
如何让帕累托分析积累占比的曲线是光滑的
老板说希望看到帕累托分析的曲线是光滑的,虽然有的元素的确相等。
问题
在做帕累托分析的时候,默认的算法是没有问题的,例如:
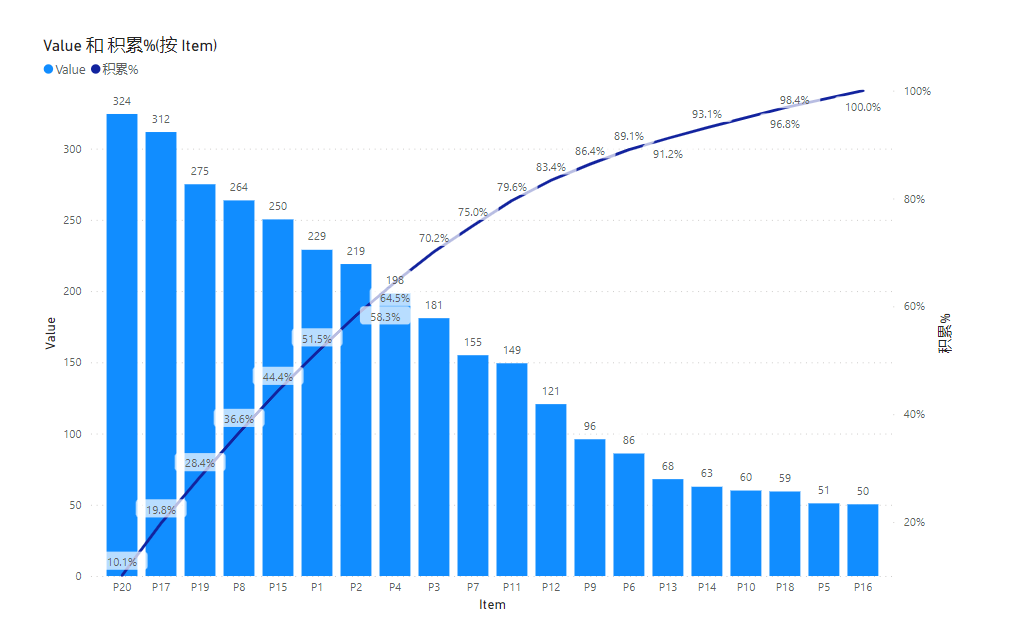
但巧合的是这里的柱子都是不一样高的,那么如果遇到一样高的柱子就会在理论上出现另一种效果,如下:
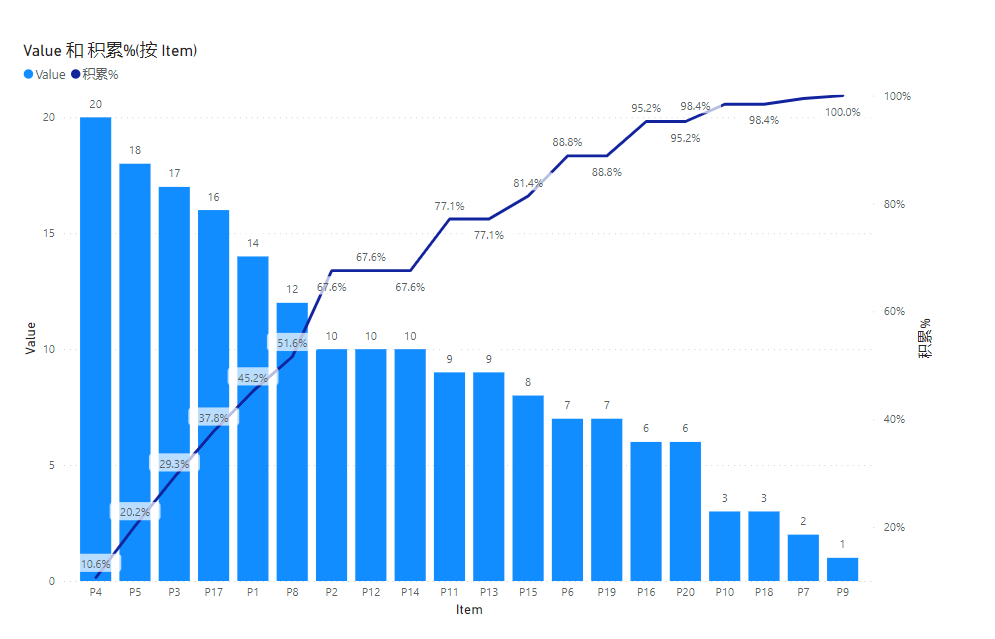
这个效果在理论上的确是正确的,但问题是老板是非常希望看到平滑的曲线的。怎么办?
