
Context这三个应用场景,你知吗

用户发送 开始消费 请求时:开启多个协程开始消费消息队列某个topic的信息;
用户发送 结束消费 请求时:把消费中的topic相关的协程关闭掉,结束消费;






跨服务传递信息

现在具备一定规模的互联网公司都用微服务形式让各系统组合起来为用户提供服务,一个简单的业务在流程上可能需要十几个甚至几十个系统间互相调用。由于每个系统内部的正确性无法保证,若出现了case,比如用户反馈积分少发了,就需要排查这十几个系统的日志信息,看问题出在哪里。
此处需要一个ID凭证,ID是请求级别的,在各个系统中记录着与此请求相关的日志信息,我们把它叫做trace ID。把日志采集并落盘到ES这样的存储中,有case时只需要拿到请求的trace ID就可以把全流程的关键信息还原出来。如图所示:
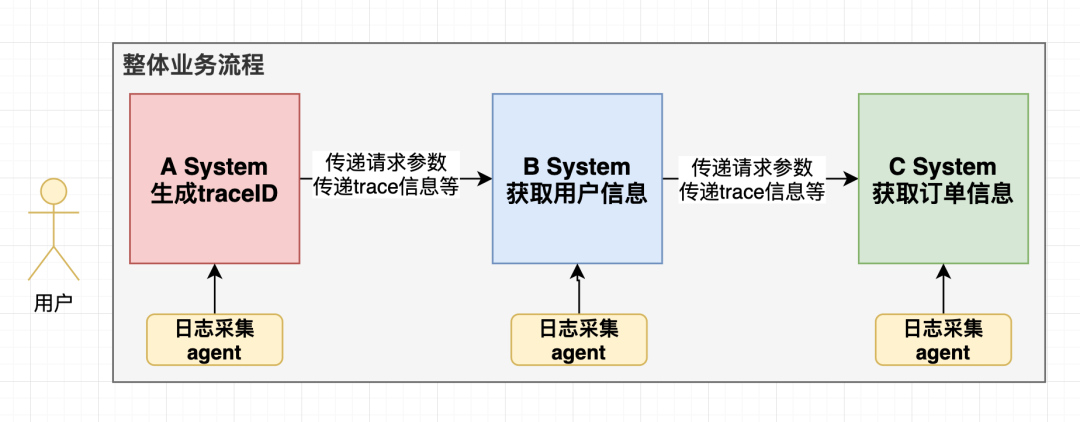
在Golang web服务中,每个请求都是开一个协程去处理的。系统间传递信息时,若通信协议用HTTP,那trace ID等信息可放在HTTP Header中,在web框架的middle层把这些信息存入Context。demo如下:
// 检测上游服务是否传递traceID信息,若传递了直接使用
if v, ok := req.Header["my-awesome-trace-ID"]; ok {
traceID = v[0]
} else {
// 若没传则用公共库生成一个全局唯一的traceID信息
traceID = GenTraceID()
req.Header["my-awesome-trace-ID"] = []string{traceID}
}
// 处理完各种请求上下文信息后,把这些信息统一存储到ctx中,传递给业务层的对应Handler
ctx = context.WithValue(ctx, ContentKey, record)
Context处理请求上下文这块主要用到了WithValue,这个函数接收一个ctx和一对k-v。把k-v对存起来后返回一个子ctx,这次我们先简单介绍其使用场景,下篇文章会从源码层面理解这个函数。
ctx的生命周期是 伴随请求开始而诞生、请求结束而终止的。在请求中ctx会跨越多个函数多个协程,在打日志时,第一个参数预留给ctx是因为日志库需要从Context中抽取trace ID等信息,从而记录下完整的日志。获取信息时只需要调用context的Value方法,demo如下:
// 从Context中获取traceID, 打到日志里
v := ctx.Value("my-awesome-trace-ID")
这里画个图帮助理解:
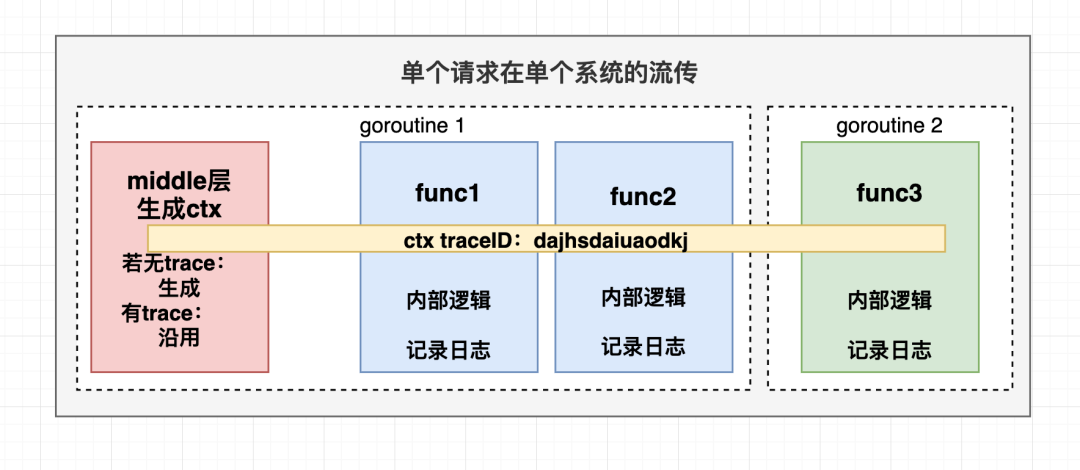
若我们的系统也需要请求第三方服务,同样应把trace ID等信息放入HTTP Header后发送请求,其他服务按照同样的流程接收到trace ID后开始内部逻辑处理。这样一个请求在多个系统中就通过trace ID串联起了整个流程。除trace ID外,Context还可以传递 URL Path、请求时间、Caller等信息。



