
图解VXLAN容器网络通信方案
一篇文章围绕一张图,讲述一个主题。不过这个主题偏大,我估计需要好几篇文章才能说得清楚。
云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式API。其中K8s是不可变基础设施的压舱石。典型的K8s集群由数十个Node, 成百个Pod,上千个Container组成。相互隔离的容器间需要协作才能完成更大规模的应用。而协作就需要网络通信。
这篇文章我主要通过下面这张全景图来讲述K8s是如何利用VXLAN来实现K8s的容器通信方案的。网络通信不是量子纠缠,网络流量是实打实地通过了各个虚拟的、实体的网络设备,途径每个设备节点时自然也会受到设备上的路由、iptables等策略控制。
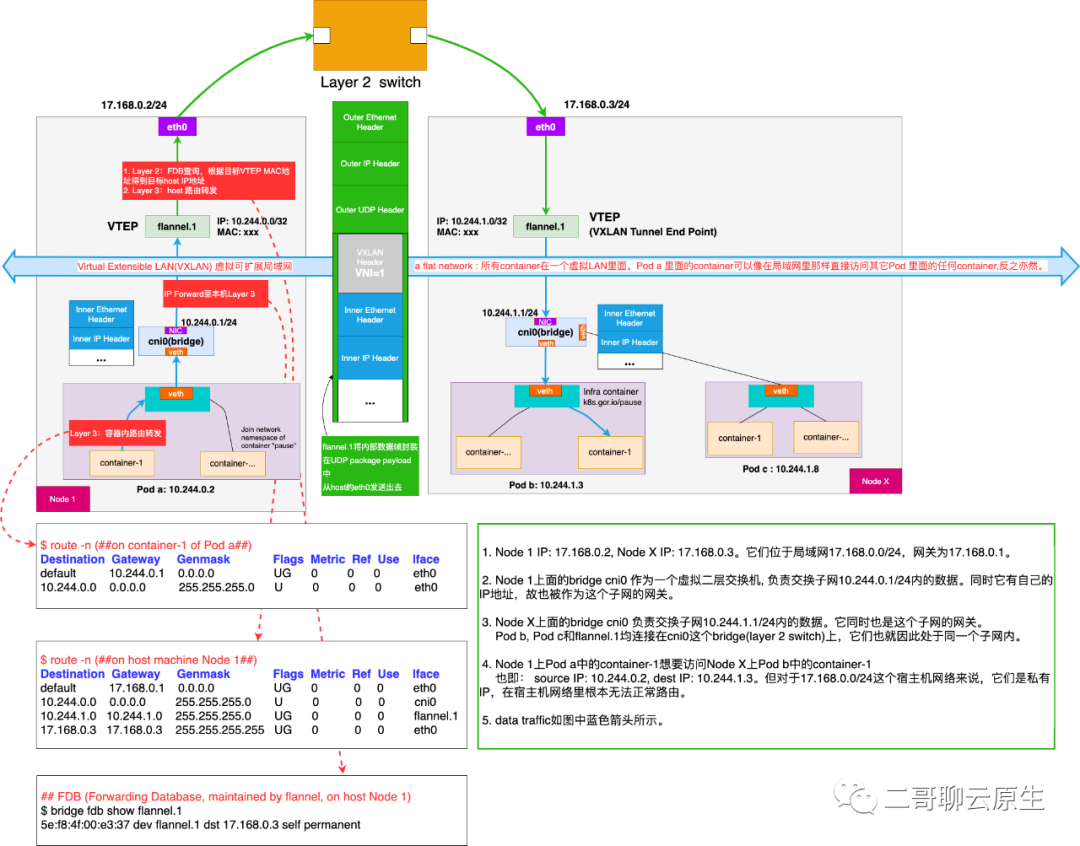
图:VXLAN容器网络方案全景图
K8s的容器通信方案有很多种。譬如flannel实现的host-gw方案、calico基于三层转发实现的方案以及本文着重讲述的flannel.1 VXLAN方案。为什么我要挑flannel.1 VXLAN方案来细聊呢,因为它够复杂,涉及到了比较多的虚拟网络设备和组网技术。
这张图里面涉及到如下几种网络设备,有机会我们单独拿一篇出来过一下这些设备。
eth: 物理网卡在内核中的表示。它一端连着网络栈,另一端通过驱动连接着物理网卡。
veth: virtual eth。它是成对出现的,类似交叉网线连接的一对物理网卡。从网卡一端流出的数据会原样流入另外一端。每个veth都有自己的MAC地址,也可以给它设置IP地址。
bridge: bridge的行为类似二层交换机,又翻译成网桥。可以将veth,tap等虚拟网络设备连(插)到它上面。如果数据包的目的 MAC 地址为网桥本身,并且网桥设置了 IP 地址的话,那该数据包就会被认为是bridge收到了发往创建网桥那台主机的数据包,这个数据包将不会转发到任何设备,而是直接交给上层(三层)协议栈去处理。
VTEP:VXLAN 网络的每个边缘入口上,布置有一个 VTEP(VXLAN Tunnel Endpoints)设备,它既可以是物理设备,也可以是虚拟化设备,主要负责 VXLAN 协议报文的封包和解包。图中flannel.1就是一个VTEP设备,它既有IP地址,又有MAC地址。
虽然容器间的网络方案多种多样,但所有的容器网络通信问题,其实都可以归结为以下几种场景。本篇我们专注容器间通信的场景,故略去了其它通信主体与容器通信的情形,比如本地Node里面的进程也会和容器通信。留个彩蛋,以后再聊。
同一个Pod内的容器间通信
同一个Node内的容器间通信
跨Node的容器间通信
这里需要强调的一个点是,虽然Pod是K8s编排调度的基本单位,但是通信的需求却发端于Pod里面的容器。
环境说明
这张图里面,Node 1 和Node X位于同一个局域网17.168.0.0/24。Node 1的IP地址是17.168.0.2,Node X的IP是17.168.0.3。
K8s集群所使用的子网为10.244.0.0/16。对于网络17.168.0.0/24和它里面的交换机和路由器来说,K8s集群所使用的子网是无效的网络,交换机和路由器更是无从转发、路由任何源IP或目的IP为K8s子网的数据包。
非常明显的矛盾出现了:K8s集群要通过子网为10.244.0.0/16通信,而宿主机环境却根本不认识这个子网。我们接下来将看到"特洛伊木马"的故事在这里再次上演。
