
高频面试题LeetCode 31:递归、回溯、八皇后、全排列一篇文章全讲...
来源:TechFlow
作者:梁唐
今天我们讲的是LeetCode的31题,这是一道非常经典的问题,经常会在面试当中遇到。在今天的文章当中除了关于题目的分析和解答之外,我们还会详细解读深度优先搜索和回溯算法,感兴趣的同学不容错过。
题目
Next Permutation
难度
Medium
描述
实现C++当中经典的库函数next permutation,即下一个排列。如果把数组当中的元素看成字典序的话,那下一个排列即是字典序比当前增加1的排列。如果已经是字典序最大的情况,则返回字典序最小的情况,即从头开始。
Implement next permutation , which rearranges numbers into the
lexicographically next greater permutation of numbers.
If such arrangement is not possible, it must rearrange it as the lowest
possible order (ie, sorted in ascending order).
The replacement must be [in-place](http://en.wikipedia.org/wiki/In-
place_algorithm) and use only constant extra memory.
Here are some examples. Inputs are in the left-hand column and its
corresponding outputs are in the right-hand column.
样例
1,2,3 -> 1,3,23,2,1 -> 1,2,31,1,5 -> 1,5,1
介绍和分析
如果对C++不够熟悉的同学可能不知道next permutation这个库函数,这个库函数可以生成下一个字典序的排列。
举个例子,比如样例当中1 2 3这三个元素,我们把它所有的排列列举出来,一共是6种:
1 2 3
1 3 2
2 1 3
2 3 1
3 1 2
3 2 1
这6种排列的字典序依次增加,而next permutation呢则是根据当前的排列返回下一个排列。比如我们输入1 2 3,返回1 3 2,我们输入3 1 2,返回3 2 1。而如果我们输入字典序最大的,也就是3 2 1时,则从头开始,返回字典序最小的1 2 3.
暴力
老规矩,我们第一优先级思考最简单的暴力解法。
最简单粗暴的方法是什么,当然是将所有的排列全部列举出来,然后根据字典顺序排序,根据要求筛选,最后返回答案。
说起来很简单,但是实现的话一点都不容易。首先,我们怎么获取所有的排列呢?这个问题最简单的方法是通过递归实现深度优先搜索。我单单这么说,对搜索算法不够熟悉的同学可能理解不了。没关系,我们一步一步来推导。我们先把原问题放一放,来看一道经典的搜索问题:八皇后问题。
八皇后问题
八皇后问题是假设我们有一张8*8的国际象棋的棋盘,我们要在棋盘上放置八个皇后,使得这些皇后之间彼此相安无事。

众所周知,在国际象棋当中皇后比较牛X,可以横竖以及对角线斜着走。也就是说如果将两个皇后放在同行或者同列以及同对角线,那么就会出现皇后之间互相攻击的情况,也就不满足题目要求了。
这个问题我们显然不考虑无脑的暴力枚举,即使我们知道是8个皇后,如果我们真的用8重循环去查找合法位置的话,那么一定会复杂度爆炸计算到天荒地老的。原因也很简单,我们稍微分析一下复杂度就能知道。对于每重循环,我们都需要遍历64个位置,那么一共的复杂度就是,这是一个非常庞大的数字,几乎是算不完的。而且如果我们变换一下题目,假设我们一开始不知道皇后的数量,变成n皇后问题,那么我们连写几重循环都不知道。解决这个问题的方法需要我们人为地将问题的规模缩小,其实我们没有必要去遍历所有的位置。因为根据题目条件,皇后不能同行,所以我们每行只能放置一个皇后。而刚好我们是8*8的棋盘,所以我们刚好是每行和每列都只能放置一个皇后。也就是说,我们一行一行地放置皇后可以简化计算量。所以解法就变成了,对于第1行而言,我们有8个位置可以放置皇后。我们随意地选择了一个位置之后,只剩下了7个位置给第二行,然后再放一个,再剩下6个位置给第三行……以此类推,当这样所有皇后放置完了,我们检查完合法性之后,我们接下来需要回到之前的行,选择其他的位置。举个简单的例子,假设我们一开始的放置方案是[1, 2, 3, 4, 5, 6, 7, 8]。