
中科大倪茹:感谢开源,我从入门竞赛到Top 10的经验分享
个人介绍
给大家介绍下自己吧,个人信息、个人社交(github、知乎、csdn)地址、个人经历、竞赛经历
大家好鸭,我叫倪茹,是中国科学技术大学控制工程专业研二学生,Coggle小组成员,研究方向是人工智能。
|
|


因为研一的理论知识的学习,今年三月份才开始接触的算法比赛。我是通过天池和Datawhale联合举办的学习赛二手车交易价格预测入门比赛的,一路上摸爬滚打也算是有了点小成绩。在这里感谢天池和Datawhale给我这么好的机会去提升自己。
博客 & Github:
https://blog.csdn.net/weixin_45966291
https://github.com/poplar1hhh
天池ID是poplar只是来看看,以后我也会继续分享我的比赛经验,也希望大家多多关注,多多讨论。
这是我的参赛记录:
零基础入门数据挖掘 - 二手车交易价格预测(9/8387) 第二届翼支付杯大数据建模大赛-信用风险用户识别(3/1290) 第四届工业大数据创新竞赛——水电站入库流量预测:初赛rank4,决赛受邀特殊思路分享 零基础入门金融风控-贷款违约预测(8/3634)
学习过程
学习过程:知识点的学习过程、对什么方便比较熟悉?
从大四毕业设计的时候,我开始真正接触人工智能这个方向。我的毕设题目是城市短时交通流量的预测,当时拿到选题也是一头雾水,于是我开始查资料,了解的大部分是基于神经网络做的这方面应用。
我开始查阅大量的论文,了解了机器学习,同时也了解了这个行业的发展。我为之震惊,我无法想象以前的很多难以解决的问题居然大部分可以用这种方式去解决。
研一开始的时候,我开始跟着课堂老师的教学学习机器学习、深度学习相关内容。那个时候我所在的实验室有个交通知识图谱的项目,主要做的是交通拥堵成因推理,我还记得那段夜以继日的研究生活,师兄师姐带着我们用各种算法去做实验,分析结果,最终选择了Aproi算法去完成整个项目。
在这期间我学到了很多常用的机器学习方法,同时也提高了自己代码实操的能力。很感谢实验上师兄师姐和同门对我的帮助。项目结束之后,我深知自己的机器学习知识并不构成体系,于是我开始重新回归书本,像是周志华老师的西瓜书,李航老师的统计学习方法都是会给我很大的收获,一直到现在我还依旧会学习。
研一下学期,由于疫情的关系,我开始在家学习的生活,这时除了每天的网课,我开始接触到了算法比赛,通过身边大多数同学的推荐,我开始在天池上寻找适合自己入门的比赛。
由于当时二手车交易价格预测比赛已经接近尾声,我开始学习大牛们分享的代码和思想进行学习(在这里感谢大牛们的开源代码,让我受益匪浅)。通过这一段时间的学习,我拿到了长期赛第九的成绩,这次结果让我有了打比赛的自信,同时也大大提高了我的代码能力。
后来七月份我回到实验室,当时的第二届翼支付杯大数据建模大赛正在报名,于是和实验室同学组队参加了,通过那辛苦的两个月也算是拿到了不错的成绩。期间过程真的很不容易,但是确实很值得。
翼支付杯大数据建模大赛之后,我开始打第四届工业大数据创新竞赛算法赛道的水电站入库流量预测,当时一个人打进了十名左右,用lgb的单模,然后遇到瓶颈好几天都找不到突破口。幸运的是我认识了张扬和林烨敏两位大佬,并成为了大禹治水团队的最后一名队员。大佬的指导让我收获很多,也有了新的思路。我们队在初赛的时候拿到了rank4,并在决赛时受邀参与特殊思路分享。
在水电站入库流量预测期间,我还参与了天池和Datawhale举办的学习赛:贷款违约预测,因为有了之前的比赛经验,上分的过程也是很轻松的,最终拿到了第8的成绩。
