
Guava骚操作,10分钟搞定日志脱敏需求!
你知道的越多,不知道的就越多,业余的像一棵小草!
你来,我们一起精进!你不来,我和你的竞争对手一起精进!
编辑:业余草
来源:juejin.cn/post/7274626136328257588
推荐:https://t.zsxq.com/13XQ7iuQ2
自律才能自由
❝
「Guava」之于「Javaer」,如同「Excel」之于「办公达人」。
都非常好用,但实际上大部分人只用到了其「1%不到」的功能。
❞
日志脱敏到底是个啥
「敏感信息脱敏」实际上是隶属于「安全领域」的一个子领域,而「日志脱敏」又是「敏感信息脱敏」的一个子领域。
好了,打住,不闲聊这些有的没的,直接开整:到底什么是日志脱敏?
未脱敏之前
如下有一个关于个人信息的类
public class Person {
private Long id;
private String name;
private String phone;
private String account;
// setter and gettr ...
}
在日志脱敏之前,我们一般会这样直接打印日志
log.info("个人信息:{}",JsonUtils.toJSONString(person));
然后打印完之后,日志大概是这样
个人信息:{"id":1,"name":"张无忌","phone":"17709141590","account":"14669037943256249"}
那如果是这种敏感信息打印到日志中的话,安全问题是非常大的。研发人员或者其他可以访问这些敏感日志的人就可能会故意或者不小心泄露用户的个人信息,甚至干些啥坏事。

脱敏后
那日志脱敏最后要达到什么效果呢?
如下:需要把敏感字段中的一部分字符使用特殊符号替换掉(这里我们用*来做特殊符号)
个人信息:{"id":1,"name":"**忌","phone":"177******90","account":"146*********49"}
所以,很自然的,我们就写了个「脱敏组件」,在每一个字段上用「注解」来标识每一个字段是什么类型的敏感字段,需要怎么脱敏。
比如,对于上面的个人信息,在打印日志的时候需要研发人员做两件事:
-
「使用脱敏组件提供的注解来标识敏感字段」
public class Person {
// id是非敏感字段,不需要脱敏
private Long id;
@Sensitive(type = SensitiveType.Name)
private String name;
@Sensitive(type = SensitiveType.Phone)
private String phone;
@Sensitive(type = SensitiveType.Account)
private String account;
// setter and gettr ...
}
-
「使用脱敏组件先脱敏,再打印日志」
如下,先使用脱敏组件提供的工具类脱敏个人信息,然后再打印日志
log.info("个人信息:{}", DataMask.toJSONString(person));
具体的使用和实现原理可以参考:
唯品会脱敏说明:https://github.sheincorp.cn/vipshop/vjtools/blob/master/vjkit/docs/data_masking.md。
日志脱敏遇到了什么问题
到这,还只是一般脱敏组件提供的功能范畴。也就是说,到这你基本上都可以在github上搜索到一些现成的解决方案。

