
几款VO数据转换工具性能剖析
前言
做后端开发的各位小伙伴应该对数据转换都不陌生,在实际开发中也肯定遇到过各种数据类型之间的转换,但是在数据转换的时候,往往是需要考虑性能问题的,特别是在大批量数据转换的时候更是如此,所以本着性能为王的原则,我们今天来评测几种数据转换方案,主要包括以下几种:
getter/setter手动赋值BeanUtilsBeanMap- 反射
我们先说结论,这几种方式性能排行依次是:getter/setter > 反射 > BeanMap > BeanUtil
数据转换
因为参与公司的重构项目,前段时间一直比较忙,工作重点主要是业务代码编写测试,最近稍微好一点,主要在做一些优化方面的工作,由于本次项目重构主要是为了解决性能问题,所以这次重构对性能的要求也稍微高一点,昨天在优化数据转换方案的时候,在自己的探索和不屑努力之下,终于找到了另外一种性能比较好的数据转换方案,所以今天我们的内容就是这几种数据转换方案的对比。
我们先看下两个需要进行转换的VO,首先是entity,类似于数据库查出来的数据:
public class UserEntity {
/**
* 用户 id
*/
private Long id;
/**
* 用户名
*/
private String userName;
/**
* 昵称
*/
private String nickName;
// 省略构造方法和getter/setter方法
}
然后是另一个,类似于需要给前端返回的数据:
public class UserVo {
/**
* 用户 id
*/
private Long id;
/**
* 用户名
*/
private String userName;
/**
* 昵称
*/
private String nickName;
// 省略构造方法和getter/setter方法
}
数据初始化:
// 数据初始化
List userEntityList = Lists.newArrayList();
for (int i = 0; i < 10000; i++) {
UserEntity userEntity = new UserEntity(123L + i, "syske", "云中志");
userEntityList.add(userEntity);
}
为了方便测试,这里我先初始10000条数据。
getter/setter
这种方式是最直接、性能最好的方式,当然也是兼容性最差的方式,因为这种方式两个对象需要强依赖,如果字段增加需要修改转换方法,对改动不友好:
long start1 = System.currentTimeMillis();
List userVoList = Lists.newArrayList();
for (UserEntity userEntity : userEntityList) {
UserVo userVo = new UserVo();
userVo.setId(userEntity.getId());
userVo.setUserName(userEntity.getUserName());
userVo.setNickName(userEntity.getNickName());
userVoList.add(userVo);
}
System.out.printf("getter/setter耗时:%s\n", System.currentTimeMillis() - start1);
BeanUtils
BeanUtils是spring-beans包下面的一个工具了,为我们提供了丰富的方法,这里我们主要测试的是copyProperties方法,这个方法有两个参数,第一个参数是源数据,第二个是需要赋值的目标数据:
long start2 = System.currentTimeMillis();
List userVoList2 = Lists.newArrayList();
for (UserEntity userEntity : userEntityList) {
UserVo userVo = new UserVo();
BeanUtils.copyProperties(userEntity, userVo);
userVoList2.add(userVo);
}
System.out.printf("BeanUtils耗时:%s\n", System.currentTimeMillis() - start2);
这种方式就比较简洁了,简单来说就是对两个对象进行属性值拷贝,但是属性必须要有setter方法(被赋值方)和getter方法(源数据),copyProperties方法提供了忽略属性值的方式,除此外暂未发现有任何优点。如果只是单个对象的转换,而且不考虑性能的话,这种方式也比较方便。(起初我以为它至少可以提供无getter/setter方法的值拷贝,但是测试之后我发现我想多了,底层还是反射)。
BeanMap
