
麻了,被字节问懵逼了!
之前有个读者在秋招面试的时候,被问了这么一个问题:SYN 报文什么时候情况下会被丢弃?
好家伙,现在面试都问那么细节了吗?
不过话说回来,这个问题跟工作上也是有关系的,因为我就在工作中碰到这么奇怪的问题。
客户端向服务端发起了连接,但是连接并没有建立起来,通过抓包分析发现,服务端是收到 SYN 报文了,但是并没有回复 SYN+ACK(TCP 第二次握手),说明 SYN 报文被服务端忽略了,然后客户端就一直在超时重传 SYN 报文,直到达到最大的重传次数。
接下来,我就给出我遇到过 SYN 报文被丢弃的两种场景:
开启 tcp_tw_recycle 参数,并且在 NAT 环境下,造成 SYN 报文被丢弃
accpet 队列满了,造成 SYN 报文被丢弃
坑爹的 tcp_tw_recycle
TCP 四次挥手过程中,主动断开连接方会有一个 TIME_WAIT 的状态,这个状态会持续 2 MSL 后才会转变为 CLOSED 状态。

在 Linux 操作系统下,TIME_WAIT 状态的持续时间是 60 秒,这意味着这 60 秒内,客户端一直会占用着这个端口。要知道,端口资源也是有限的,一般可以开启的端口为 32768~61000 ,也可以通过如下参数设置指定范围:
net.ipv4.ip_local_port_range
那么,如果如果主动断开连接方的 TIME_WAIT 状态过多,占满了所有端口资源,则会导致无法创建新连接。
但是 TIME_WAIT 状态也不是摆设作用,它的作用有两个:
防止具有相同四元组的旧数据包被收到,也就是防止历史连接中的数据,被后面的连接接受,否则就会导致后面的连接收到一个无效的数据,
保证「被动关闭连接」的一方能被正确的关闭,即保证最后的 ACK 能让被动关闭方接收,从而帮助其正常关闭;
不过,Linux 操作系统提供了两个可以系统参数来快速回收处于 TIME_WAIT 状态的连接,这两个参数都是默认关闭的:
net.ipv4.tcp_tw_reuse,如果开启该选项的话,客户端(连接发起方) 在调用 connect() 函数时,内核会随机找一个 time_wait 状态超过 1 秒的连接给新的连接复用,所以该选项只适用于连接发起方。
net.ipv4.tcp_tw_recycle,如果开启该选项的话,允许处于 TIME_WAIT 状态的连接被快速回收;
要使得这两个选项生效,有一个前提条件,就是要打开 TCP 时间戳,即 net.ipv4.tcp_timestamps=1(默认即为 1)。
但是,tcp_tw_recycle 在使用了 NAT 的网络下是不安全的!
对于服务器来说,如果同时开启了 recycle 和 timestamps 选项,则会开启一种称之为「 per-host 的 PAWS 机制」。
首先给大家说说什么是 PAWS 机制?
tcp_timestamps 选项开启之后, PAWS 机制会自动开启,它的作用是防止 TCP 包中的序列号发生绕回。
正常来说每个 TCP 包都会有自己唯一的 SEQ,出现 TCP 数据包重传的时候会复用 SEQ 号,这样接收方能通过 SEQ 号来判断数据包的唯一性,也能在重复收到某个数据包的时候判断数据是不是重传的。但是 TCP 这个 SEQ 号是有限的,一共 32 bit,SEQ 开始是递增,溢出之后从 0 开始再次依次递增。
所以当 SEQ 号出现溢出后单纯通过 SEQ 号无法标识数据包的唯一性,某个数据包延迟或因重发而延迟时可能导致连接传递的数据被破坏,比如:
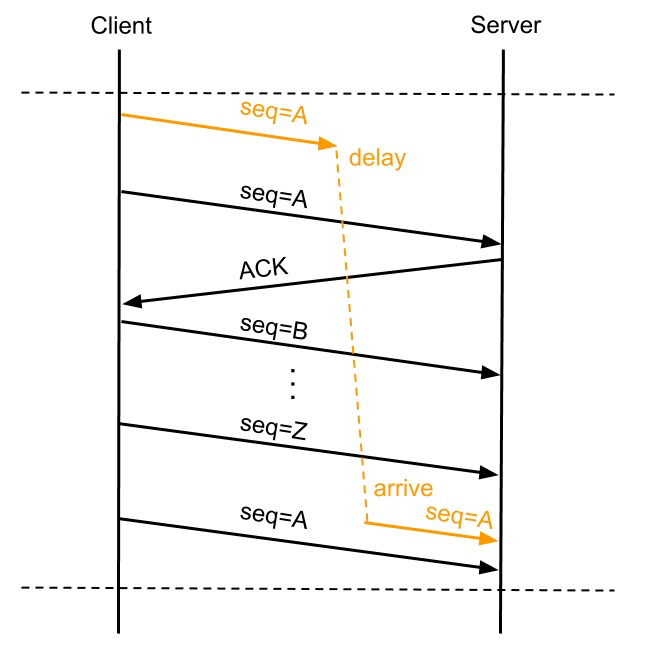
上图 A 数据包出现了重传,并在 SEQ 号耗尽再次从 A 递增时,第一次发的 A 数据包延迟到达了 Server,这种情况下如果没有别的机制来保证,Server 会认为延迟到达的 A 数据包是正确的而接收,反而是将正常的第三次发的 SEQ 为 A 的数据包丢弃,造成数据传输错误。
PAWS 就是为了避免这个问题而产生的,在开启 tcp_timestamps 选项情况下,一台机器发的所有 TCP 包都会带上发送时的时间戳,PAWS 要求连接双方维护最近一次收到的数据包的时间戳(Recent TSval),每收到一个新数据包都会读取数据包中的时间戳值跟 Recent TSval 值做比较,如果发现收到的数据包中时间戳不是递增的,则表示该数据包是过期的,就会直接丢弃这个数据包。
对于上面图中的例子有了 PAWS 机制就能做到在收到 Delay 到达的 A 号数据包时,识别出它是个过期的数据包而将其丢掉。
那什么是 per-host 的 PAWS 机制呢?
前面我提到,开启了 recycle 和 timestamps 选项,就会开启一种叫 per-host 的 PAWS 机制。
per-host 是对「对端 IP 做 PAWS 检查」,而非对「IP + 端口」四元组做 PAWS 检查。
但是如果客户端网络环境是用了 NAT 网关,那么客户端环境的每一台机器通过 NAT 网关后,都会是相同的 IP 地址,在服务端看来,就好像只是在跟一个客户端打交道一样,无法区分出来。
Per-host PAWS 机制利用TCP option里的 timestamp 字段的增长来判断串扰数据,而 timestamp 是根据客户端各自的 CPU tick 得出的值。
当客户端 A 通过 NAT 网关和服务器建立 TCP 连接,然后服务器主动关闭并且快速回收 TIME-WAIT 状态的连接后,客户端 B 也通过 NAT 网关和服务器建立 TCP 连接,注意客户端 A 和 客户端 B 因为经过相同的 NAT 网关,所以是用相同的 IP 地址与服务端建立 TCP 连接,如果客户端 B 的 timestamp 比 客户端 A 的 timestamp 小,那么由于服务端的 per-host 的 PAWS 机制的作用,服务端就会丢弃客户端主机 B 发来的 SYN 包。
因此,tcp_tw_recycle 在使用了 NAT 的网络下是存在问题的,如果它是对 TCP 四元组做 PAWS 检查,而不是对「相同的 IP 做 PAWS 检查」,那么就不会存在这个问题了。
网上很多博客都说开启 tcp_tw_recycle 参数来优化 TCP,我信你个鬼,糟老头坏的很!
tcp_tw_recycle 在 Linux 4.12 版本后,直接取消了这一参数。
accpet 队列满了
在 TCP 三次握手的时候,Linux 内核会维护两个队列,分别是:
半连接队列,也称 SYN 队列;
全连接队列,也称 accepet 队列;
服务端收到客户端发起的 SYN 请求后,内核会把该连接存储到半连接队列,并向客户端响应 SYN+ACK,接着客户端会返回 ACK,服务端收到第三次握手的 ACK 后,内核会把连接从半连接队列移除,然后创建新的完全的连接,并将其添加到 accept 队列,等待进程调用 accept 函数时把连接取出来。

