 'hive_sync.enable' = 'true' -- 启用hive同步, 'hive_sync.mode' = 'hms' -- 启用hive hms同步,默认jdbc, 'hive_sync.metastore.uris' = 'thrift://dbos-bigdata-test002:9083' -- required, metastore的端口, 'hive_sync.jdbc_url' = 'jdbc:hive2://dbos-bigdata-test002:10000' -- required, hiveServer地址, 'hive_sync.table' = 'hdm' -- required, hive 新建的表名, 'hive_sync.db' = 'hudi' -- required, hive 新建的数据库名, 'hive_sync.username' = 'hive' -- required, HMS 用户名, 'hive_sync.password' = '' -- required, HMS 密码, 'hive_sync.skip_ro_suffix' = 'true' -- 去除ro后缀);
// 插入source数据insert into hdmselectcast(tinyint0 as TINYINT), cast(smallint1 as SMALLINT), cast(int2 as INT), cast(bigint3 as BIGINT), cast(float4 as FLOAT), cast(double5 as DOUBLE), cast(decimal6 as DECIMAL(38,18)), cast(boolean7 as BOOLEAN), cast(char8 as CHAR(64)), cast(varchar9 as VARCHAR(64)), cast(string10 as STRING), cast(timestamp11 as TIMESTAMP(3))from k;
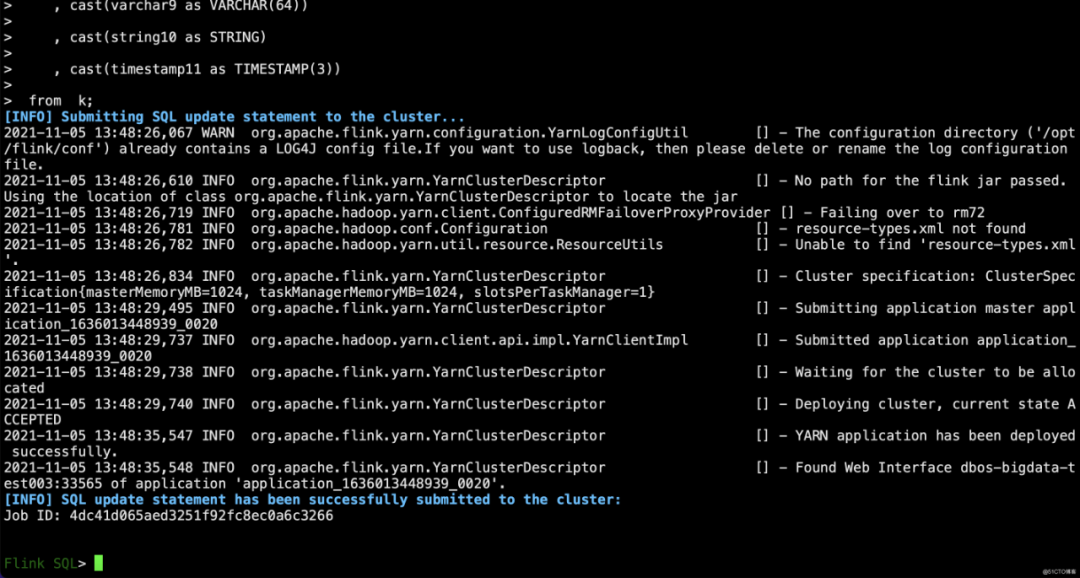
以上证明提交成功了,去yarn上查看作业状态
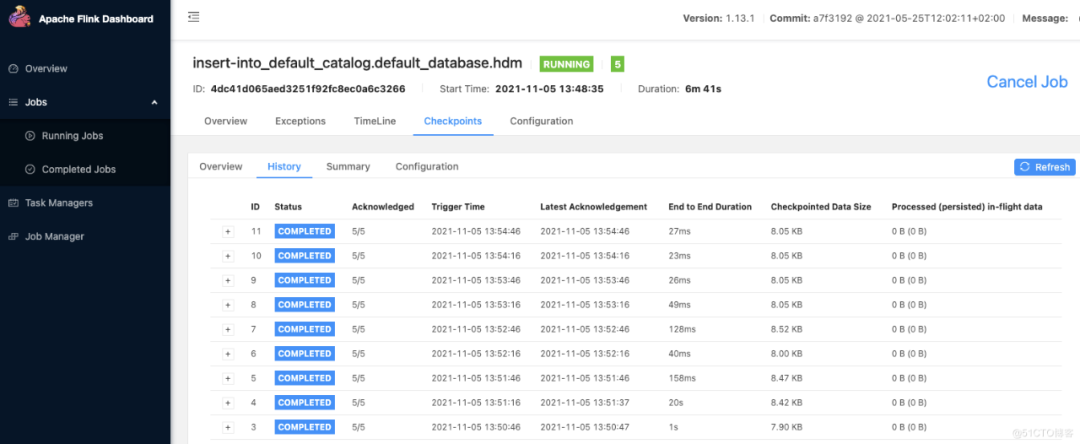
kafka正常消费了。
多几次往kafka里面造数据
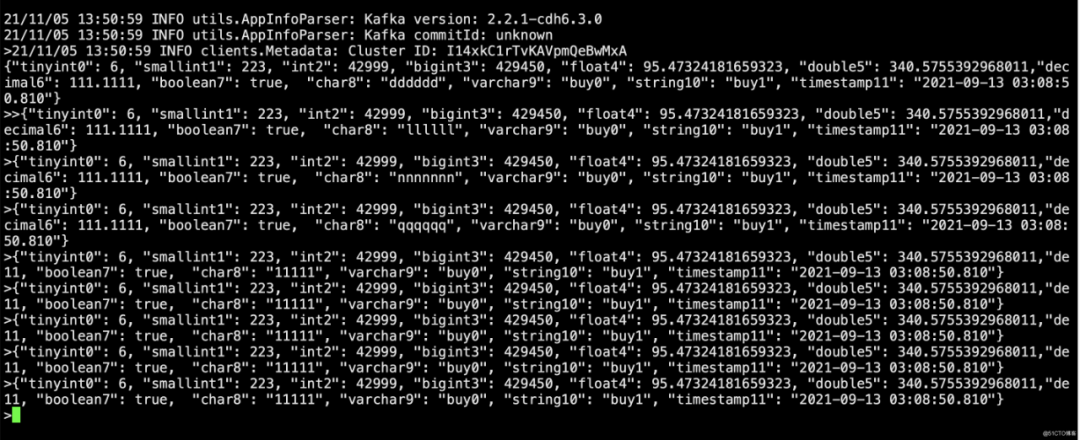
注意:要以char8更新,因为这个是primary key
查看Hudi里面是否生成parquet文件

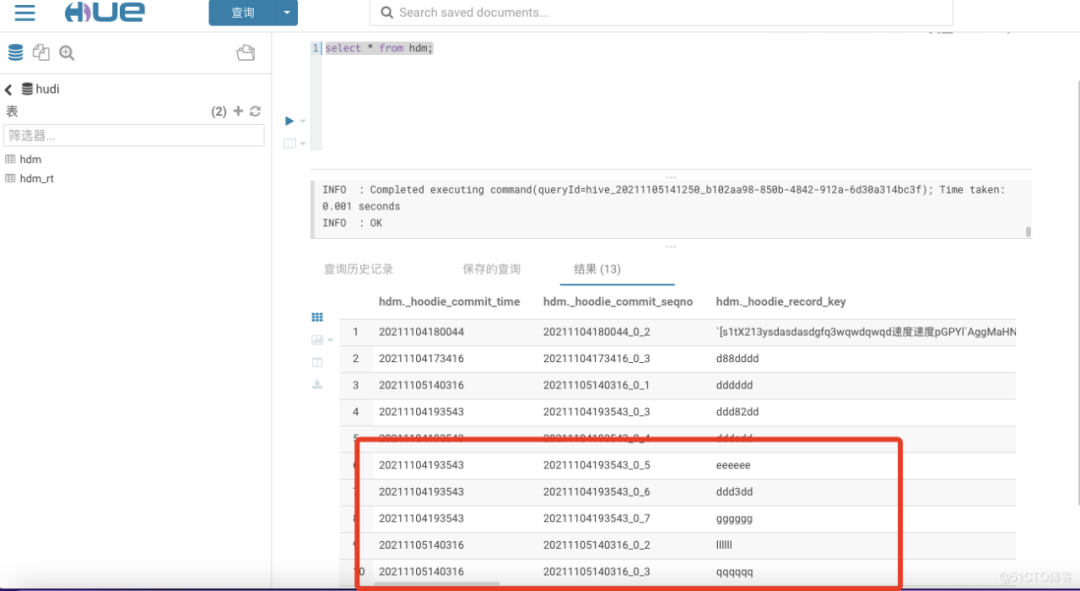
在hue上查看Hive中是否有数据同步过来,可以看到数据已经从Hudi中同步到Hive了。
3. FAQ
2021-11-04 16:17:29,687 ERROR org.apache.flink.runtime.entrypoint.ClusterEntrypoint [] - Could not start cluster entrypoint YarnJobClusterEntrypoint.org.apache.flink.runtime.entrypoint.ClusterEntrypointException: Failed to initialize the cluster entrypoint