我们是放置完第8行的棋子之后进入的结束状态,由于第八行只剩下了一个位置,所以没有其他可以选择的情况。在这种情况下,我们应该往上回顾,回到第7行的时候,对于第7行来说可以选择的位置有[7, 8],第一次我们选择了7,那么我们可以试试选择8,这样就可以得到新的答案[1, 2, 3, 4, 5, 6, 8, 7]。这样又结束了之后,我们再回顾的时候发现第7行的情况也都选择完了,那么要继续往上,回顾第6行的情况。如果我们把搜索树画一部分出来的话是这样:root你会发现我们一行一行放置的过程在树上对应的是一层一层往下的过程,而我们枚举完了之后回顾之前的行的时候,体现在搜索树上是反向的逆流而上的过程。我们把枚举完了后续回到之前的决策的算法称为“回溯法”,想象一下一棵从源头展开的搜索树,我们顺着它一层一层往下遍历,遍历结束完了之后又逆流而上去修改之前的决策,再拓展新的搜索空间。这也有点像是平行时空,根据平行时空理论,世界上的每一个随机决定都会生成一个平行宇宙,如果你有穿梭时间的能力,那么你就可以回到之前产生平行时空的节点,去遍历其他的平行时空。如果你看过经典的悬疑电影蝴蝶效应的话,那么你一定知道我在说什么。关于回溯这个概念,我也在之前讲解栈和模拟递归的文章当中提到过,感兴趣的同学可以点击下方的链接查看。数据结构——30行代码实现栈和模拟递归
/
1
/
2
/
3
/
4
/
5
/ \
6 7
/ \
7 8
/ \
8 7
模板代码
如果是初学者,即使是理解了递归的概念想要自己写出代码来也是一件不容易的事情。因为在我们看来记录所有节点的状态,遍历,再回到之前的状态,再继续搜索,这是一个非常复杂的过程。好在我们并不需要自己记录这个过程,因为计算机在执行程序的时候会有一个称为方法栈的东西,记录我们执行的所有函数和方法的状态。比如我们在A程序中执行了B程序的代码,like this:def A():我们在A当中的第二行执行了B这个函数,那么系统会为我们记录下我们在执行B的时候的位置是第二行,当B执行结束,还会回到调用的位置,继续往下执行。而递归呢,则是利用这一特性,让A来执行自己:
do_something()
B()
do_something()
def A():和刚才一样,系统同样会为我们记录执行A的位置。A执行了A,在我们看来是一样的,但是系统会储存两份方法状态,我们可以简单认为后面执行的A是A1,那么当A1执行结束之后,又会回到A执行A1的位置。而用递归来实现搜索呢,只是在此基础上加上了一点循环而已。
do_something()
A()
do_something()
def dfs():这就是一个简单的搜索的代码框架了,我们遍历每个节点的所有决策,然后记录下这个选择,进行往下递归。当我们执行完再次回到这个位置这一行代码的时候,我们已经遍历完了这个选择所有的情况,为了防止影响后续的决策,我们要撤销这个选择带来的一些影响,好方便枚举下一个选择。但是这样还没结束,还有一点小问题,就是我们只需要放置8个皇后,我们需要针对这点做限制,不然就会无穷无尽递归下去了。做限制的方法也很简单,本质上来说我们是要限制递归的深度,所以我们可以用一个变量来记录递归的深度,每次往下递归的时候就加上1,如果递归深度达到了我们的要求,就不再往下递归了。加上深度判断之后,我们就得到了经典的回溯的代码框架。几乎可以说无论什么样的回溯搜索问题,都脱离不了这个代码框架,只是具体执行和撤销的逻辑有所不同而已:
for choice in all_choices():
record(choice)
dfs()
rollback(choice)
def dfs(depth):我们利用这个代码框架来实现一下八皇后问题,代码很短,也很好理解
if depth >= 8:
return
for choice in all_choices():
record(choice)
dfs(depth+1)
rollback(choice)
def dfs(n, queens, record):如果我们把八皇后问题当中的不能同列同对角线的判断去掉,也就是说皇后不能同行,一行只能放一个皇后,我们把数组当中的元素看成是皇后,那么去掉限制之后的八皇后问题就变成了全排列问题。而这个问题是找出所有的排列当中大于当前这个排列的最小的排列,也就是说我们不需要记录所有的排列结果,只需要记录满足条件的那一个。那么套用上面的代码框架,这个问题立刻迎刃而解。
# 记录答案与控制递归深度
if n >= 8:
# 由于Python当中传递的是引用,所以这里需要copy
# 否则当后面queens pop的时候,会影响record当中记录的值
record.append(queens.copy())