竞赛分享
竞赛分享:可以选一个知识点或者竞赛进行分享。
我印象最深刻,收获非常大的比赛是第二届翼支付杯大数据建模大赛-信用风险用户识别,下面我将进行一些经验分享,欢迎大家批评建议,具体代码和内容可以在我的GitHub和CSDN里找到。
赛题理解
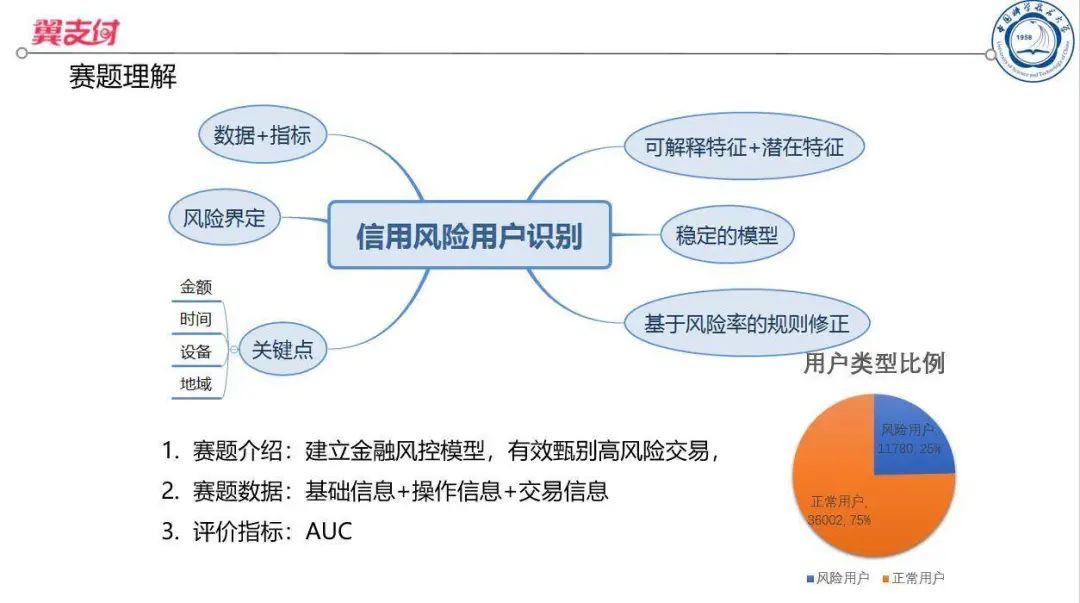
比赛提供三个数据表格,分别是用户基础信息,用户操作行为记录,用户交易行为记录。评价指标是AUC,因此我们可以不考虑该题样本不均衡对我们的模型产生的影响。因为是用户信用风险识别,所以时间,金额,地域是我们构造特征的关键。
数据预处理
缺失值处理
因为赛题的特殊性,我们不对缺失值进行常规填充,而是将其作为单独的一种特征:将类别型特征赋一个‘\N’,数字型赋-1。
# 缺失值处理
cols = ['sex', 'balance_avg', 'balance1_avg', 'provider', 'province', 'city','level']
for col in cols:
data[col].fillna(r'\N', inplace=True)
cols = ['balance_avg','balance1_avg','level']
for col in cols:
data[col].replace({r'\N': -1}, inplace=True)
data[col] = data[col]
编码处理 无序低基数类别特征(例如性别这样的):我们用Label Encoder进行编码
cols = ['sex','provider','verified','regist_type','agreement1','agreement2','agreement3','agreement4','province','city','service3']
for col in cols:
if data[col].dtype == 'object':
data[col] = data[col].astype(str)
labelEncoder_df(data, cols)
无序高基数类别特征(例如城市,省份这样的):我们用目标编码,为减小过拟合现象,采用5折交叉验证的思路,转化特征值,见下图: 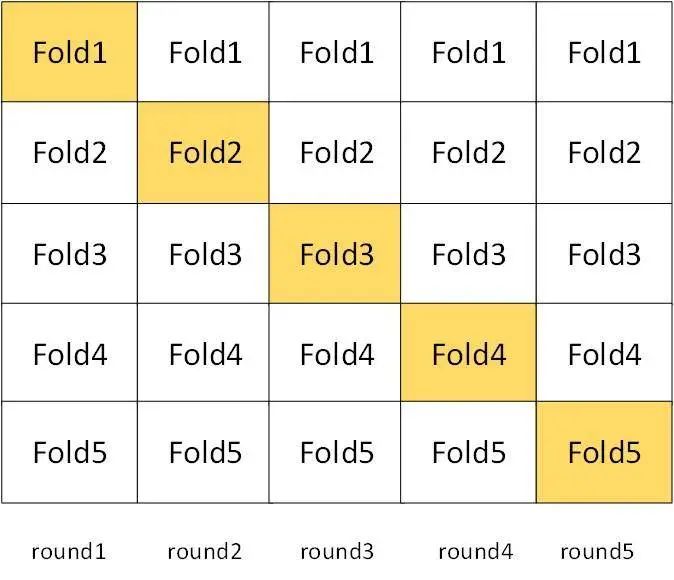
def kfold_stats_feature(train, test, feats, k):
folds = StratifiedKFold(n_splits=k, shuffle=True, random_state=44) # 这里最好与之后模型的K折交叉验证保持一致
train['fold'] = None
for fold_, (trn_idx, val_idx) in enumerate(folds.split(train, train['label'])):
train.loc[val_idx, 'fold'] = fold_
kfold_features = []
for feat in feats:
nums_columns = ['label']
for f in nums_columns:
colname = feat + '_' + f + '_kfold_mean'
kfold_features.append(colname)
train[colname] = None
for fold_, (trn_idx, val_idx) in enumerate(folds.split(train, train['label'])):
