
分享一个使用Python网络爬虫抓取百度tieba标题和正文图片(xpath篇)
回复“资源”即可获赠Python学习资料
大家好,我是皮皮。
一、前言
前几天在Python钻石交流群有个叫【嗨!罗~】的粉丝问了一道关于百度贴吧标题和正文图片网络爬虫的问题,获取源码之后,发现使用xpath匹配拿不到东西,从响应来看,确实是可以看得到源码的。上一篇文章我们使用了正则表达式获取到了目标数据,这篇文章,我们使用xpath来进行实现。
二、实现过程
究其原因是返回的响应里边并不是规整的html格式,所以直接使用xpath是拿不到的。这里【月神】给了一份代码,使用xpath实现的。
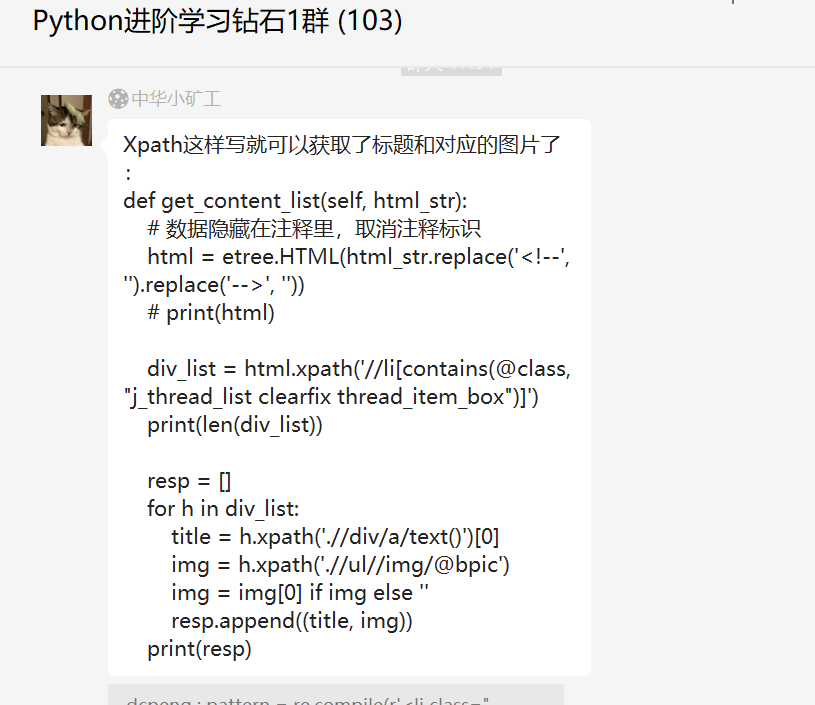
# coding:utf-8
# @Time : 2022/5/2 10:46
# @Author: 皮皮
# @公众号: Python共享之家
# @website : http://pdcfighting.com/
# @File : 百度贴吧.py
# @Software: PyCharm
import requests
from lxml import etree
class TiebaSpider:
def __init__(self, name):
self.start_url = "https://tieba.baidu.com/f?kw=" + name + "&ie=utf-8&pn=0"
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36",
"Cookie": "你的cookie"
}
def paser_url(self, url): # 发送请求,获取响应
response = requests.get(url, headers=self.headers)
return response.content.decode()
# 第一种方法:正则表达式
# 第二种方法:xpath提取
def get_content_list(self, html_str):
# 数据隐藏在注释里,取消注释标识
html = etree.HTML(html_str.replace('', ''))
# print(html)
div_list = html.xpath('//li[contains(@class,"j_thread_list clearfix thread_item_box")]')
print(len(div_list))
resp = []
for h in div_list:
title = h.xpath('.//div/a/text()')[0]
img = h.xpath('.//ul//img/@bpic')
img = img[0] if img else ''
resp.append((title, img))
print(resp)
def run(self):
# 1.start_url
# 2.发送请求,获取响应
html_str = self.paser_url(self.start_url)
# print(html_str)
# 3.提取数据,提取下一页的url地址
self.get_content_list(html_str)
# 4.保存数据
if __name__ == '__main__':
tieba_spider = TiebaSpider("李毅")
tieba_spider.run()
这个代码亲测好使,运行之后结果如下。
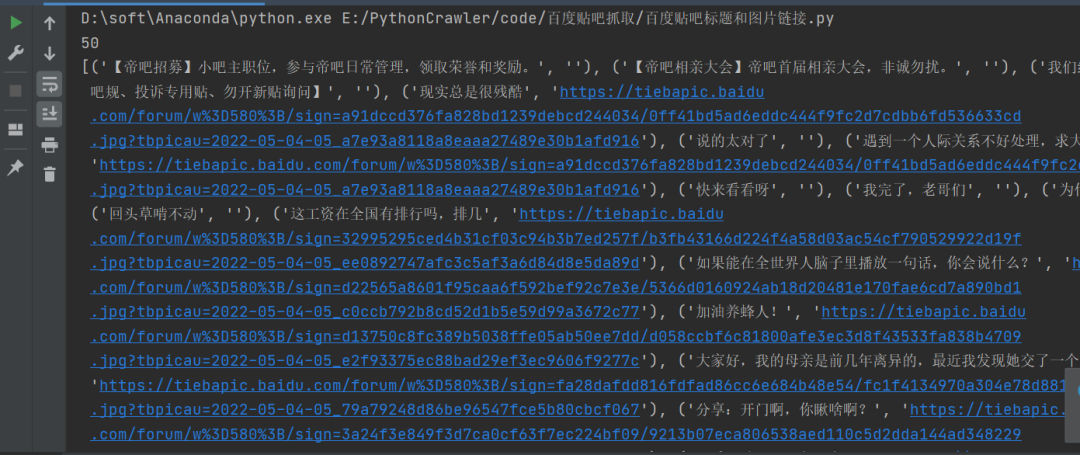
三、总结
大家好,我是皮皮。这篇文章主要分享一个使用Python网络爬虫抓取百度tieba标题和正文图片(xpath篇),行之有效。下一篇文章,将给大家分享使用bs4来提取百度贴吧的标题和正文图片链接,也欢迎大家积极尝试,一起学习。
最后感谢粉丝【嗨!罗~】提问,感谢【dcpeng】、【月神】在运行过程中给出的代码建议,感谢粉丝【猫药师Kelly】等人参与学习交流。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
评论