
世纪佳缘水分有多大?

文 | 某某白米饭
来源 | Python 技术

今天在知乎上看到一个关于【世纪佳缘找对象靠谱吗?】的讨论,其中关注的人有 1903,被浏览了 1940753 次,355 个回答中大多数都是不靠谱。用 Python 爬取世纪佳缘的数据是否能证明它的不靠谱?

一、数据抓取
在 PC 端打开世纪佳缘网站,搜索 20 到 30 岁、不限地区的女朋友

翻了几页找到一个 search_v2.php 的链接,它的返回值是一个不规则的 json 串,其中包含了昵称、性别、是否婚配、匹配条件等等
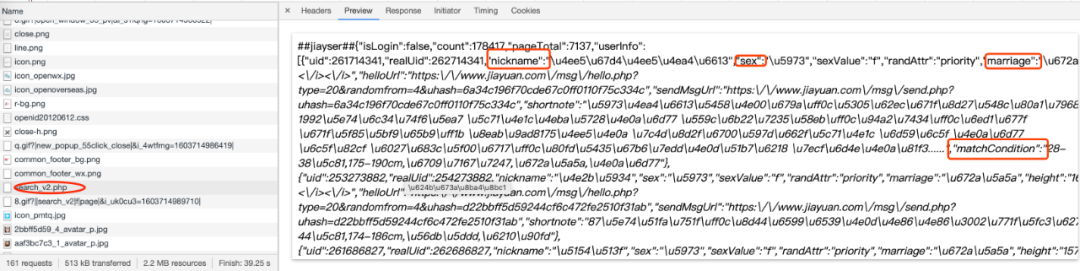
点开 Hearders 拉到最下面,在它的参数中 sex 是性别、stc 是年龄、p 是分页、listStyle 是有照片
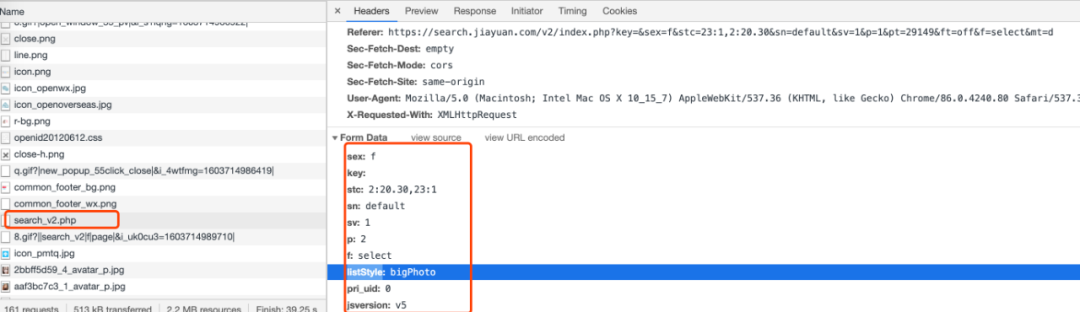
通过 url + 参数的 get 方式,抓取了 10000 页的数据总共 240116

需要安装的模块有 openpyxl,用于过滤特殊的字符
# coding:utf-8
import csv
import json
import requests
from openpyxl.cell.cell import ILLEGAL_CHARACTERS_RE
import re
line_index = 0
def fetchURL(url):
headers = {
'accept': '*/*',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36',
'Cookie': 'guider_quick_search=on; accessID=20201021004216238222; PHPSESSID=11117cc60f4dcafd131b69d542987a46; is_searchv2=1; SESSION_HASH=8f93eeb87a87af01198f418aa59bccad9dbe5c13; user_access=1; Qs_lvt_336351=1603457224; Qs_pv_336351=4391272815204901400%2C3043552944961503700'
}
r = requests.get(url, headers=headers)
r.raise_for_status()
return r.text.encode("gbk", 'ignore').decode("gbk", "ignore")
def parseHtml(html):
html = html.replace('\\', '')
html = ILLEGAL_CHARACTERS_RE.sub(r'', html)
s = json.loads(html,strict=False)
global line_index
userInfo = []
for key in s['userInfo']:
line_index = line_index + 1
a = (key['uid'],key['nickname'],key['age'],key['work_location'],key['height'],key['education'],key['matchCondition'],key['marriage'],key['shortnote'].replace('\n',' '))
userInfo.append(a)
with open('sjjy.csv', 'a', newline='') as f:
writer = csv.writer(f)
writer.writerows(userInfo)
if __name__ == '__main__':
for i in range(1, 10000):
url = 'http://search.jiayuan.com/v2/search_v2.php?key=&sex=f&stc=23:1,2:20.30&sn=default&sv=1&p=' + str(i) + '&f=select&listStyle=bigPhoto'
html = fetchURL(url)
print(str(i) + '页' + str(len(html)) + '*********' * 20)
parseHtml(html)二、去重
在处理数据去掉重复的时候发现有好多重复的,还以为是代码写的有问题呢,查了好久的 bug 最后才发现网站在 100 页只有的数据有好多重复的,下面两个图分别是 110 页数据和 111 页数据,是不是有很多熟面孔。
110 页数据