tmp_trn = train.iloc[trn_idx]
order_label = tmp_trn.groupby([feat])[f].mean()
tmp = train.loc[train.fold == fold_, [feat]]
train.loc[train.fold == fold_, colname] = tmp[feat].map(order_label)
# fillna
global_mean = train[f].mean()
train.loc[train.fold == fold_, colname] = train.loc[train.fold == fold_, colname].fillna(global_mean)
train[colname] = train[colname].astype(float)
for f in nums_columns:
colname = feat + '_' + f + '_kfold_mean'
test[colname] = None
order_label = train.groupby([feat])[f].mean()
test[colname] = test[feat].map(order_label)
# fillna
global_mean = train[f].mean()
test[colname] = test[colname].fillna(global_mean)
test[colname] = test[colname].astype(float)
del train['fold']
return train, test
等级和连续型:转为整型数值
# 转等级和连续型
cols_int = [f for f in data.columns if
f in ['level', 'balance', 'balance_avg', 'balance1', 'balance1_avg', 'balance2', 'balance2_avg',
'product1_amount', 'product2_amount', 'product3_amount', 'product4_amount', 'product5_amount',
'product6_amount']]
for col in cols_int:
for i in range(0, 50):
data.loc[data[col] == "category %d" % i, col] = i
data.loc[data[col] == "level %d" % i, col] = i
data[col].isnull().sum()
data[col].astype(int)
特征工程
时间特征分析
对比train和test的每日操作量和每日交易量的时间分布,可以假定训起始时间点相同。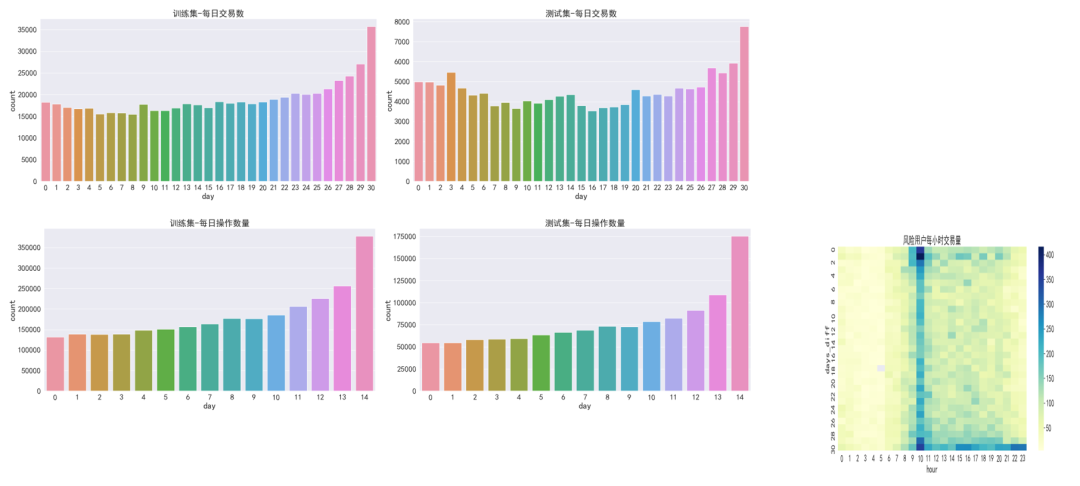
再根据正负样本的每小时交易量分布差异,我们可以放心大胆的构造窗口时间特征。
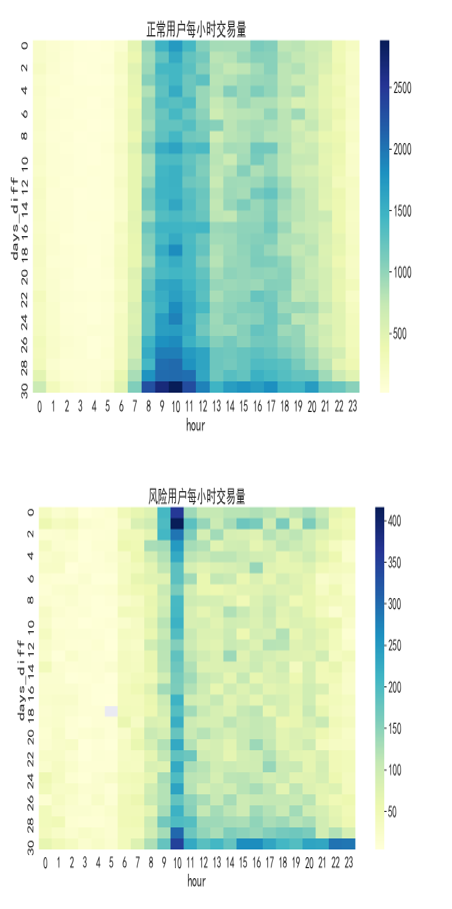
例如:用户在星期n的交易金额的统计特征,用户在交易n天之后的交易金额的统计特征,用户在每天n点之后的交易金额的统计特征:
def gen_user_window_amount_features(df, window):
group_df = df[df['days_diff']>window].groupby('user')['amount'].agg({
'user_amount_mean_{}d'.format(window): 'mean',
'user_amount_std_{}d'.format(window): 'std',
'user_amount_max_{}d'.format(window): 'max',
'user_amount_min_{}d'.format(window): 'min',
'user_amount_sum_{}d'.format(window): 'sum',
'user_amount_med_{}d'.format(window): 'median',
'user_amount_cnt_{}d'.format(window): 'count',
}).reset_index()
return group_df
def gen_user_window_amount_hour_features(df, window):
group_df = df[df['hour']>window].groupby('user')['amount'].agg({
'user_amount_mean_{}h'.format(window): 'mean',
'user_amount_std_{}h'.format(window): 'std',
'user_amount_max_{}h'.format(window): 'max',
'user_amount_min_{}h'.format(window): 'min',
'user_amount_sum_{}h'.format(window): 'sum',
'user_amount_med_{}h'.format(window): 'median',
'user_amount_cnt_{}h'.format(window): 'count',
}).reset_index()
return group_df
def gen_user_window_amount_week_features(df, window):
group_df = df[df['week']==window].groupby('user')['amount'].agg({
'user_amount_mean_{}w'.format(window): 'mean',
'user_amount_std_{}w'.format(window): 'std',
'user_amount_max_{}w'.format(window):'max',
'user_amount_min_{}w'.format(window): 'min',
'user_amount_sum_{}w'.format(window):'sum',
'user_amount_med_{}w'.format(window):'median',
'user_amount_cnt_{}w'.format(window):'count',
}).reset_index()
return group_df
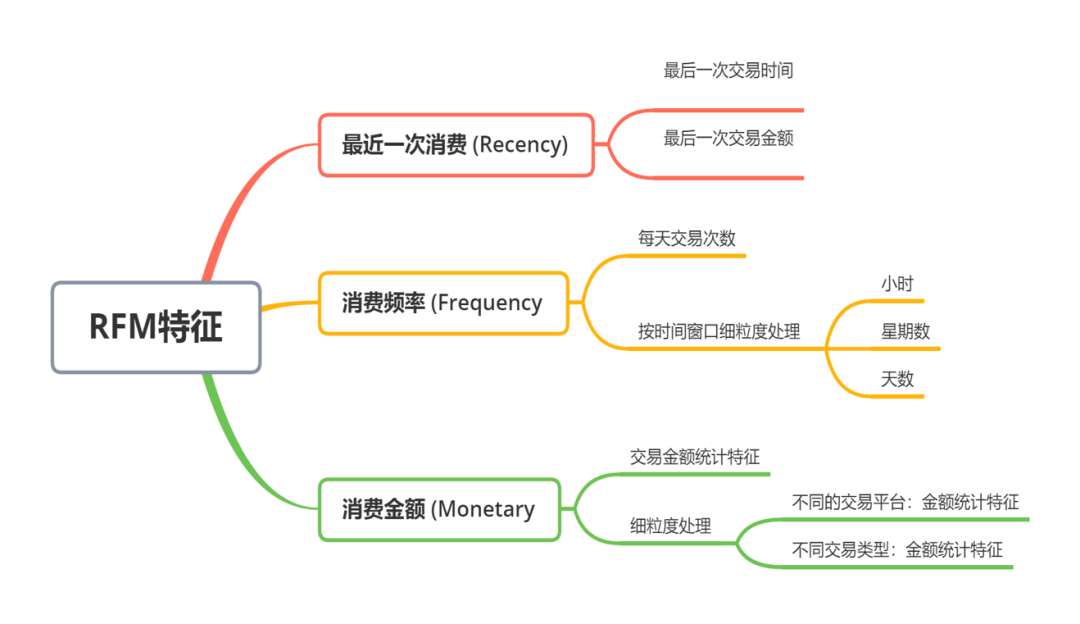
RFM特征
通过调查资料,我们了解了RFM模型,他是衡量客户价值和客户创利能力的重要工具和手段。通过这个信息我们构造出了很多有用特征。具体见下图:
TF-IDF特征
我们对操作模式和操作类型进行提取TF-IDF特征。
def gen_user_tfidf_features(df, value):
df[value] = df[value].astype(str)