但是到了企业里面,就不是说到这就已经结束了。
到了企业里面,你得满足客户(也就是研发人员)奇奇怪怪(也许只是一开始「你觉得」是奇奇怪怪,但是实际上很合理)的需求。
比如,我们就有研发人员提出:「需要按照Map中的Key来配置脱敏规则」
啥意思呢?简单来说,如果我有一个Map类型的数据,如下
Map<String,Object> personMap = new HashMap<>();
personMap.put("name","张无忌");
personMap.put("phone","17709141590");
personMap.put("account","14669037943256249");
personMap.put("id",1L);
那么在配置文件中指定好对应的key的脱敏规则后就可以把Map中的敏感数据也脱敏。
大概配置文件如下:
#指定Map中的key为name,name,account的value的脱敏规则分别是Name,Account,Phone
Name=name
Account=account
Phone=phone
那先不管需求是否合理吧,反正客户就是上帝,满足再说。
然后,我们就开始实现了。
基本思路:「复制Map」,然后遍历复制后的Map,找到Key有对应脱敏规则的value,按照脱敏规则脱敏,最后使用Json框架序列化脱敏后的Map。
public class DataMask{
// other method...
/**
* 将需要脱敏的字段先进行脱敏操作,最后转成json格式
* @param object 需要序列化的对象
* @return 脱敏后的json格式
*/
public static String toJSONString(Object object) {
if (object == null) {
return null;
}
try {
// 脱敏map类型
if (object instanceof Map) {
return return maskMap(object);
}
// 其他类型
return JsonUtil.toJSONString(object);
} catch (Exception e) {
return String.valueOf(object);
}
}
private static String maskMap(Object object) {
Map map = (Map) object;
MaskJsonStr maskJsonStr = new MaskJsonStr();
// 复制Map
HashMap<String, Object> mapClone = new HashMap<>();
mapClone.putAll(map);
Map mask = maskJsonStr.maskMapValue(mapClone);
return JsonUtil.getObjectMapper().writeValueAsString(mask);
}
}
public class MaskJsonStr{
// other method...
public Map<String, Object> maskMapValue(Map<String, Object> map) {
for (Map.Entry<String, Object> entry : map.entrySet()) {
Object val = entry.getValue();
if (val instanceof Map) {
maskMapValue((Map<String, Object>) val);
} else if (val instanceof Collection) {
Collection collVal = maskCollection(entry.getKey(), val);
map.put(entry.getKey(), collVal);
} else {
// 根据key从脱敏规则中获取脱敏规则,然后脱敏
Object maskVal = maskString(entry.getKey(), val);
if (maskVal != null) {
map.put(entry.getKey(), maskVal);
} else {
map.put(entry.getKey(), val);
}
}
}
return map;
}
}
可以说,「在整体思路上,没啥毛病」,但是往往「魔鬼就在细节中」。

看到这,也许有些大神,直接从代码中已经看出问题了。不急,我们还是悠着点来,给你10分钟思量一下先。

❝
「1」分钟
❞
❝
「2」分钟
❞
❝
「n」分钟
❞

好的,我知道的,你肯定是不会思考的。
我们直接看问题。有使用我们这个组件的研发人员找过说:我c a o,你们把我的业务对象「Map中的值修改掉了」。
我们本来想直接回怼:你们是不是姿势不对,不会用啊。但是本着严(zhi)谨(qian)的(bei)原(da)则(nian)(guo),还是问了句,你在本地复现了吗?
结果,还真被打脸了。人家既有截图,又给我们发了可复现的代码。真是打脸打到家了。

那到底是啥问题呢?按道理,我们肯定是测试过的,正常情况下不会有问题。那到底是什么场景下有问题呢?
我们发现:「有嵌套类型的Map的时候就会有问题」
测试程序如下:
@Test
public void testToJSONString() {
Map<String,Object> personMap = new HashMap<>();
personMap.put("name","张无忌");
personMap.put("phone","17709141590");
personMap.put("account","14669037943256249");
personMap.put("id",1L);
Map<String,Object> innerMap = new HashMap();
innerMap.put("name","张无忌的女儿");
innerMap.put("phone","18809141567");
innerMap.put("account","17869037943255678");
innerMap.put("id",2L);
personMap.put("daughter",innerMap);
System.out.println("脱敏后:"+DataMask.toJSONString(personMap));
System.out.println("脱敏后的原始Map对象:"+personMap);
}
输出结果如下:
脱敏后:{"name":"**忌","id":1,"phone":"177*****590","daughter":{"phone":"188*****567","name":"****女儿","id":2,"account":"1***************8"},"account":"1***************9"}
脱敏后的原始Map对象:{phone=17709141590, name=张无忌, id=1, daughter={phone=188*****567, name=****女儿, id=2, account=1***************8}, account=14669037943256249}
我们发现,脱敏时是成功的,但是却「把原始对象中的内嵌innerMap对象中的值修改了」。

