
如何使用注解优雅的记录操作日志

写在开头
本文讨论如何优雅的记录操作日志,并且实现了一个SpringBoot Starter(取名log-record-starter),方便的使用注解记录操作日志,并将日志数据推送到指定数据管道(消息队列等)
本文灵感来源于美团技术团队的文章:如何优雅地记录操作日志?。文中使用的部分定义描述和示例来源于美团原文,请知悉。
本文作为《萌新写开源》的开篇,先把项目成品介绍给大家,之后的文章会详细介绍,如何一步步将个人项目做成一个大家都能参与的开源项目(如何写SpringBoot Starter,如何上传到Maven仓库,如何设计和使用注解和切面等),麻烦大家多多点赞支持,这是我更新的动力。请大家放心,公众号还会持续更新,我没有忘掉密码。:)——蛮三刀酱
本文目录:
什么是操作日志? Java中常见的操作日志实现方式 实战:通过注解实现操作日志的记录
什么是操作日志?
定义:操作日志主要是指对某个对象进行新增操作或者修改操作后记录下这个新增或者修改,操作日志要求可读性比较强,因为它主要是给用户看的,比如订单的物流信息,用户需要知道在什么时间发生了什么事情。再比如,客服对工单的处理记录信息。
以我们系统内部使用的一个CRM系统举例,里面每个联系人的资料都会有操作历史:

这些数据就是操作系统日志,这些数据通常会以结构化数据的形式存储在数据库中,对于开发来说,这种日志的代码逻辑通常是非常规律,比如读取变化前和变化后的数据,获取当前操作人和操作时间等等。
常见的操作日志实现方式
在小型项目中,这种日志记录的操作通常会以提供一个接口或整个日志记录Service来实现。那么放到多人共同开发的项目中,除了封装一个方法,还有什么更好的办法来统一实现操作日志的记录?下面就要讨论下在Java中,常见的操作日志实现方式。
当你需要给一个大型系统从头到尾加上操作日志,那么除了上述的手动处理方式,也有很多种整体设计方案:
1. 使用Canal监听数据库记录操作日志
Canal应运而生,它通过伪装成数据库的从库,读取主库发来的binlog,用来实现数据库增量订阅和消费业务需求。可以看我的这篇文章:
这个方式有点是和业务逻辑完全分离,缺点也很大,需要使用到MySQL的Binlog,向DBA申请就有点困难。如果涉及到修改第三方接口,那么就无法监听别人的数据库了。所以调用RPC接口时,就需要额外的在业务代码中增加记录代码,破坏了“和业务逻辑完全分离”这个基本原则,局限性大。
2. 通过日志文件的方式记录
log.info("订单已经创建,订单编号:{}", orderNo)
log.info("修改了订单的配送地址:从“{}”修改到“{}”, "金灿灿小区", "银盏盏小区")
这种方式,需要手动的设定好操作日志和其他日志的区别,比如给操作日志单独的Logger。并且,对于操作人的记录,需要在函数中额外的写入请求的上下文中。后期这种日志还需要在SLS等日志系统中做额外的抽取。
3. 通过 LogUtil 的方式记录日志
LogUtil.log(orderNo, "订单创建", "小明")
LogUtil.log(orderNo, "订单创建,订单号"+"NO.11089999", "小明")
String template = "用户%s修改了订单的配送地址:从“%s”修改到“%s”"
LogUtil.log(orderNo, String.format(tempalte, "小明", "金灿灿小区", "银盏盏小区"), "小明")
这种方式会导致业务的逻辑比较繁杂,最后导致 LogUtils.logRecord() 方法的调用存在于很多业务的代码中,而且类似 getLogContent() 这样的方法也散落在各个业务类中,对于代码的可读性和可维护性来说是一个灾难。
4. 方法注解实现操作日志
@OperationLog(bizType = "bizType", bizId = "#request.orderId", pipeline = DataPipelineEnum.QUEUE)
public Response function(Request request) {
// 方法执行逻辑
}
我们可以在注解的操作日志上记录固定文案,这样业务逻辑和业务代码可以做到解耦,让我们的业务代码变得纯净起来。
美团的原文给出了注解记录日志的详细架构设计方案,并且贴出了部分源码。但是文中并没有完整的开源项目,由于自己也很感兴趣,并且公司的业务正好也有类似需求,所以我花了点时间,实现了一版最简易的版本,支持将操作日志传递到消息队列中。
实战:通过注解实现操作日志的记录
大楼不是一天建成的,美团博客中描述的方案应该在公司内部已经非常成熟了,我也没有那么多精力一口气吃成一个胖子,我们从最基础的版本写起。
我给自己的这个项目,或者说依赖包起名为log-record-starter,一方面遵循springboot-starter命名规范,一方面也表明项目的用处,记录日志。
开启项目之前,先问问自己
Q:你这个依赖包,又是一个冗余的造轮子吧?市面上这种东西是不是已经够多了?