YarnJobClusterEntrypoint. at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.startCluster(ClusterEntrypoint.java:212) ~[flink-dist_2.11-1.13.1.jar:1.13.1] at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.runClusterEntrypoint(ClusterEntrypoint.java:600) [flink-dist_2.11-1.13.1.jar:1.13.1] at org.apache.flink.yarn.entrypoint.YarnJobClusterEntrypoint.main(YarnJobClusterEntrypoint.java:99) [flink-dist_2.11-1.13.1.jar:1.13.1] Caused by: org.apache.flink.util.FlinkException: Could not create the DispatcherResourceManagerComponent. at org.apache.flink.runtime.entrypoint.component.DefaultDispatcherResourceManagerComponentFactory.create(DefaultDispatcherResourceManagerComponentFactory.java:275) ~[flink-dist_2.11-1.13.1.jar:1.13.1] at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.runCluster(ClusterEntrypoint.java:250) ~[flink-dist_2.11-1.13.1.jar:1.13.1] at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.lambda$startCluster$1(ClusterEntrypoint.java:189) ~[flink-dist_2.11-1.13.1.jar:1.13.1] at java.security.AccessController.doPrivileged(Native Method) ~[?:1.8.0_181] at javax.security.auth.Subject.doAs(Subject.java:422) ~[?:1.8.0_181] at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875) ~[hadoop-common-3.0.0-cdh6.3.0.jar:?] at org.apache.flink.runtime.security.contexts.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41) ~[flink-dist_2.11-1.13.1.jar:1.13.1] at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.startCluster(ClusterEntrypoint.java:186) ~[flink-dist_2.11-1.13.1.jar:1.13.1] ... 