多协程消费demo:
func main() {
// 此协程负责监听错误信息,开启消费
go func() {
for {
select {
// code
}
}
}()
// 此协程负责监听re-balance信息,开启消费
go func() {
for {
select {
// code
}
}
}()
// ...
}

func main() {
ctx, cancel := context.WithCancel(context.Background())
// 此协程负责监听错误信息,开启消费
go func() {
for {
select {
case <-ctx.Done():
fmt.Println("退出监听错误协程")
return
default:
fmt.Println("逻辑处理中...")
}
}
}()
// 此协程负责监听re-balance信息,开启消费
go func() {
for {
select {
case <-ctx.Done():
fmt.Println("退出监听re-balance协程")
return
default:
fmt.Println("逻辑处理中...")
}
}
}()
// 调用cancelFunc, 结束消费
cancel()
}

控制协程关闭
上面代码用到了WithCancel方法,调用它会返回一个可被取消的ctx和CancelFunc,需要取消ctx时,调用cancel函数即可。context有个Done方法,这个方法返回一个channel,当Context被取消时,这个channel会被关闭。消费中的协程通过select监听这个channel,收到关闭信号后一个return就能结束消费。
CancelFunc可以预防系统做不必要的工作。比如用户请求A接口时,A接口内部需要请求A database、B cache 、C System获取各种数据,把这些数据经过计算后组装到一起返回给调用方。这是正常情况的时序图:
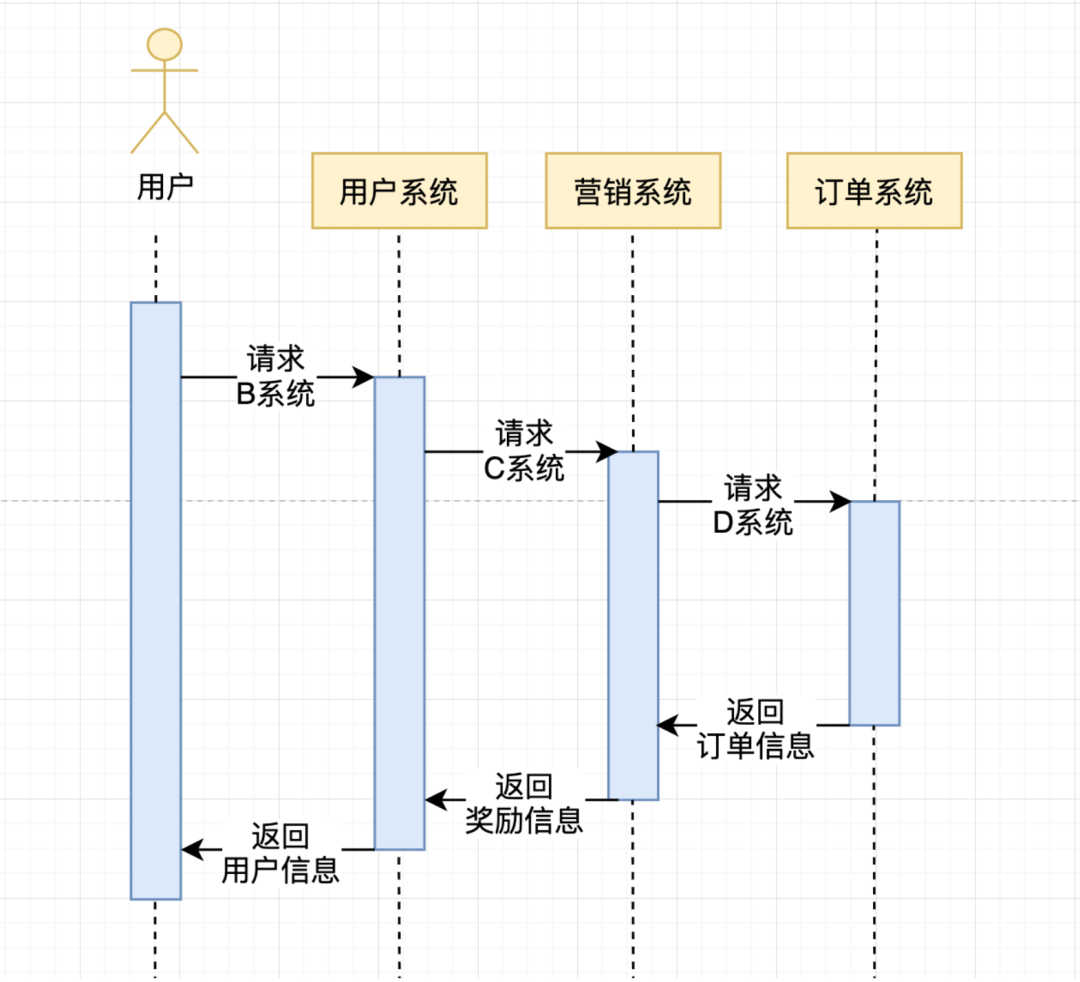