A:本着有现成轮子绝不造轮子的原则,我在Github和其他网站进行了一系列的相关搜索,Github有几个类似的实现项目,不过都以个人实现为主,没有一个具有一定影响力的成熟项目。基于我在自己的业务项目中拥有实际的场景需求,并且目前还没有满足我需求的现成可接入依赖,我才开始这个依赖包的代码编写。
Q:我用了你这个依赖包,是不是很复杂?之后你不维护了的话,是不是坑我们这些吃螃蟹的?
A:依赖包的维护问题一直是一个大问题,本着最小依赖,尽量可扩展的原则。本库特点如下:
使用SpringBoot Starter,接入只需要简单引入一个依赖。 通过Spring Spel表达式拿到参数,对你的业务逻辑没有侵入性。 默认使用RabbitMq传递日志消息,日志操作解耦。 之后会引入其他数据源,例如Kafka等(毕竟还要给三歪的项目用,我没有被三歪绑架,嗯,绝对没有)。
好了,这就是我想说在前面的话。下面就是该项目的使用介绍和应用场景介绍。
Log-record-starter 一句话介绍
本项目支持用户使用注解的方式从方法中获取操作日志,并推送到指定数据源
只需要简单的加上一个@OperationLog便可以将方法的参数,返回结果甚至是异常堆栈通过消息队列发送出去,统一处理。
@OperationLog(bizType = "bizType", bizId = "#request.orderId", pipeline = DataPipelineEnum.QUEUE)
public Response function(Request request) {
// 方法执行逻辑
}
使用方法
只需要简单的三步:
第一步:SpringBoot项目中引入依赖
cn.monitor4all
log-record-starter
1.0.0
这里先打断一下,由于Maven公共仓库,是全球唯一托管的,个人开发的项目要提交上去,需要复杂的审核流程,我搞了一会没搞定,就先将包传到了Github Package上(实际就是Github的私有Maven库),所以大家引入依赖后,是不会直接拉到包的,需要配置下你的Maven settings.xml文件。(之后我肯定想办法发到公共仓库,呜呜呜~)
配置很简单,两步,一步是去Github登录,到自己的Settings中,申请一个token,拿到一串字符串。
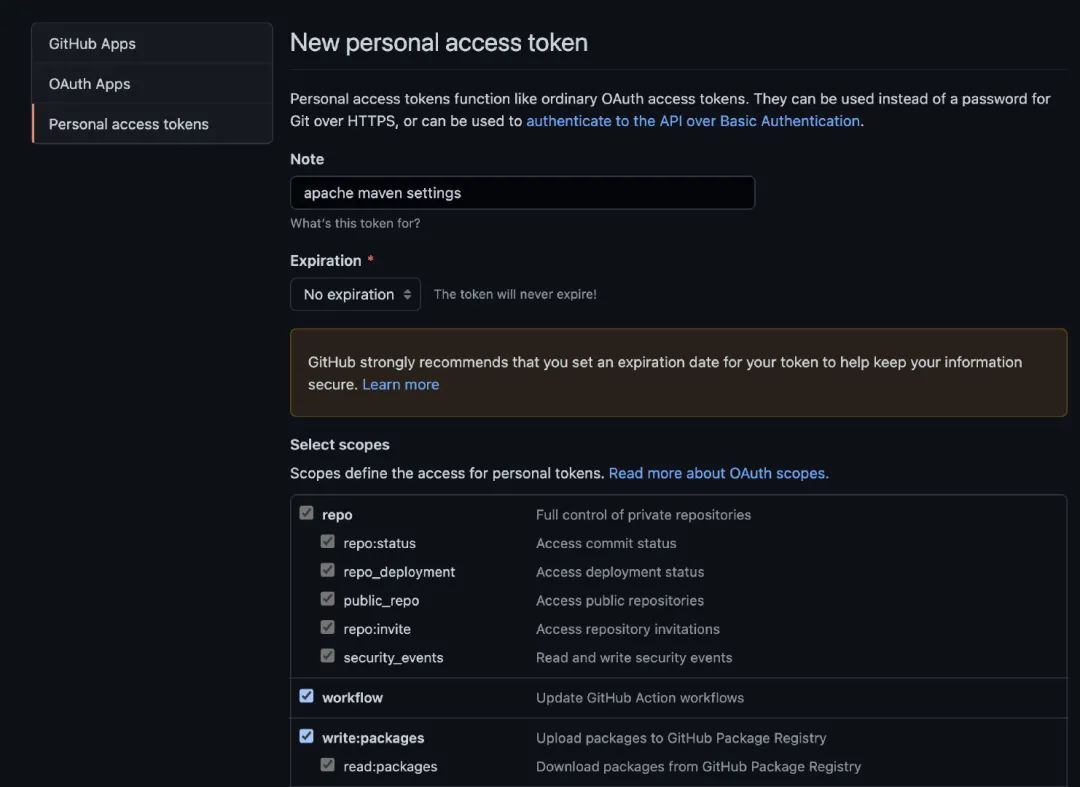
第二步,找到你的settings.xml文件,添加上:
activeProfiles>
github
github
central
https://repo1.maven.org/maven2
github
https://maven.pkg.github.com/OWNER/REPOSITORY
true
github
这里填写你的Github用户名
这里填写你刚才申请的token
还搞不定的同学,这里是Github官方中文教程:
https://docs.github.com/en/packages/working-with-a-github-packages-registry/working-with-the-apache-maven-registry