❝
要知道,作为脱敏组件,你可以有点小bug,你也可以原始简单粗暴,「甚至你都可以脱敏失败」(本该脱敏的却没有脱敏),但是你「千万不能修改业务中使用的对象」啊。
❞
❝
虽然问题很大,但是我们还是要沉着应对问题,仔细分析问题。做到泰山崩于前而色不变,才是打工人的正确处事方式。不然只会「越急越慌,越慌越不冷静,最后买1送3」(修1个bug,新引入3个bug)
❞
简单debug,加上看源代码,其实这个问题还是比较容易发现的,主要问题就是在「复制Map对象的姿势不对」
❝
如下,我们是使用这样的方式来复制Map的。本来是想做「深度clone」的,但是这种事做不到深度clone的。对于有内嵌的对象的时候只能做到「浅clone」。
❞
// 复制Map
HashMap<String, Object> mapClone = new HashMap<>();
mapClone.putAll(map);
所以,只有一层关系的简单Map是可以脱敏成功的,且不会改变原来的Map。但是对于有嵌套的Map对象时,就会修改嵌套Map对象中的值了。
问题的原因是啥,如何解决,思路是啥
❝
从上面的分析中就可以得出其根本原因:没有正确地深度clone Map对象
❞
那很自然地,我们的解决思路就是找到一种合适的「深度 clone Map对象」的方式就OK了。
然后我就问ChatGPT了,ChatGPT的回答有下面几个方法
-
「使用序列化和反序列化」:通过将对象序列化为字节流,然后再将字节流反序列化为新的对象,可以实现深度克隆。需要注意被克隆的对象及其引用类型成员变量都需要实现Serializable接口。
-
「使用第三方库」:除了上述两种方式,还可以使用一些第三方库,例如Apache Commons的SerializationUtils类、Google的Gson库等,它们提供了更简洁的方法来实现深度克隆。
-
「使用JSON序列化和反序列化」:将对象转换为JSON字符串,然后再将JSON字符串转换为新的对象。需要使用JSON库,如Jackson、Gson等。
-
「使用Apache Commons的BeanUtils类」:BeanUtils提供了一个 cloneBean()方法,可以对JavaBean进行深度克隆。需要注意,被克隆的对象及其引用类型成员变量都需要实现Serializable接口。
-
「最佳实践是根据需求和具体情况灵活应用」,或者采用第三方库实现对象克隆,如 Apache Commons BeanUtils、Spring BeanUtils 等。
上面几个方式基本上可以分为3类:
-
「序列化和反序列化」:JDK自带的序列化(需要实现 Serializable接口);利用Gson,FastJson,Jackson等JSON序列化工具序列化后再反序列化;其他序列化框架序(如Hessain等)列化反序列化
-
「利用第三方库」:第三方库直接clone对象。但都有一定的限定条件
-
「视情况而定」:基本上没有一种通用的方法,可以适配是有的深度clone场景。所以ChatGPT提出了这一种不是办法的办法
根据上面的一番探索,发现还得自己敲代码造轮子。

❝
那其实你仔细分析后发现:我们确实不需要通用的深度clone对象的能力。我们只需要把Map类型深度clone好就行,对于其他自定义DTO,我们是不需要深度clone的。
❞
然后就是卡卡一顿猛敲,如下:常规递归操作
public class MapUtil {
private MapUtil() {
}
public static <K, V> Map<K, V> clone(Map<K, V> map) {
if (map == null || map.isEmpty()) {
return map;
}
Map cloneMap = new HashMap();
for (Map.Entry<K, V> entry : map.entrySet()) {
final V value = entry.getValue();
final K key = entry.getKey();
if (value instanceof Map) {
Map mapValue = (Map) value;
cloneMap.put(key, clone(mapValue));
} else if (value instanceof Collection) {
Collection collectionValue = (Collection) value;
cloneMap.put(key, clone(collectionValue));
} else {
cloneMap.put(key, value);
}
}
return cloneMap;
}
public static <E> Collection<E> clone(Collection<E> collection) {
if (collection == null || collection.isEmpty()) {
return collection;
}
Collection clonedCollection;
try {
// 有一定的风险会反射调用失败
clonedCollection = collection.getClass().newInstance();
} catch (InstantiationException | IllegalAccessException e) {
// simply deal with reflect exception
throw new RuntimeException(e);
}
for (E e : collection) {
if (e instanceof Collection) {
Collection collectionE = (Collection) e;
clonedCollection.add(clone(collectionE));
} else if (e instanceof Map) {
Map mapE = (Map) e;
clonedCollection.add(clone(mapE));
} else {
clonedCollection.add(e);
}
}
return clonedCollection;
}
}
然后,又是一波Junit操作,嘎嘎绿灯,收拾完事。