但如果用户在访问网站时觉得没意思,去其他网站了。此时若你的服务收到用户请求后继续去访问其他C system、B database就是浪费资源。比较符合直觉的做法是:当业务请求取消时,你的系统也应该停止请求下游系统。前面我们介绍过context在系统中贯穿请求周期,那么当用户取消访问时,只要context监听取消事件并在用户取消时发送取消事件,就可以取消请求了。
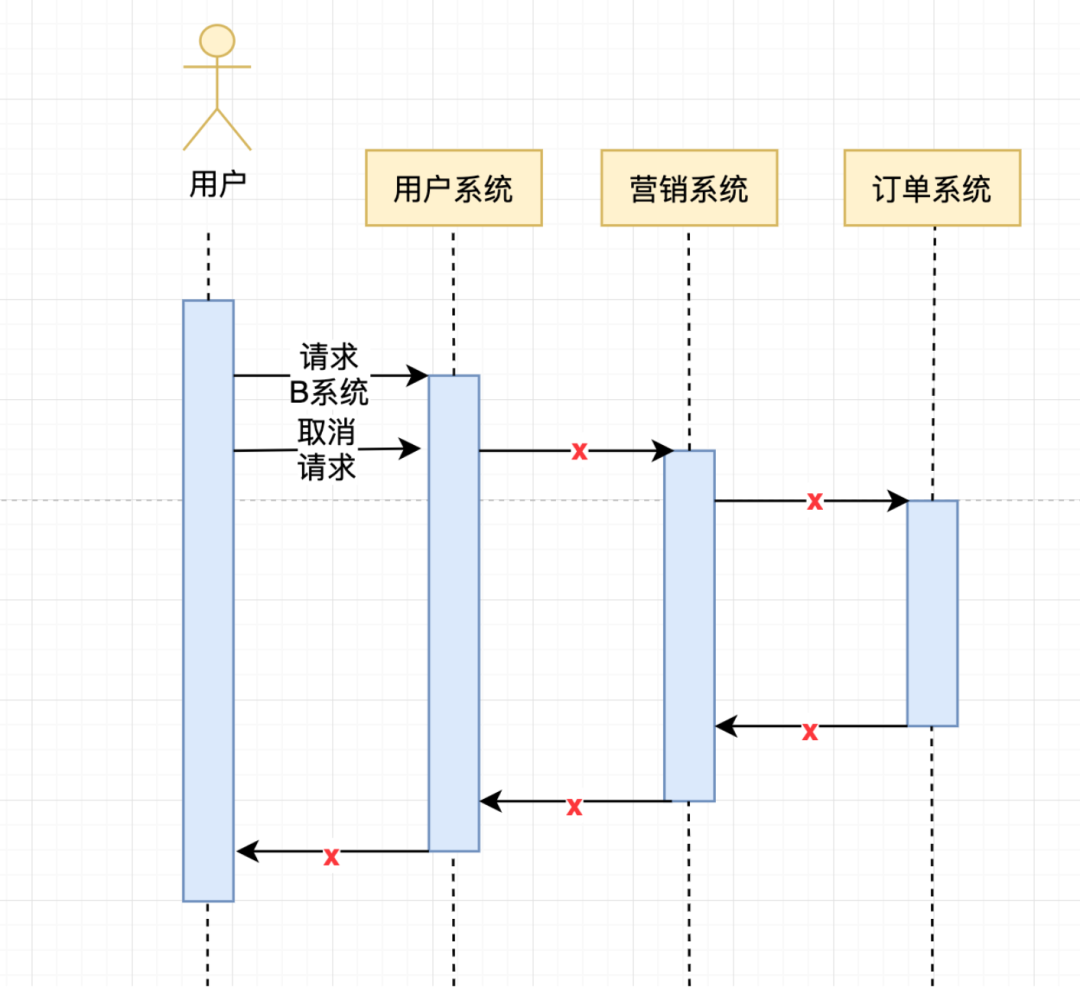
这里有份demo代码,项目启动后,可以用curl localhost:8888访问这个接口,若1s内取消请求,服务端会打印出request canceleld,正常情况下,服务会返回process finished。
func main() {
http.ListenAndServe(":8888", http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
ctx := r.Context()
fmt.Println("get request")
select {
case <-time.After(1 * time.Second):
w.Write([]byte("process finished"))
case <-ctx.Done():
fmt.Println("request canceleld")
}
}))
}
除了用户中途取消请求的情况,还有一种情况也可以用到cancelFunc:服务A的返回数据依赖服务B和服务C的相关接口,若服务B或者服务C挂了,此次请求就算失败了,没必要再访问另一个服务,此时也可以用CancelFunc。Demo如下:
func getUserInfoBySystemA(ctx context.Context) error {
time.Sleep(100 * time.Millisecond)
// 模拟请求出错的情况
return errors.New("failed")
}
func getOrderInfoBySystemB(ctx context.Context) {
select {
case <-time.After(500 * time.Millisecond):
fmt.Println("process finished")
case <-ctx.Done():