重启下你的IDEA,能看到下面这个,应该你的settings.xml生效了。

目前我的版本号是1.0.0,之后会更新,未来最新版本号在我仓库查询:
https://github.com/qqxx6661/logRecord
第二步:在Spring配置文件中添加RabbitMq数据源配置
在自己公司里由于阿里封装了自己的MQ叫做MetaQ,并没有对外开源,所以这里先接入了RabbitMQ,也算是比较通用,图个方便。未来会接其他数据源。RabbitMq的安装在这里不展开了,实在是不想把篇幅拉得太大,大家可以自行谷歌下,比如“Docker安装RabbitMq”类似的文章,几分钟就可以设置安装好。
log-record.rabbitmq.host=localhost
log-record.rabbitmq.port=5672
log-record.rabbitmq.username=admin
log-record.rabbitmq.password=xxxxxxxx
log-record.rabbitmq.queue-name=logrecord
log-record.rabbitmq.routing-key=
log-record.rabbitmq.exchange-name=logrecord
第三步:在你自己的项目中,在需要记录日志的方法上,添加注解。
@OperationLog(bizType = "bizType", bizId = "#request.orderId", pipeline = DataPipelineEnum.QUEUE)
public Response function(Request request) {
// 方法执行逻辑
} (必填)bizType:业务类型 (必填)bizId:唯一业务ID(支持SpEL表达式) (必填)pipeline:数据管道,目前只有QUEUE一个数据管道,后续可考虑接入更多数据源 (非必填)msg:需要传递的其他数据(支持SpEL表达式) (非必填)tag:自定义标签
代码工作原理
由于采用的是SpringBoot Starter方式,所以只要你是用的是SpringBoot,会自动扫描到依赖包中的类,并自动通过Spring进行配置和管理。
该注解通过在切面中解析SpEL参数(啥事SpEL?快去谷歌下,之后要讲),将数据发往数据源。目前仅支持RabbitMq,发送的消息体如下:
方法处理正常发送消息体:
[LogDTO(logId=3771ff1e-e5ff-4251-a534-31dab5b666b3, bizId=str, bizType=testType1, exception=null, operateDate=Sat Nov 06 20:08:54 CST 2021, success=true, msg={"testList":["1","2","3"],"testStr":"str"}, tag=operation)]
方法处理异常发送消息体:
[LogDTO(logId=d162b2db-2346-4144-8cd4-aea900e4682b, bizId=str, bizType=testType1, exception=testError, operateDate=Sat Nov 06 20:09:24 CST 2021, success=false, msg={"testList":["1","2","3"],"testStr":"str"}, tag=operation)]
LogDTO是定义的消息结构:
logId:生成的UUID
bizId:注解中传递的bizId
bizType:注解中传递的bizType
exception:若方法执行失败,写入执行的异常信息
operateDate:操作执行的当前时间
success:方式是否执行成功
msg:注解中传递的tag
tag:注解中传递的tag
我还加上了重复注解的支持,可以在一个方法上同时加多个@OperationLog,下图是最终使用效果,可以看到,有几个@OperationLog,就能同时发送多条日志:
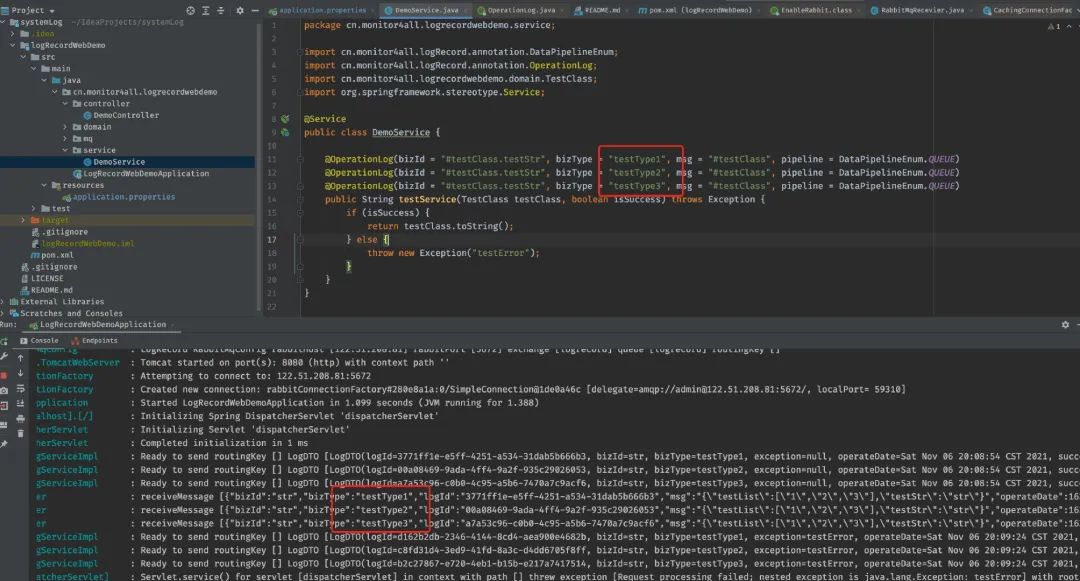
项目具体的实现原理和细节,放在下一篇文章详细讲。(肯定会填坑)
应用场景
以下罗列了一些实际的应用场景,包括我业务中实际使用,并且已经上线使用的场景。
一、特定操作记录日志:如文章最上面一张CRM系统的图描述的那样,在用户进行了编辑操作后,拿到用户操作的数据,执行日志写入。
二、特定操作触发通知:由于我的业务是接手了好几个仓库,并且这几个仓库的操作串成了一条完成链路,我需要在链路的某个节点触发给用户的提醒,如果写硬编码也可以实现,但是远不如在方法上使用注解发送消息来得方便。例如下方在下单方法调用后发送消息。

三、特定操作更新数据表:我的业务中,几个系统互相吞吐数据,订单的一部分数据存留在外部系统里,我们最终目标想要将其中一个系统替代掉,所以需要拦截他们的数据,恰好几个系统是使用LINK作为网关的,我们将数据请求拦截一层,并将拦截的方法使用该二方库进行全部参数的发送,将数据同步写入我们自己的数据库中,实现”双写“。

四、跨多应用数据聚合操作:和”三“类似,在多个应用中,如果需要做行为相同的业务逻辑,完全可以在各个系统中将数据发送到同一个消息队列中,再进行统一处理。
附录:Demo
最后,肯定有小伙伴希望有一个完整的使用Demo,这就奉上!
https://github.com/qqxx6661/systemLog
总结
本文带大家了解了操作日志在Java中的几种实现方式,并且初步介绍了自己的实现代码,在之后的文章里,我会把实现的细节,包括如何部署到Maven仓库等一一和大家唠唠,记得留下你的点赞和收藏~
我是目前在阿里搬砖的工程师蛮三刀酱。
持续的创作离不开你的点赞和转发分享!
往期精彩文章:
老外为了在MacBook上玩原神,让M1支持了所有iOS应用
API网关才是大势所趋?SpringCloud Gateway保姆级入门教程
谁会拒绝一台Win11和MacOS无缝切换的MacBook呢?Parallels17极速体验