2 more Caused by: java.net.BindException: Could not start rest endpoint on any port in port range 40631 at org.apache.flink.runtime.rest.RestServerEndpoint.start(RestServerEndpoint.java:234) ~[flink-dist_2.11-1.13.1.jar:1.13.1] at org.apache.flink.runtime.entrypoint.component.DefaultDispatcherResourceManagerComponentFactory.create(DefaultDispatcherResourceManagerComponentFactory.java:172) ~[flink-dist_2.11-1.13.1.jar:1.13.1] at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.runCluster(ClusterEntrypoint.java:250) ~[flink-dist_2.11-1.13.1.jar:1.13.1] at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.lambda$startCluster$1(ClusterEntrypoint.java:189) ~[flink-dist_2.11-1.13.1.jar:1.13.1] at java.security.AccessController.doPrivileged(Native Method) ~[?:1.8.0_181] at javax.security.auth.Subject.doAs(Subject.java:422) ~[?:1.8.0_181] at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875) ~[hadoop-common-3.0.0-cdh6.3.0.jar:?] at org.apache.flink.runtime.security.contexts.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41) ~[flink-dist_2.11-1.13.1.jar:1.13.1] at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.startCluster(ClusterEntrypoint.java:186) ~[flink-dist_2.11-1.13.1.jar:1.13.1] ... 2 more 解决方案:
需要把以下三个jar包放到flink的lib目录下即可
在线压缩策略没起之前占用内存资源,推荐离线压缩,但离线压缩需手动根据压缩策略才可触发
cow写少读多的场景 mor 相反
MOR表压缩在线压缩按照配置压缩,如压缩失败,会有重试压缩操作,重试压缩操作延迟一小时后重试
推荐阅读
Apache Kyuubi + Hudi在 T3 出行的深度实践
ByteLake:字节跳动基于Apache Hudi的实时数据湖平台