return
for i in range(8):
# 判断是否同列
if i in queens:
continue
# 判断是否同对角线
flag = False
for j in range(len(queens)):
if abs(n - j) == abs(i - queens[j]):
flag = True
break
if flag:
continue
# 递归与回溯
queens.append(i)
dfs(n+1, queens, record)
queens.pop()
def dfs(permutation, array, origin):我们之所以费这么大劲绕过去讲解八皇后问题,就是为了让大家理解全排列和回溯算法之间的关系。但是如果你真的这么去解题,你会发现是无法通过的,原因也很简单,因为全排列是一个n!的算法,它的复杂度非常大。对于一个稍微大一点的n,我们就得不到结果。
"""
origin记录原排列
mini 记录答案,即大于原排列的最小排列
"""
# 由于Python引用机制,在函数内部修改,外部不会生效
# 所以需要用全局变量来记录答案
global mini
# 当所有元素都已经放入permutation
if len(array) == 0:
# 判断是否合法,并且是最小的
if permutation > origin and permutation < mini:
# 因为后面permutation会执行pop
# 所以这里需要copy
mini = permutation.copy()
# 如果还有元素没有放入
for i in array.copy():
array.remove(i)
permutation.append(i)
dfs(permutation, array, origin)
array.append(i)
permutation.pop()
贪心
费了这么大劲获得了一个不能用的答案,看起来有些可惜,但是其实一点也不浪费。我们是为了学习算法和提升自己来做题的,而不仅仅是为了通过。就好像本文的产生并不仅仅是作为题解产生的,而是希望实实在在地传递一些知识和技能,这也是我的初心。言归正传,我们不用分析也知道,超时的原因很简单,因为我们做了许多无用功。因为我们不论大小,把所有的全排列都求出来了。那么我们能不能有什么办法不用求出所有的全排列就获得答案呢?当然是有的,但是要想能够想到这个答案,需要我们对这个问题有更深一点的理解。我们可以很容易想到,最小的全排列是升序的,最大的是降序的。那么中间大小的呢,大概是什么样子的?显然是有升有降,参差不齐的。我们观察一下相邻排列的规律,看看能发现什么。举个例子,1 2 3的下一个排列是1 3 2,是交换2和3得到的。我们再来看一个,1 3 2 4的下一个排列是1 3 4 2,也是交换了两个元素得到的。如果你列举更多会发现,不论当前的全排列长什么样,我们都可以交换其中的两个元素得到新的排列。所以我们就有一个猜测,是不是只要交换两个元素就可以获得答案呢?从这个角度出发,我们可以锁定目标,就是要找出这两个用来交换的元素。根据排列顺序递增的条件,我们可以想明白,我们应该找的这两个元素应该是小的在前,大的在后,这样我们将它们交换之后,它们的字典序才会增加。我们可以继续想出一些条件,比如我们可以想到我们选择的这两个元素当中较大的那个应该尽量小,其中小的那个要尽量大,并且这两个元素的位置要尽量靠后,不然的话我们一交换元素,可能带来太多的提升。虽然这些条件看起来比较直观,但其实很有用,我们只需要将这些想法想办法加以量化,就可以得到答案了。在此之前,我们先来观察一下一个可能的通用例子,来寻找一下通用的解法。
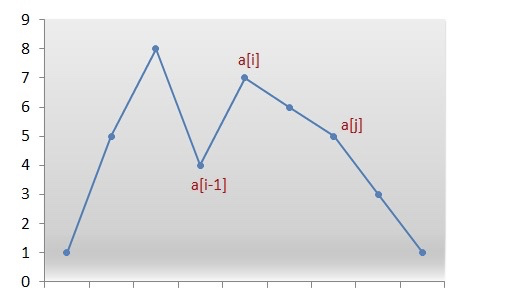 这是一个典型的排列的展示图,横坐标是元素放置的位置,纵坐标是元素的大小。这个图很经典是在于如果我们抽象一些理解,它可以代表所有的排列。不论什么样的排列我们都可以认为它由三部分组成,第一部分是序列前端的升序的部分,第二个部分是中间参差不齐的部分,和最后降序的部分。对于不同的排列而言,模式都是一样的,差别只在于这三个部分的长度不同。我们对着图简单分析一下,可以发现对于后面降序的部分,我们不论怎么交换都不可能提升字典序,只能降低。对于前面的部分,我们交换元素可以提升字典序,但由于过于靠前,所以显然不是最优的结果。那么问题就很明显了,我们应该把关注点放在中间参差不齐的部分。