fmt.Println("process cancelled")
}
}
func main() {
ctx, cancel := context.WithCancel(context.Background())
//并发从两个服务中获取相关数据
go func() {
err := getUserInfoBySystemA(ctx)
if err != nil {
// 发生错误,调用cancelFunc
cancel()
}
}()
getOrderInfoBySystemB(ctx)
}





控制超时取消
如果你的服务对外承诺的SLA是100ms,但系统依赖的服务B的HTTP接口有点不稳定,有时50ms就能返回结果,有时100ms才能返回结果,为了保证你服务的SLA,可以用Context的WithTimeout方法设置一个超时时间,demo如下:
func main() {
// 设置超时时间100ms
ctx, _ := context.WithTimeout(context.Background(), 100*time.Millisecond)
// 构建一个HTTP请求
req, _ := http.NewRequest(http.MethodGet, "https://www.baidu.com/", nil)
// 把ctx信息传进去
req = req.WithContext(ctx)
client := &http.Client{}
// 向百度发送请求
res, err := client.Do(req)
if err != nil {
fmt.Println("Request failed:", err)
return }
fmt.Println("Response received, status code:", res.StatusCode)
}
正常情况下,会得到这样的输出:
Response received, status code: 200
如果我们请求百度超时了,会得到这样的输出:
Request failed: Get https://www.baidu.com/: context deadline exceeded


欢迎关注我的公众号~