df[value].fillna('-1', inplace=True)
group_df = df.groupby(['user']).apply(lambda x: x[value].tolist()).reset_index()#把每个用户的op_mode转成列表
group_df.columns = ['user', 'list']
group_df['list'] = group_df['list'].apply(lambda x: ','.join(x))#将op_mode用,连接
enc_vec = TfidfVectorizer()#得到tf-idf矩阵
tfidf_vec = enc_vec.fit_transform(group_df['list'])#得到词频矩阵,将op_mode转为词向量,即计算机能识别的编码
svd_enc = TruncatedSVD(n_components=10, n_iter=20, random_state=2020)#降维,提取op_mode的特征,TtuncatedSVD和SVD:TSVD可以选择需要提取的维度
vec_svd = svd_enc.fit_transform(tfidf_vec)
vec_svd = pd.DataFrame(vec_svd)
vec_svd.columns = ['svd_tfidf_{}_{}'.format(value, i) for i in range(10)]
group_df = pd.concat([group_df, vec_svd], axis=1)
del group_df['list']
return group_df
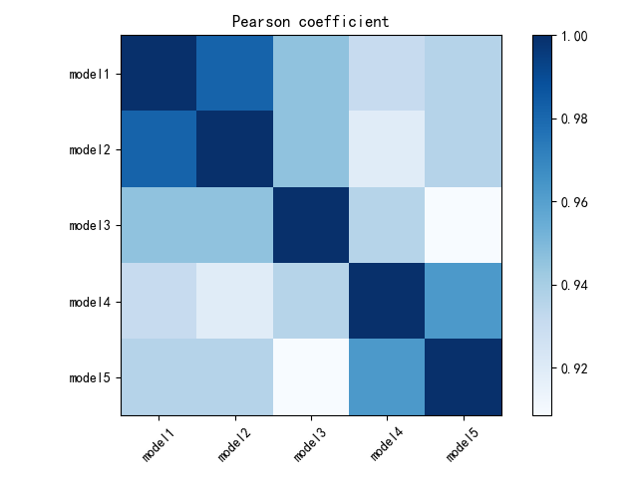
模型融合
我们采用了三个模型:LightGBM,Xgboost,Catboost多个参数进行模型融合。具体模型相关性分析见下图: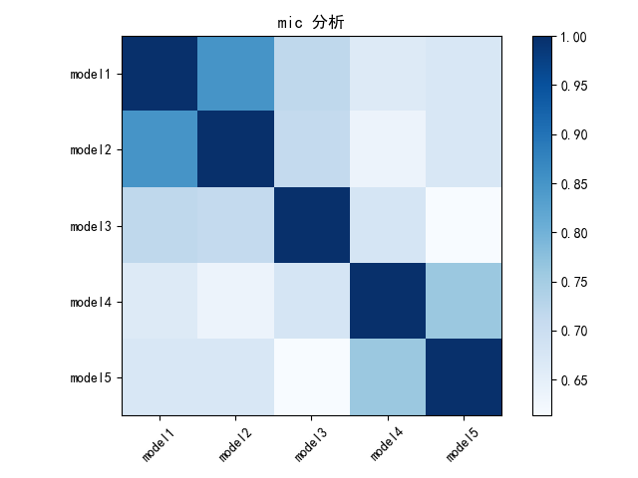
lgb单模:
def lgb_model(train, target, test, k):
feats = [f for f in train.columns if f not in ['user', 'label']]
print('Current num of features:', len(feats))
oof_probs = np.zeros(train.shape[0])
output_preds = 0
offline_score = []
feature_importance_df = pd.DataFrame()
parameters = {
'learning_rate': 0.01,
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'num_leaves': 68,
'feature_fraction': 0.4,
'bagging_fraction': 0.8,
'min_data_in_leaf': 25,
'verbose': -1,
'nthread': 8,
'max_depth':8
}
seeds = [2020]
for seed in seeds:
folds = StratifiedKFold(n_splits=k, shuffle=True, random_state=seed)
for i, (train_index, test_index) in enumerate(folds.split(train, target)):