貌似,到这我们就可以下班了。

但是,等等,这篇文章貌似,好像,的确,应该缺点啥吧?
这尼玛不是讲的是Guava吗,到这为止,貌似跟Guava毛关系没有啊!!!

那我们继续,容你再思考一下,到现在为止,我们的深度clone方案有什么问题。
好的,我懂的。咱看到这,图的就是一个乐,你让我思考,这不是强人所难吗
❝
思考,思考是不可能存在的。
❞

❝
那咱们就直接看问题:就是啥都好,问题就是「性能比较差!!!」
❞
如果你是一个老司机,你可能看到上面的代码就已经感觉到了,性能是相对比较低的。
❝
基本上,Map层级越深,字段越多,内嵌的集合对象元素越多,性能越差!!!
❞
至于差到什么程度,其实是可以通过 微基准测试框架「JMH」来实际测试一下就知道了。这里我就不测试了。
❝
那我们还有什么办法来解决这个性能问题吗?
❞
如果我们还是集中于深度clone对象上做文章,去找寻性能更高的深度clone框架或者是类库的话,那么其实这个问题就已经「走偏」了。
我们再来回顾一下我们之前的问题:
❝
我们需要对Map对象按照key来脱敏,所以我们选择了深度clone Map,然后对Map遍历按照key脱敏后序列化。
❞
❝
那其实我们最终要解决的问题是:Map对象序列化后的字符串得是按照key的脱敏规则脱敏后的字符串。
❞
所以,其实我们除了深度clone这一条路外,还有另外两条路:
-
1.「自定义Map类型的序列化器」:在序列化Map的时候,如果有脱敏规则则应用脱敏规则来序列化Map
-
2.「转换Map为脱敏后的Map」:自定义Map对象,将脱敏规则作为转换函数来把普通的Map转换为脱敏的Map
对于第一种方式,要看你使用的Json框架是否支持(一般Map类型用的都是内置的Map序列化器,不一定可以自定义)。
那第二种方式,到底应该如何玩呢. 如下:
// 脱敏转换函数
public interface MaskFunction<K, V, E> {
/**
* @param k key
* @param v value
* @return 根据key和value得到脱敏(如果有需要的话)后的值
*/
E mask(K k, V v);
}
// 自定义MaskMap对象,经过MaskFunction函数,将普通Map转换为脱敏后的Map
public class MaskMap extends HashMap {
private MaskFunction maskFunction;
public MaskMap(MaskFunction maskFunction) {
this.maskFunction = maskFunction;
}
@Override
public Object get(Object key) {
Object value = super.get(key);
if (value == null) {
return null;
}
return maskFunction.mask(key, value);
}
// other function to override ...
}
如上,Map不再是「clone」的玩法,而是「转换」的玩法,所以,这种操作是非常「轻量级」的。
但是这种玩法也有缺点:比较麻烦,需要override好多方法(不然就需要熟读Map序列化器来找到最小化需要override的方法,并且不太靠谱),并且全部都要是「转换」的玩法。
终于,终于,终于,这个时候该轮到我们「Guava」登场了。

Guava登场
用过Guava的人都知道,Guava中很多好用的方法,但是我们平常用的多的也就是那几个。所以这个时候你说需要转换Map,那我们是不是可以去Guava中看看有没有现成的方案,没准有惊喜!!!

