Linux 系统故障排查,怕了怕了!
可以说现在 90% 的服务器都是 Linux 系统,从昨天的推文《没想到,日志还能这么分析!》留言区,可以看到大家对 Linux 很重视,学习的热情非常高,毕竟这是我们「吃饭」的家伙呀。
我自己工作中每天也是和 Linux 系统打交道,在 Linux 系统写代码、跑程序,但事情并不是那么单一。
因为服务器并不是每天都是安稳地运行的,总会遇到一些乱奇奇怪怪的问题,这时候就需要掌握排查 Linux 系统的命令,排查方向有很多维度。
比如 CPU、内存、存储、网络等等,这每一个维度,都涉及非常多的命令和工具。
问题是,一开始怎么知道这些命令呢?
我一开始学 Linux 命令是看《鸟哥的 Linux 私房菜》,把常用的 Linux 命令学了一遍,但是当我面对 Linux 系统故障或优化的时候,确发现依然无从下手,因为我没有一个「连贯」的 Linux 系统排查思维,也没有一个「上帝视角」的知识体系。
想彻底解决就要全面了解程序设计、算法分析、编程语言、系统、存储、网络等知识,但能做到的人少之又少,比如,这些场景你一定经历过:
流量高峰期,服务器 CPU 使用率过高报警,是系统 CPU 资源太少,还是程序并发部分写的有问题?
系统并没有跑吃内存的程序,但敲完 free 命令后,却发现没有内存了,到底是什么占了内存?
一大早就收到 Zabbix 告警,发现某台存放监控数据的数据库主机 CPU 的 I/O Wait 较高,怎么处理?
大多数时候,我们只能看到「症状」,不知道从哪儿下手排查和解决。因为 Linux 性能优化是个系统工程,除了要掌握基础知识,还有 2 点特别重要:
尝试大量 Linux 性能工具,学习性能优化的思路和方法;
不断实践总结,将性能问题和系统原理关联起来,特别是将应用程序、库函数、系统调用、内核和硬件等不同的层级连接起来;
我认为,学习要会抓重点——只要了解少数几个系统组件的基本原理和协作方式,掌握基本的性能指标和工具,以及性能优化的常用技巧,就可以准确分析和优化大多数性能问题了。在这个认知和基础上,再阅读那些经典书籍,才能事半功倍。
这里,分享给你一张思维导图,涵盖了大部分性能问题,可以帮你对系统性能建立个全面的认识。
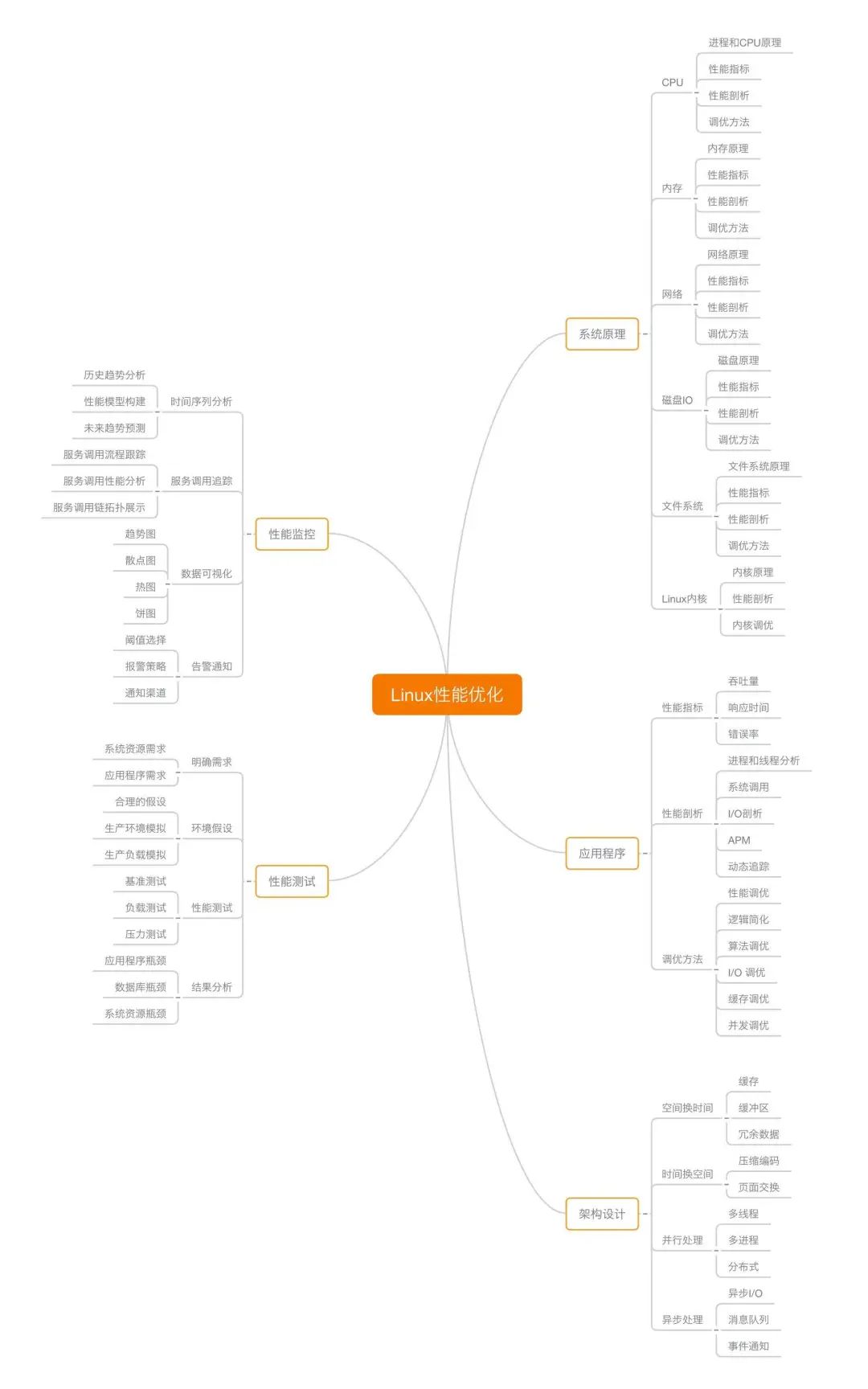
这张图谱出自倪朋飞,他是微软 Azure 资深工程师,主要负责开源容器编排系统 Kubernetes 在 Azure 的落地实践。他一直致力于云计算领域,有 10 年相关工作经验,之前曾任职于盛大云和腾讯。
去年,「追」完了他的专栏《Linux 性能优化实战》,刚订阅那会儿说是有 42 讲,结果超出预期地写了 60 讲。在专栏中,他系统讲解了 Linux 性能的基本指标、工具,以及相应的观测、分析和调优方法,用实际案例贯穿了从应用程序到操作系统的各个组件。
32,000 订阅了,口碑也非常好,截了些评价供你参考: