
面试官:Redis 为什么把简单的字符串设计成 SDS?
最近有小伙伴分享了一道 Redis 面试题,我看了以后觉得挺有意思。题目很简单,是那种典型的似懂非懂,常常容易被大家忽略的问题。这里整理出来分享一下,顺便自己巩固一下基础,希望对正在面试和想要面试的兄弟有点帮助。
题目大致是这样的:
面试官:了解redis的String数据结构底层实现嘛?
铁子:当然知道,是基于 SDS 实现的。
面试官:Redis 是用 C 语言开发的,那为啥不直接用 C 的字符串,还单独设计 SDS 这样的结构呢?
铁子:·····

实看得出面试官是想看看,铁子是只停留在 Redis 的使用层面,还是对底层数据结构有过更深入的研究,面试嘛都爱这样问大家都懂得。
我们知道 Redis 是用 C 写的,但它却没有完全直接使用 C 的字符串,而是自己又重新构建了一个叫简单动态字符串 SDS(simple dynamic string)的抽象类型。
Redis 也支持使用 C 语言的传统字符串,只不过会用在一些不需要对字符串修改的地方,比如静态的字符输出。
而我们开发中使用 Redis,往往会经常性的修改字符串的值,这个时候就会用 SDS 来表示字符串的值了。
有一点值得注意:在 Redis 数据库中,key-value 键值对含有字符串值的,都是由 SDS 来实现的。
比如,在 Redis 执行一个最简单的 set 命令,这时 Redis 会新建一个键值对。
127.0.0.1:6379> set xiaofu "程序员内点事"此时键值对的 key 和 value 都是一个字符串对象,而对象的底层实现分别是两个保存着字符串 xiaofu 和程序员内点事的 SDS 结构。
再比如:我向一个列表中压入数据,Redis 又会新建一个键值对。
127.0.0.1:6379> lpush xiaofu "程序员内点事" "程序员小富"这时候键值对的键和上边一样,还是一个由 SDS 实现的字符串对象,键值对的值是一个包含两个字符串对象的列表对象了。而这两个对象的底层也是由 SDS 实现。
SDS 结构
一个 SDS 值的数据结构,主要由 len、free、buf[] 这三个属性组成。
struct sdshdr{int free; // buf[]数组未使用字节的数量int len; // buf[]数组所保存的字符串的长度char buf[]; // 保存字符串的数组}
其中,buf[] 为实际保存字符串的 char 类型数组。free 表示 buf[] 数组未使用字节的数量, len 表示 buf[] 数组所保存的字符串的长度。
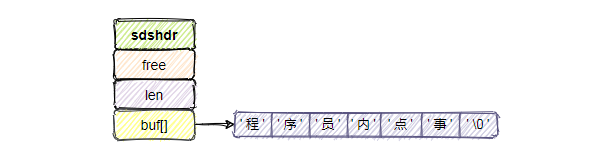
例如上图表示的是 buf[] 保存长度为 6 个字节的字符串,未使用的字节数 free 为 0,但是眼尖的同学会发现这明明是 7 个字符,还有一个"\0"啊?
上边提到过 SDS 没有完全直接使用 C 的字符串,还是沿用了一些 C 特性的,比如遵循 C 的字符串以空格符结尾的规则。这样还可以使用一部分 C 字符串的函数。而对于 SDS 来说,空字符串占用的一字节是不计算在 len 属性里的,会为他分配额外的空间。
简单了解 SDS 结构后,下边我们来看看 SDS 相比于 C 字符串有哪些优点。
效率高
举个例子:
工作中使用 Redis,经常会通过 STRLEN 命令得到一个字符串的长度,在 SDS 结构中 len 属性记录了字符串的长度,所以我们获取一个字符串长度直接取 len 的值,复杂度是 O(1)。
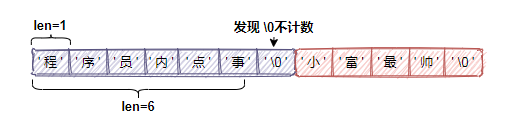
而如果用 C 字符串,在获取一个字符串长度时,需对整个字符串进行遍历,直至遍历到空格符结束(C 中遇到空格符代表一个完整字符串)。此时的复杂度是 O(N)。
在高并发场景下频繁遍历字符串,获取字符串的长度很有可能成为 Redis 的性能瓶颈,所以 SDS 性能更好一些。
数据溢出
上边提到 C 字符串是不记录自身长度的,相邻的两个字符串存储的方式为字符串分配了合适的内存空间。
如下图所示:

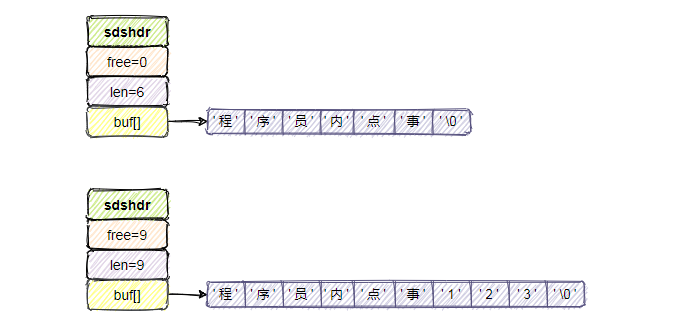
如果此时我想把“程序员内点事”改成“程序员内点事123”,可之前分配的内存只有 6 个字节,修改后的字符串需要 9 个字节才能放下啊,怎么搞?

没办法只能侵占相邻字符串的空间,自身数据溢出导致其他字符串的内容被修改。
而 SDS 很好的规避了这点:当我们需要修改数据时,首先会检查当前 SDS 空间 len 是否满足,不满足则自动扩容空间至修改所需的大小,然后再执行修改。
如下图所示:

不过有个特殊的地方,在把“程序员内点事”的 6 个字节扩容到“程序员内点事123” 9 个字节后,发现 free 属性的值变成了扩容后字符串的总长度。这就涉及到下边要说的内存重分配策略了。
内存重分配策略
C 字符串长度是一定的,所以每次在增长或者缩短字符串时,都要做内存的重分配。而内存重分配算法通常又是一个比较耗时的操作,如果程序不经常修改字符串还是可以接受的。
但很不幸,Redis 作为一个数据库,数据肯定会被频繁修改。如果每次修改都要执行一次内存重分配,那么就会严重影响性能。
SDS 通过两种内存重分配策略,很好的解决了字符串在增长和缩短时的内存分配问题。
1. 空间预分配
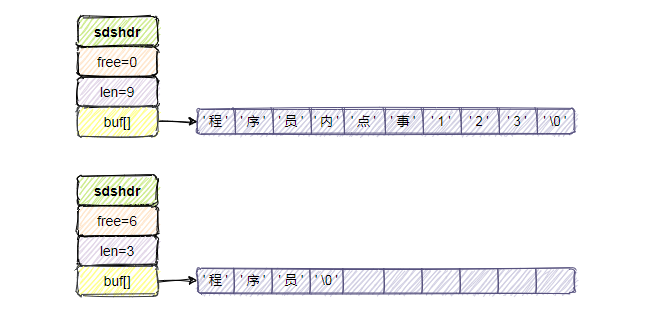
空间预分配策略用于优化 SDS 字符串增长操作,当修改字符串并需对SDS的空间进行扩展时,不仅会为 SDS 分配修改所必要的空间,还会为 SDS 分配额外的未使用空间 free,下次再修改就先检查未使用空间 free 是否满足,满足则不用在扩展空间。
通过空间预分配策略,Redis 可以有效的减少字符串连续增长操作,所产生的内存重分配次数。
额外分配未使用空间 free 的规则:
如果对 SDS 字符串修改后,len 值小于 1M,那么此时额外分配未使用空间 free 的大小与 len 相等。 如果对 SDS 字符串修改后,len 值大于等于 1M,那么此时额外分配未使用空间 free 的大小为1M。
2. 惰性空间释放
惰性空间释放策略则用于优化 SDS 字符串缩短操作。当缩短 SDS 字符串后,并不会立即执行内存重分配来回收多余的空间,而是用 free 属性将这些空间记录下来。如果后续有增长操作,则可直接使用。
数据格式多样性
C 字符串中的字符必须符合某些特定的编码格式。而且上边我们也提到,C 字符串以 \0 空字符结尾标识一个字符串结束。所以,字符串里边是不能包含 \0 的,不然就会被误认是多个。
由于这种限制,使得 C 字符串只能保存文本数据,像音视频、图片等二进制格式的数据是无法存储的。
Redis 会以处理二进制的方式操作 Buf 数组中的数据,所以对存入其中的数据未做任何的限制、过滤。只要存进来什么样,取出来还是什么样。
总结
上边只是 Redis 数据结构的一点基础知识,没什么难度。但以我的面试经验,如果被问这类问题,不要只含糊其辞的说出底层是 SDS,有理有据的把为什么这样实现也说出来。
一来可以显得自己基本功扎实,如果表达的在条理清晰,是个很不错的加分项。再一个主动打消面试官问下去的念头,当然就怕不按套路出牌的人!
— 【 THE END 】— 本公众号全部博文已整理成一个目录,请在公众号里回复「m」获取! 最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“在看”,关注公众号并回复 PDF 领取,更多内容陆续奉上。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)