数据模型
为了方便,这里用 DAX 构建一个单表数据模型,如下:
Data =
VAR vNumber = 20
RETURN
GENERATEALL(
SELECTCOLUMNS( GENERATESERIES( 1 , vNumber ) , "Index" , [Value] ) ,
SELECTCOLUMNS(
{ ( "P" & [Index] , RANDBETWEEN( 1 , 10 ) ) } ,
"Item" , [Value1] , "Value" , [Value2]
)
)其中,修改 vNumber 可以修改生成元素的个数。效果如下:
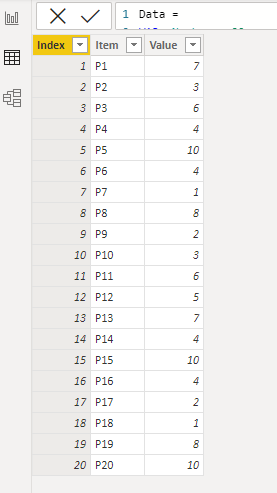
这里有一个叫 Index 的列,但在实际中的模型可能更加复杂,且不带 Index 列,因此,文章的后续讨论是不带有 Index 列的,以确保通用性。
理想效果
老板希望看到的理想效果是平滑曲线,如下:
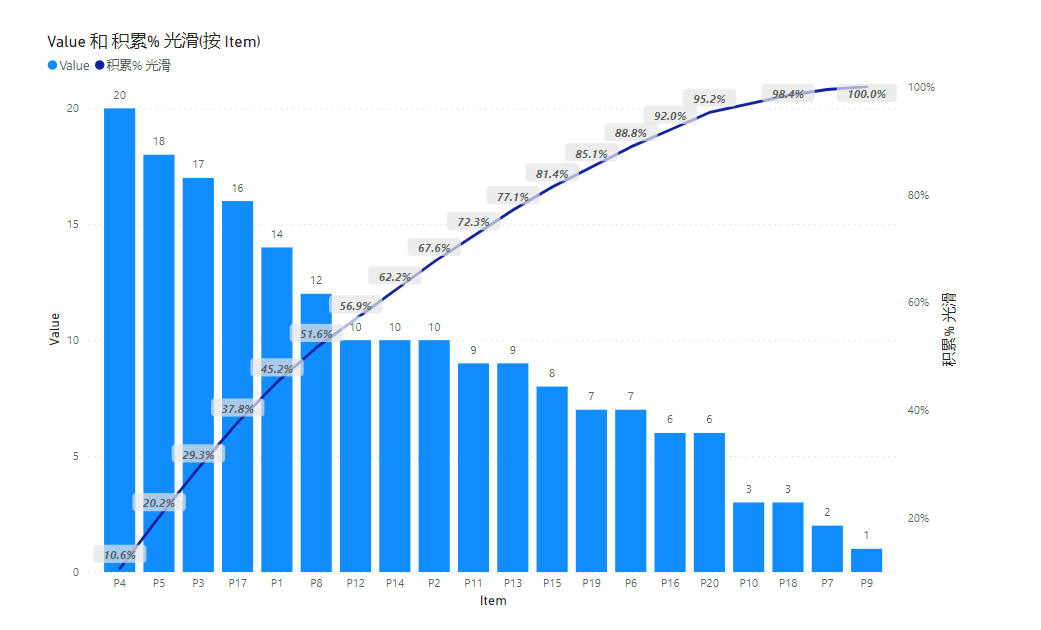
虽然图中的柱子有很多一样高度的,但应该仍然呈现积累的效果。
注意:
柱子一样高时,排名先后可以随机。
另外有一个细节,就是图表的第一棵柱子的开始位置,如下:
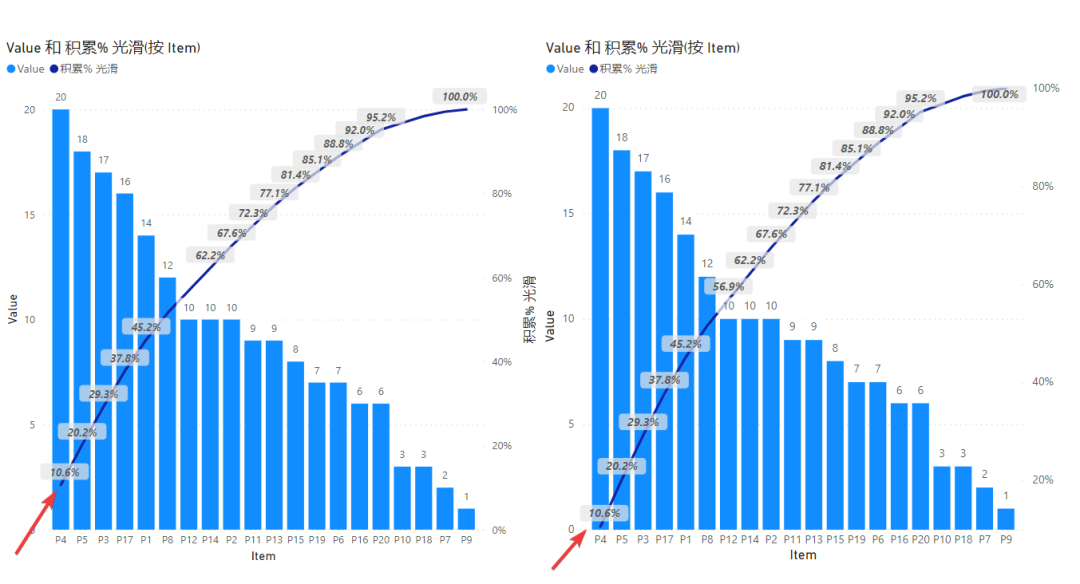
左图的开始位置有一截高度,而右图是从最底部开始的。
老板说,他想要右图的效果,于是必须轻松秒杀。
积累占比的默认公式
积累占比的默认公式有不少写法,但这里给出最优写法(没有之一),如下:
积累% =
VAR vTable =
CALCULATETABLE(
ADDCOLUMNS( VALUES( Data[Item] ) , "@Value" , CALCULATE( SUM( Data[Value] ) ) )
,
ALLSELECTED( )
)