一看就是惊喜:
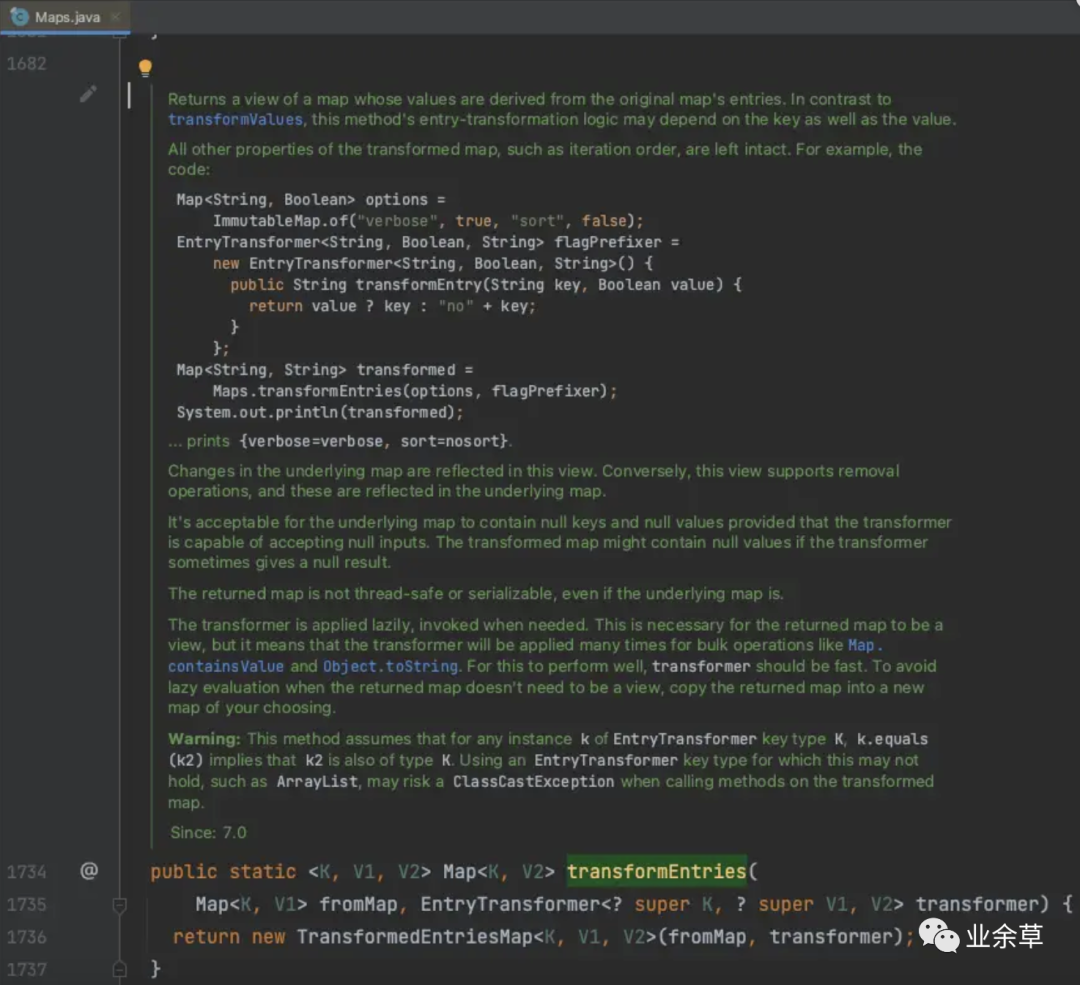
Maps#transformEntries(Map<K,V1>, Maps.EntryTransformer<? super K,? super V1,V2>)
❝
Returns a view of a map whose values are derived from the original map's entries. In contrast to transformValues, this method's entry-transformation logic may depend on the key as well as the value. All other properties of the transformed map, such as iteration order, are left intact.
❞
❝
返回一个Map的试图,其中它的值是从原来map中entry派生出来的。相较于transformValues方法,这个基于entry的转换逻辑是既依赖于key又依赖于value。变换后的映射的所有其他属性(例如迭代顺序)均保持不变
❞
这不正是我们上面需要实现的 MaskMap吗!!!
除此之外,我们还需要支持,对集合类型的脱敏「转换」,再去看一下呢,又是惊喜!!!
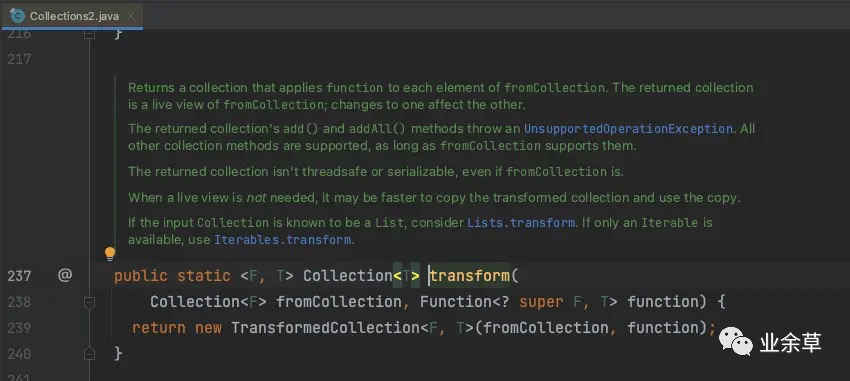
到这,基本上,我们已经在Gauva中找到了我们所需要的全部元素了。下面就是简单集合脱敏规则使用下就好了
public class MaskEntryTransformer implements Maps.EntryTransformer<Object, Object, Object> {
private static final Maps.EntryTransformer<Object, Object, Object> MASK_ENTRY_TRANSFORMER = new MaskEntryTransformer();
private MaskEntryTransformer() {
}
public static Maps.EntryTransformer<Object, Object, Object> getInstance() {
return MASK_ENTRY_TRANSFORMER;
}
@Override
public Object transformEntry(Object objectKey, Object value) {
if (value == null) {
return null;
}
if (value instanceof Map) {
Map valueMap = (Map) value;
return Maps.transformEntries(valueMap, this);
}
final Maps.EntryTransformer<Object, Object, Object> thisFinalMaskEntryTransformer = this;
if (value instanceof Collection) {
Collection valueCollection = (Collection) value;
if (valueCollection.isEmpty()) {
return valueCollection;
}
return Collections2.transform(valueCollection, new Function<Object, Object>() {
@Override
public Object apply(Object input) {