我们的目标是在这种矛盾的网络环境下,解释清楚pod a里面的container-1访问pod b里面的container-1时发生了哪些事情。图中蓝色的标线展示了数据流的方向。
图中的绿色标线和绿色的框图表示了与VXLAN相关的数据流和网络封包示意图。
出于简单,Node 1里面只画出了一个Pod, pod a,所有的Pod都连在了bridge cni0上,子网为10.244.0.1/24。Node X里面只画了两个Pod, pod b和pod c ,所有的Pod也一样都连在了bridge cni0上,子网为10.244.1.1/24。
每个Node上面的bridge都分配有IP地址。Pod a的IP地址是10.244.0.2,Pod b的IP地址是10.244.1.3。
同一个Pod内的容器间通信
这是最简单的情形,内核自带技能,不需额外的组网技术加持。
需要强调的一个知识点是Pod内部所有的容器是共享同一个网络栈、routes以及iptables的,因为它们属于同一个network namespace。
在一个k8s cluster内部,每个Pod拥有独一无二的IP地址,Pod内部所有的container共享分配Pod的地址。Pod内部的容器共享pod的IP地址,但各个容器的端口不能冲突。
由于Pod调度的原子性,一个Pod内部的所有container只会被调度到一台主机上运行。类似本地机器上两个应用程序通过localhost进行进程间通信一样,同一个Pod内部的容器间可以直接通过localhost来通信。此时的traffic直接通过loopback 网络设备在两个容器间流动。图中的bridge无法感知这样的traffic,主机上的网络栈和其它网络设备更不会感知到。
同一个Node内的容器间通信
图中Node X上画出了多个Pod。当Pod b里面的container-1想要访问Pod c里面的container-1时属于这个场景。
Pod b里面的路由表决定了访问Pod c的traffic需要从自己的interface eth0出去。
src IP:10.244.1.3,dest IP:10.244.1.8,
src MAC为Pod b veth MAC,dest MAC为Pod c veth MAC。
从图中可以看到Pod b和Pod c都是插在了bridge上面。作为一个虚拟的二层交换机,它按照二层交换机的行为交换、转发数据包。
在这种场景下,这两个container之间的通信行为不会超出bridge的范围,包括Pod b的container-1通过ARP得知目的container的MAC地址也是在bridge内处理。也不会涉及NAT等地址转换操作。
跨Node的容器间通信
这是最常用的通信场景。容器访问api server即是典型的例子。
下面开始最复杂的步骤,这些步骤发生在Node 1。Node X收到以太帧后的操作是一个逆过程,这里不做赘述。
我们按照traffic的流向,以它途径的各个网络设备(虚拟的、实体的)为分割节点,分段讲述每段发生了什么。
从container到cni0
从Pod a的路由表可知,以太帧需要从它的NIC eth0离开。因为eth0是veth的其中一端,另外一端插在bridge cni0上面,于是以太帧进入cni0。此以太帧的目的MAC地址为bridge。
src IP:10.244.0.2,dest IP:10.244.1.3,