根据我们之前的直观结论,我们选择的元素应该尽可能靠后,所以我们的关注点可以进一步地缩小,可以锁定在第二个部分的末尾,也就是图中的a[i-1]的位置。我们选择a[i-1]的主要原因很简单,因为它比a[i]要小,而从a[i]开始降序。那么剩下的问题就更简单了,我们要做的就是从第三部分选择一个比a[i-1]大的元素和它交换位置。这个元素怎么选呢?我们可以简单地贪心,选择比它大的最小的那个。由于a[i] > a[i-1],所以可以确定,这样的元素一定存在。从图上来看,这个比a[i-1]但又尽量小的元素就是a[j]。我们把a[j]和a[i-1]交换了之后得到了一个新的排列, 并且这个排列比之前的排列大,也就是说我们提升了字典序。但是这还不是最小的情况。原因也很简单,因为最后一部分的元素还是降序的,如果我们把它变成升序,它的字典序还会进一步降低。我们来看一个例子:
这是一个典型的排列的展示图,横坐标是元素放置的位置,纵坐标是元素的大小。这个图很经典是在于如果我们抽象一些理解,它可以代表所有的排列。不论什么样的排列我们都可以认为它由三部分组成,第一部分是序列前端的升序的部分,第二个部分是中间参差不齐的部分,和最后降序的部分。对于不同的排列而言,模式都是一样的,差别只在于这三个部分的长度不同。我们对着图简单分析一下,可以发现对于后面降序的部分,我们不论怎么交换都不可能提升字典序,只能降低。对于前面的部分,我们交换元素可以提升字典序,但由于过于靠前,所以显然不是最优的结果。那么问题就很明显了,我们应该把关注点放在中间参差不齐的部分。根据我们之前的直观结论,我们选择的元素应该尽可能靠后,所以我们的关注点可以进一步地缩小,可以锁定在第二个部分的末尾,也就是图中的a[i-1]的位置。我们选择a[i-1]的主要原因很简单,因为它比a[i]要小,而从a[i]开始降序。那么剩下的问题就更简单了,我们要做的就是从第三部分选择一个比a[i-1]大的元素和它交换位置。这个元素怎么选呢?我们可以简单地贪心,选择比它大的最小的那个。由于a[i] > a[i-1],所以可以确定,这样的元素一定存在。从图上来看,这个比a[i-1]但又尽量小的元素就是a[j]。我们把a[j]和a[i-1]交换了之后得到了一个新的排列, 并且这个排列比之前的排列大,也就是说我们提升了字典序。但是这还不是最小的情况。原因也很简单,因为最后一部分的元素还是降序的,如果我们把它变成升序,它的字典序还会进一步降低。我们来看一个例子:[1,8, 9, 4, 10, 6, 3],根据我们之前的结论,我们会将4和6交换,得到:[1, 8, 9, 6, 10, 4, 3],这个字典序比之前更大,但并不是最小的,我们还可以将最后的10,4,3进行翻转,变成3,4,10。这样最终的答案是:[1, 8, 9, 4, 3, 6, 10]我们分析一下可以发现,我们交换了两个元素的位置之后,并没有影响数组第三部分的元素是降序的这个特性。所以我们并不需要额外的处理,直接翻转数组就可以。所以我们只需要遍历两次数组即可,也就是说我们可以在的时间内找到答案。比之前的算法不知道提升了多少,这个算法的本质其实就是贪心,但是需要我们对题目有非常深入的理解才可以做出来。这些都想明白了之后,代码就很简单了,我们来看下:
class Solution:到这里整个问题就结束了,从代码来看这段代码量并不大,但是想要完美写出来,并不容易。尤其是变量之间的关系需要详细地推导,根据我的经验,结合上图来思考会容易理解很多。今天的文章就是这些,如果觉得有所收获,请顺手点个在看或者转发吧,你们的举手之劳对我来说很重要。
def nextPermutation(self, nums: List[int]) -> None:
"""
Do not return anything, modify nums in-place instead.
"""
# 长度
n = len(nums)
# 记录图中i-1的位置
pos = n - 1
for i in range(n-1, 0, -1):
# 如果降序破坏,说明找到了i
if nums[i] > nums[i-1]:
pos = i-1
break
for i in range(n-1, pos, -1):
# 从最后开始找大于pos位置的
if nums[i] > nums[pos]:
# 先交换元素,在进行翻转
nums[i], nums[pos] = nums[pos], nums[i]
# 翻转[pos+1, n]区间
nums[pos+1:] = nums[n:pos:-1]
return
# 如果没有return,说明是最大的字典序,那么翻转整个数组
nums.reverse()
推荐阅读