在服务端并发处理大量请求时,如果 TCP accpet 队列过小,或者应用程序调用 accept() 不及时,就会造成 accpet 队列满了 ,这时后续的连接就会被丢弃,这样就会出现服务端请求数量上不去的现象。

我们可以通过 ss 命令来看 accpet 队列大小,在「LISTEN 状态」时,Recv-Q/Send-Q 表示的含义如下:

Recv-Q:当前 accpet 队列的大小,也就是当前已完成三次握手并等待服务端
accept()的 TCP 连接个数;Send-Q:当前 accpet 最大队列长度,上面的输出结果说明监听 8088 端口的 TCP 服务进程,accpet 队列的最大长度为 128;
如果 Recv-Q 的大小超过 Send-Q,就说明发生了 accpet 队列满的情况。
要解决这个问题,我们可以:
调大 accpet 队列的最大长度,调大的方式是通过调大 backlog 以及 somaxconn 参数。
检查系统或者代码为什么调用 accept() 不及时;
关于 SYN 队列和 accpet 队列,我之前写过一篇很详细的文章:TCP 半连接队列和全连接队列满了会发生什么?又该如何应对?
好了,今天就分享到这里啦。
如果有大佬还知道其他场景,欢迎评论区分享一下,让我也增加下知识哈哈。