if (input == null) {
return null;
}
if (input instanceof Map) {
Map inputValueMap = (Map) input;
return Maps.transformEntries(inputValueMap, thisFinalMaskEntryTransformer);
}
if (input instanceof Collection) {
Collection inputValueCollection = (Collection) input;
return Collections2.transform(inputValueCollection, this);
}
if (!(objectKey instanceof String)) {
return input;
}
final String key = (String) objectKey;
return transformPrimitiveType(key, input);
}
});
}
if (!(objectKey instanceof String)) {
return value;
}
final String key = (String) objectKey;
return transformPrimitiveType(key, value);
}
/**
* 按照脱敏规则脱敏基本数据类型
*
* @param key
* @param value
* @return
*/
private Object transformPrimitiveType(final String key, final Object value) {
// ...
}
}
那脱敏的地方只要转换一下Map就可以了,如下:
public class DataMask {
/**
* 将需要脱敏的字段先进行脱敏操作,最后转成json格式
* @param object 需要序列化的对象
* @return 脱敏后的json格式
*/
public static String toJSONString(Object object) {
if (object == null) {
return null;
}
try {
if (object instanceof Map) {
Map maskMap = Maps.transformEntries((Map) object, MaskEntryTransformer.getInstance());
return JsonUtil.toJSONString(maskMap);
}
return JsonUtil.toJSONString(object, jsonFilter);
} catch (Exception e) {
return object.toString();
}
}
}
一点疑问
我们调用了transformEntries方法,是可以根据key(可以找到脱敏规则)和value(可以判断类型)来转换的。但是Map中的有些API实际上可能只有value(比如values())或者只有key(比如get()方法)的,那这种EntryTransformer是如何生效的?
❝
你是不是有那么一点好奇呢?
❞
我们就不去想了,直接看代码:
-
对于get()方,只有key参数:
但是比较容易通过key拿到对应的value,然后把key和value传给转换函数就可以了
public V2 get(Object key) {
V1 value = fromMap.get(key);
return (value != null || fromMap.containsKey(key))
? transformer.transformEntry((K) key, value)