BeanMap也是spring-beans包下面的,不过它属于cglib包(一个强大的,高性能,高质量的Code生成类库),它主要提供了一种Bean转Map的能力,最初我也是因为这个接触这个包的,最后发现它还可以用来做类型转换,而且性能也还不错。通过BeanMap来实现类型转换的思路也很简单,就是分别将目标vo和源vo分别转为BeanMap,然后用源Vo的BeanMap覆盖目标vo的BeanMap,然后通过BeanMap的getBean方法从BeanMap中拿到赋值后的vo,下面是具体实现:
long start3 = System.currentTimeMillis();
List userVoList3 = Lists.newArrayList();
for (UserEntity userEntity : userEntityList) {
UserVo userVo = new UserVo();
BeanMap entityMap = BeanMap.create(userEntity);
BeanMap userVOMap = BeanMap.create(userVo);
userVOMap.putAll(entityMap);
userVoList3.add((UserVo) userVOMap.getBean());
}
System.out.printf("BeanMap耗时:%s\n", System.currentTimeMillis() - start3);
这种方式的好处也是简洁,但是性能比BeanUtils好,和getter/setter比更灵活,缺点是不能忽略值,但是可以自己实现,也不难。
反射
反射这种方式也算比较原始的解耦方式,缺点是稍微有点繁琐,但是优势是性能比BeanUtils和BeanMap要好。
long start4 = System.currentTimeMillis();
List userVoList4 = Lists.newArrayList();
for (UserEntity userEntity : userEntityList) {
UserVo userVo = new UserVo();
Class eClass = userEntity.getClass();
Class vClass = userVo.getClass();
Field[] fields = eClass.getDeclaredFields();
Field[] vClassDeclaredFields = vClass.getDeclaredFields();
List fieldList = Lists.newArrayList(vClassDeclaredFields);
for (Field field : fields) {
if (fieldList.contains(field)) {
String name = field.getName().substring(0, 1).toUpperCase() + field.getName().substring(1);
Method setter = vClass.getMethod("set" + name, field.getType());
Method getter = eClass.getMethod("get" + name, null);
setter.invoke(userVo, getter.invoke(userEntity, null));
}
}
userVoList4.add(userVo);
}
System.out.printf("反射耗时:%s", System.currentTimeMillis() - start4);
但是这种方式的缺点是如果两个vo属性不一致时需要单独处理,我们可以看到代码中有属性字段的校验。
性能对比
下面我们就分别针对不同的数据量做一个简单的测试,对比下各种方案的性能,首先是三个字段在不同数据量下的性能比较:
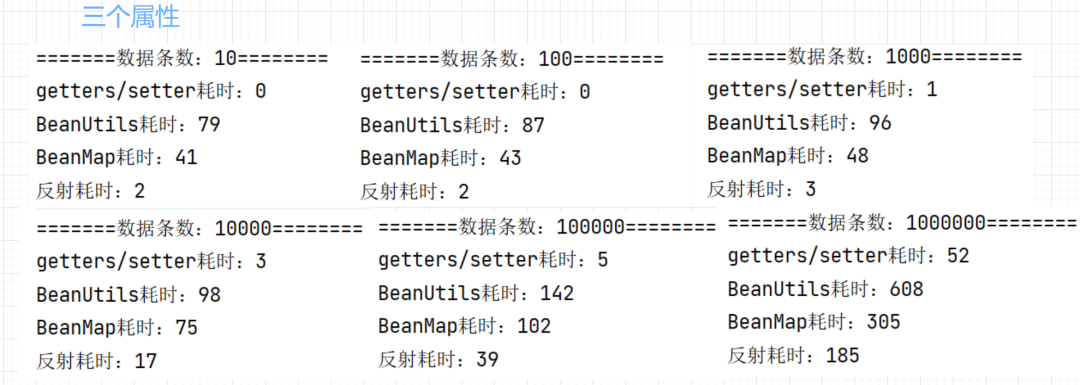
三个字段进行数据转换时,我们可以得出以下结论:
- 在十万条数据的数据之前,
getter/setter性能变化不大,一直表现很优秀,大概是BeanUtils的30倍; BeanUntils和BeanMap差距也不是特别大,差距最大也就两倍左右;反射和getter/setter的性能差异大概是3倍;- 综合极值来看,
getter/setter的性能差异大概是50倍,性能急剧变化发生在数据由10万变为100万的时候;反射的性能差异差不多是90倍,性能是从10000条的时候发生变化的;BeanMap和BeanUtils性能变化不到,差不多7倍左右
下面我们再看下字段数量增多的情况:
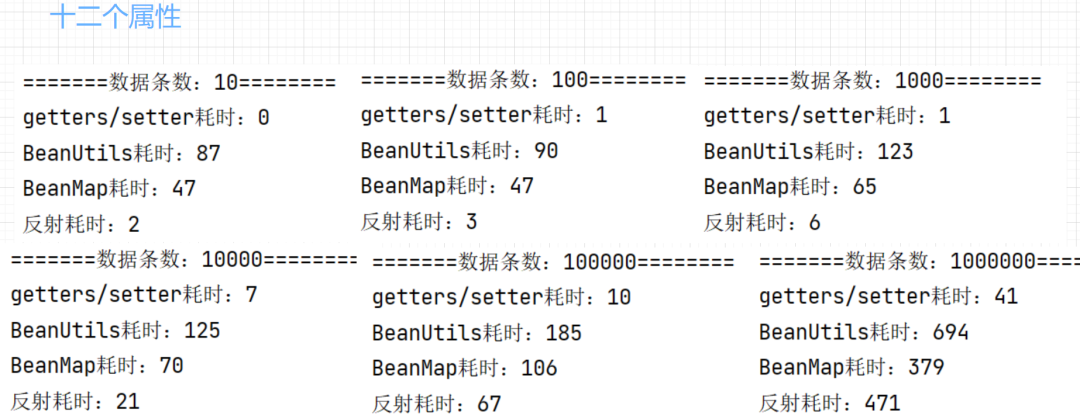
相比于3个字段,12个字段的性能并没有发生太大改变,变化比较大的是反射这种方式,其他三种方式并没有太大变化,甚至还出现性能更好的情况,但是再100万数据量的时候,反射性能比BeanMap差,不过也能想明白,毕竟字段越多,反射需要循环的次数就越多,所以性能会下降。好了,关于测试我们就到这里吧。
结语
介于时间的关系,我们今天的内容就先到这里,感兴趣的小伙伴可以自己测试下,总体来说,我们的预期目标算是达成了。最后,希望通过今天的性能测试,能够让各位小伙伴重视开发过程中的性能问题,找到更适合的方案。好了,各位小伙伴,晚安吧!
- END -