VAR vValueCurrent = SUM( Data[Value] )
RETURN SUMX( FILTER( vTable , [@Value] >= vValueCurrent ) , [@Value] ) / SUMX( vTable , [@Value] )由于 BI 佐罗 已经发布了【视图层计算通用设计模式】,因此,我们所有 DAX 公式都会据此重构,其中思想不再重复。
以上写法没有问题,但对于伪问题,如下:
没有得到益处。
积累占比的优化
将积累占比的公式优化一下,轻松秒杀这个问题,如下:
积累% 光滑 =
VAR vTable =
CALCULATETABLE(
ADDCOLUMNS(
ADDCOLUMNS( VALUES( Data[Item] ) ,
"@Index" , RANKX( VALUES( Data[Item] ) , [Item] ) ,
"@Value" , CALCULATE( SUM( Data[Value] ) )
) ,
"@ValueIndex" , INT( [@Value] ) + ( COUNTROWS( VALUES( Data[Item] ) ) * 10 )
)
,
ALLSELECTED( )
)
VAR vValueIndex = SUMX( FILTER( vTable , [Item] = SELECTEDVALUE( Data[Item] ) ) , [@ValueIndex] )
RETURN SUMX( FILTER( vTable , [@ValueIndex] >= vValueIndex ) , [@Value] ) / SUMX( vTable , [@Value] )下面来描述一下这个思想:
由于比对大小时会遇到大小相等的元素,所以需要进行一个额外对比,但额外进行的对比又必须不能影响主对比结果,所以我们构建一个用来对比的索引,将内容:
EVALUATE