: null;
}
❝
这里的实现其实有一个细节,不知道大家注意没有。
就是这一个判断:
❞(value != null || fromMap.containsKey(key)),我们上面实现的时候直接没有考虑到值为null的情况(但value为null,但是有对应的key的时候还是应该要调用转换函数的)
-
对于values()方,只返回值
public Collection<V2> values() {
return new Values<K, V2>(this);
}
也是一样,返回一个转换后的 Collection,其中Collection中的值也是经过 transformer转换的。
而对于迭代器也是一样的,都有对应的实现类把转换逻辑放进去了。
Guava闲聊
Guava的Veiw思想
其实上面的这种 Veiw的基本思想,在Guava中有非常多的场景应用的,如
-
com.google.common.base.Splitter#split
-
com.google.common.collect.Lists#partition
-
com.google.common.collect.Sets#difference
-
...other
❝
这种
❞Veiw的基本思想,其实就是「懒加载」的思想:「在调用的时候不实际做转换,而是在实际使用的时候会做转换」
比如:com.google.common.base.Splitter#split在调用的时候实际上并不是立刻马上去分隔字符串,而是返回一个Iterable的View对象。只是在实际迭代这个Iterable的View对象时才会实际去切分字符串。
在比如com.google.common.collect.Sets#difference在调用的时候并不会立刻马上去做两个集合的差操作,而是返回一个 SetView的View对象,只有在实际使用这个View对象的API的时候才会真正做差操作。
❝
注意点:这种思想大部分场景下,会是性能友好型的,但是也有例外。我们要分清楚场景。
比如,分割字符串的方法
❞com.google.common.base.Splitter#split,如果调用完之后不做任何操作,或者只会遍历一次(大部分场景都是只遍历一次),那么这其实就是最好的方法。但是如果调用完之后,还需要遍历很多次,那么这种场景下,性能可能不是最好的。
❝
所以,对于我们来讲,如果Guava工具包中没有我们需要的
❞View的方法,那么我们可以自己按照这个思想来造一个。如果已经有了,要区分场景使用.
简单聊一下Guava API的兼容性
升级过Guava版本的同学可能深有体会,升级Guava是一件比较头疼的事情。因为「Gauva API的兼容性是做得很差」的。(当然这里主要还是因为大部分同学没有认真阅读官方的文档导致的)
因为,官网首页就直接提醒了Guava API的兼容性原则:

具体请参考:Guava官网https://guava.dev/。
这对于我们做基础组件的同学来讲,是一件尤其需要注意的事情。因为一旦使用了前后不兼容的API,那么使用组件的应用很可能因为API不兼容,导致无法运行的问题。
❝
所以对于做组件的同学,对于Guava的使用一定要慎重:能不用就不用,必须要用的话一定不能使用以
❞@Beta注解标注的方法或者类。
总结
Gauva确实是一个保藏库,当你要造轮子的时候不妨先看看Gauva中有没有现成的轮子。每看一次,也许就多一次惊喜。
这一次是Map对象脱敏场景遇上了Guava的 Maps#transformEntries(Map<K,V1>, .Maps.EntryTransformer<? super K,? super V1,V2>) ,那么你又有什么场景偶遇了Guava呢?,可以在评论区聊一下。