src MAC为Pod a veth MAC,dest MAC为cni0 MAC。
从cni0到flannel.1
前面提到该网桥配置有IP地址,现在它收到一个目的MAC地址为自己的数据包,于是触发了 Linux Bridge 的特殊转发规则:网桥不会将这个数据包转发给任何设备,而是直接转交给主机的三层协议栈处理。
主机协议栈根据host的路由表,从而得知需要把IP包交给本机的flannel.1。
从这步以后就是三层路由了,已经不在网桥的工作范围之内,而是由 Linux 主机依靠 Netfilter 进行 IP 转发(IP Forward)去实现的。注意这里是IP包转发,接收者收到的是3层的package,因而它不包含二层的数据。
flannel.1组装内部数据帧
至此,越过千山万水,本机的flannel.1终于收到了IP包。
从这里开始,flannel.1需要想办法营造幻象:跨主机营造一个虚拟的网络10.244.0.0/16,好让Pod a看起来Pod b和它正处于一个完全合法的、信息交换自由无障碍的环境。天真的Pod们完全不知这个网络是一个虚拟的、私有的、宿主机网络里面的交换机和路由器根本不认识它这样一个事实。
前面提到flannel.1收到的是 IP 包,既然是IP包,那它就没有MAC地址,但flannel.1同时又要想办法把“原始 IP 包”加上一个目的 MAC 地址(当然也需要包含源flannel.1的MAC地址),封装成一个完整的二层数据帧,然后发送给位于Node X上的flannel.1。
而大家都知道要组装一个完整的二层数据帧,首先需要解决的问题是目标 flannel.1的MAC地址是什么呢?下面的提示给出了答案。
Node X上的flannel.1的 MAC 地址是什么?
我们已经知道了Node X上的flannel.1的 IP 地址,它是数据包的目的地。要根据三层 IP 地址查询对应的二层 MAC 地址,这正是 ARP(Address Resolution Protocol )表的功能。这里要用到的 ARP 记录,也是 flanneld 进程在 Node 1 节点启动时,自动添加在 Node 1 上的。我们可以通过 ip 命令看到它,如下所示:
# 在Node 1上
$ ip neigh show dev flannel.1
10.244.1.0 lladdr 5e:f8:4f:00:e3:37 PERMANENT
通过ARP,我们知道了目的 flannel.1的MAC是 5e:f8:4f:00:e3:37。到此时,已经完整地产生了内部数据载荷(Inner payload), 内部IP头(Inner IP Header) 10.244.1.3和内部Ethernet头(Inner Ethernet Header)5e:f8:4f:00:e3:37了。
但是,因为上面提到的这些 VTEP 设备的 MAC 地址,对于宿主机网络来说并没有什么实际意义,所以上面封装出来的这个数据帧,并不能在我们的宿主机二层网络里传输。为了方便叙述,我们把它称为“内部数据帧”(Inner Ethernet Frame),或者叫"原始二层数据帧"(Original Layer 2 Frame)。
封装好的内部数据帧如全景图中蓝色的方框所示。
接下来,Linux 内核还需要再把“原始二层数据帧”进一步封装成为宿主机网络里的一个普通的外部数据帧,好让它载着“原始二层数据帧”,通过宿主机的 eth0 网卡进行传输。