ADDCOLUMNS(
ADDCOLUMNS( VALUES( Data[Item] ) , "@Index" , RANKX( VALUES( Data[Item] ) , [Item] ) , "@Value" , CALCULATE( SUM( Data[Value] ) ) ) ,
"@ValueIndex" , INT( [@Value] ) + [@Index] / 100
)放入 DAX Studio 中,如下:
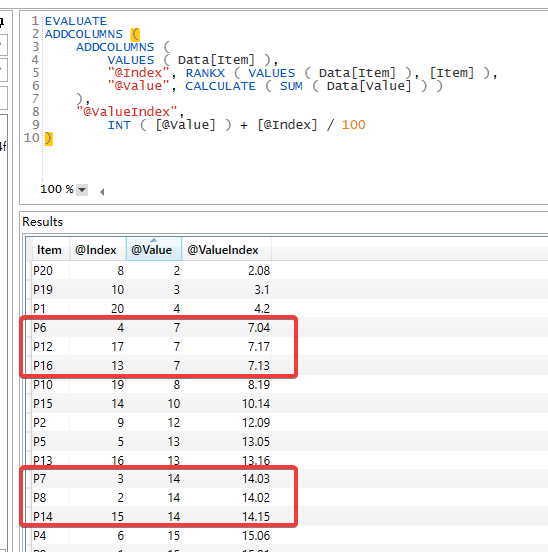
这里构建了一个用来对比的表,而且确保不会出现重复的值,其方法在于:
INT 对原值取整,作为对比索引值的整数部分。
Item 名称的排序除以一个大的基数,作为对比索引的小数部分。
其中的巧妙思想在于用排名的方法得到小数部分,如下:
"@Index" , RANKX( VALUES( Data[Item] ) , [Item] )且如何设定一个合理的分母,如下:
( COUNTROWS( VALUES( Data[Item] ) ) * 10 )在最终计算时便可以利用上述信息进行比对,如下:
SUMX( FILTER( vTable , [@ValueIndex] >= vValueIndex ) , [@Value] ) / SUMX( vTable , [@Value] )这里充分体现了 SUMX 可以声东击西的特质,用 [@ValueIndex] 与 vValueIndex 比对大小,但求和的却是 [@Value]。
最终效果
通过上述优化,轻松秒杀了帕累托分析中无法平滑显示的问题,且轻松有效的显示。如下:
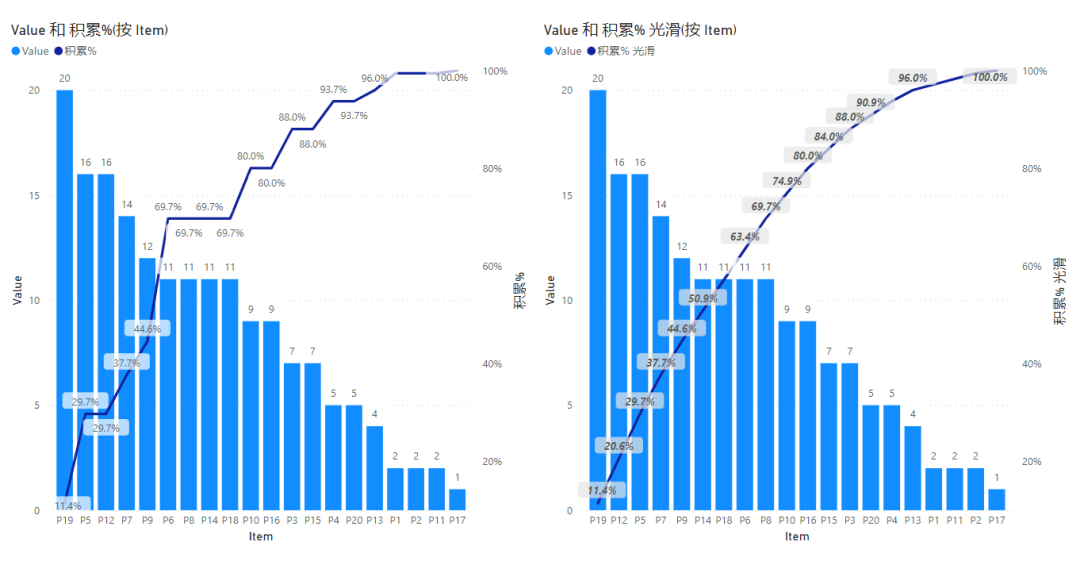
这样我们就得到了右边的效果。
且本文给出了构建平滑帕累托积累 % 的通用算法模板,可以直接套用。
扫码入社群,看视频讲解