111 页数据
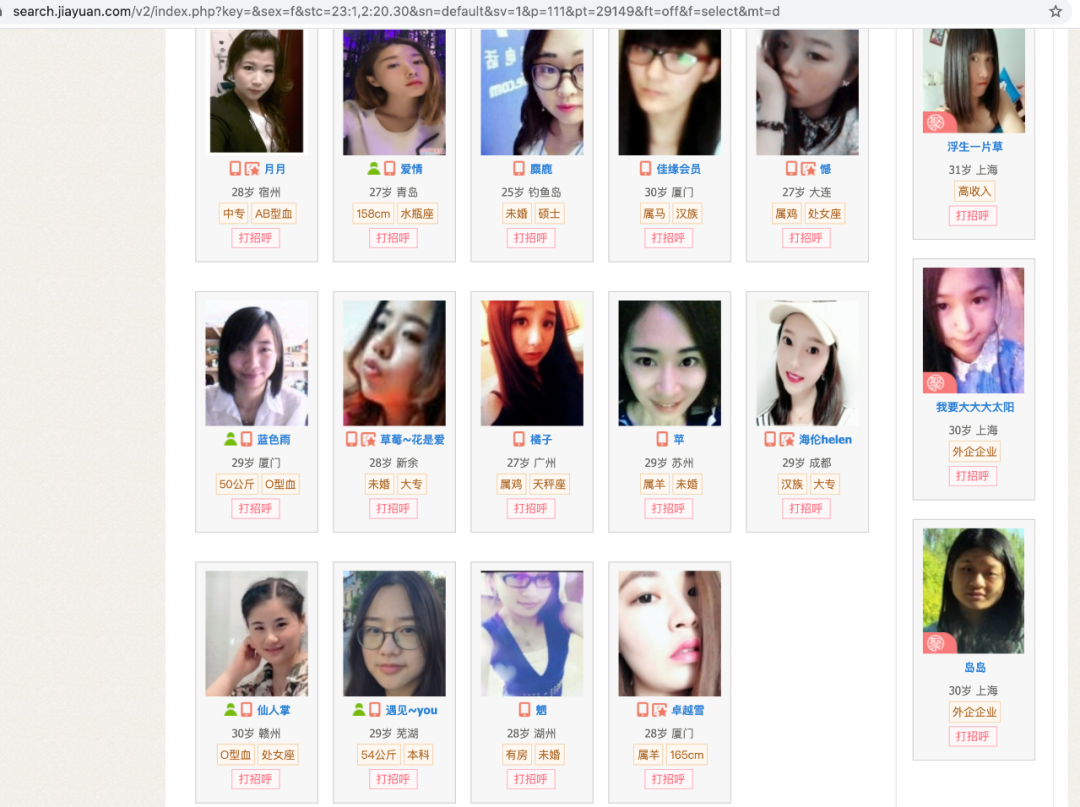
过滤重复后的数据只剩下 1872 了,这个水分还真大
def filterData():
filter = []
csv_reader = csv.reader(open("sjjy.csv", encoding='gbk'))
i = 0
for row in csv_reader:
i = i + 1
print('正在处理:' + str(i) + '行')
if row[0] not in filter:
filter.append(row[0])
print(len(filter))
源码:https://github.com/JustDoPython/python-examples/tree/master/moumoubaimifan/sjjy
总结
数量水分都如此之大,其他的还能相信嘛?
交友需谨慎,用好 Python 走遍网络都不怕。
评论