flannel.1组装VXLAN数据帧
如下图所示,原始二层数据帧加上VXLAN头,我们把它叫做“VXLAN数据帧”。在全景图中,我在蓝色的方框上面加了一个灰色的方框,用来表示VXLAN头。需要特别注意下灰色方框中VNI=1这个部分。VNI(Virtual Network Identifier)长24-bit,在这里flannel.1默认把它设置为1,这样Node X上面的flannel.1就知道这个数据帧是需要它处理的。
Flannel 中,VNI 的默认值是 1,这也是宿主机上的 VTEP 设备都叫作 flannel.1 的原因。
有了VXLAN数据帧,就可以开始演绎一个和“特洛伊木马”相同的故事。VXLAN数据帧如同希腊战士,但我们的目的不是攻打特洛伊城,而是把这个VXLAN数据帧完整地、神不知鬼不觉地送到城内的flannel.1手里。要达到这个目的,我们还需要一个木马。
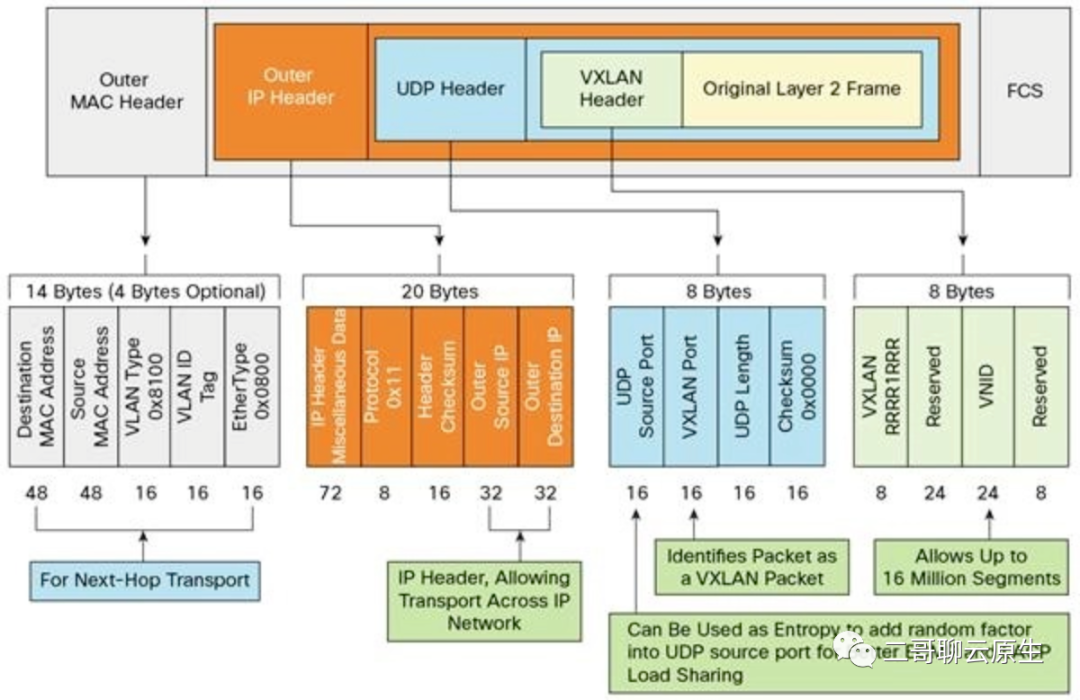
图:VXLAN数据帧
从flannel.1发起UDP连接
好了,“希腊战士”有了,我们就差一个木马了。接下来要做的事情是,像把希腊战士藏到木马里一样,Linux 内核要把这个VXLAN数据帧塞进一个 UDP 包里发出去。上面的全景图中,我特意把VXLAN数据帧画得窄了一些,好让你感觉外围稍胖的UDP包确实像是个木马。
Node 1上的flannel.1 设备要扮演一个“网桥”的角色,在二层网络进行 UDP 包的封包和转发。在Node 1看来,它会以为自己的 flannel.1 设备只是在向另外一台宿主机的 flannel.1 设备,发起了一次普通的 UDP 链接,却全然不知它发送的是一个木马(不要紧张,此木马非木马病毒)。
但且慢,先回答一个问题:刚才在组装内部数据帧的时候,我们知道 flannel.1 设备已经知道了目的 flannel.1 设备的 MAC 地址,但这个 UDP 包该发给哪台宿主机呢?也就是说,木马有了,希腊战士也藏到木马肚子里了,但特洛伊城在哪里?
是时候轮到一个叫作转发数据库(FDB, Forwarding Database)上场帮忙了。这个 flannel.1“网桥”对应的 FDB 信息,也是 flanneld 进程负责维护的。它的内容可以通过 bridge fdb 命令查看到,如下所示:
# 在Node 1上,使用“目的VTEP设备”的MAC地址进行查询
$ bridge fdb show flannel.1 | grep 5e:f8:4f:00:e3:37
5e:f8:4f:00:e3:37 dev flannel.1 dst 17.168.0.3 self permanent在上面这条 FDB 记录里,指定了这样一条规则:发往我们前面提到的“目的 flannel.1”(MAC 地址是 5e:f8:4f:00:e3:37)的二层数据帧,应该通过本机的flannel.1 设备,发往 IP 地址为 17.168.0.3 的主机。显然,这台主机正是 Node X,UDP 包要发往的目的地就找到了。
得到了目的IP地址,自然也会得知Node X的MAC地址。接下来的流程,就是一个正常的,宿主机网络上的封包工作,且最终从 Node 1 的 eth0 网卡发出去了。只不过这个过程发生在虚拟设备flannel.1上面罢了。
参考资料
张磊《深入剖析Kubernetes》
周志明《周志明的软件架构课》