train_y, test_y = target[train_index], target[test_index]
train_X, test_X = train[feats].iloc[train_index, :], train[feats].iloc[test_index, :]
dtrain = lgb.Dataset(train_X,
label=train_y)
dval = lgb.Dataset(test_X,
label=test_y)
lgb_model = lgb.train(
parameters,
dtrain,
num_boost_round=5000,
valid_sets=[dval],
early_stopping_rounds=200,
verbose_eval=100,
)
oof_probs[test_index] = lgb_model.predict(test_X[feats], num_iteration=lgb_model.best_iteration)/len(seeds)
offline_score.append(lgb_model.best_score['valid_0']['auc'])
output_preds += lgb_model.predict(test[feats], num_iteration=lgb_model.best_iteration)/folds.n_splits/len(seeds)
print(offline_score)
# feature importance
fold_importance_df = pd.DataFrame()
fold_importance_df["feature"] = feats
fold_importance_df["importance"] = lgb_model.feature_importance(importance_type='gain')
fold_importance_df["fold"] = i + 1
feature_importance_df = pd.concat([feature_importance_df, fold_importance_df], axis=0)
print('OOF-MEAN-AUC:%.6f, OOF-STD-AUC:%.6f' % (np.mean(offline_score), np.std(offline_score)))
print('feature importance:')
print(feature_importance_df.groupby(['feature'])['importance'].mean().sort_values(ascending=False).head(310))
feature_importance_df.groupby(['feature'])['importance'].mean().sort_values(ascending=False).head(457).to_csv('../importance/08_26_452.csv')
return output_preds, oof_probs, np.mean(offline_score)
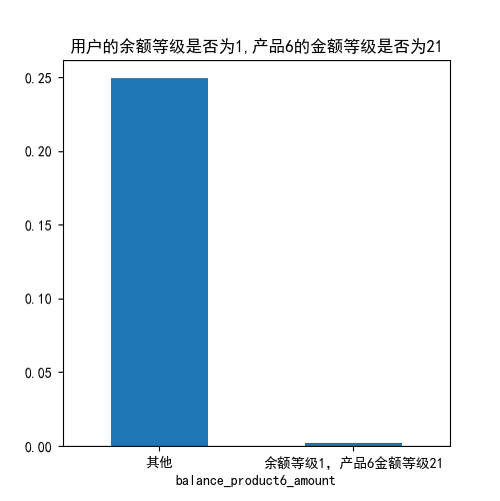
规则上分
通过分析,我们发现当用户的余额等级为1,产品金额等级为21时,用户风险率极大,我们将其结果置为原来的1/2。
总结
“为沉迷学习点赞↓