
MySQL:互联网公司常用分库分表方案汇总!
点击关注上方“杰哥的IT之旅”,

一、数据库瓶颈
1、IO瓶颈
2、CPU瓶颈
二、分库分表
1、水平分库
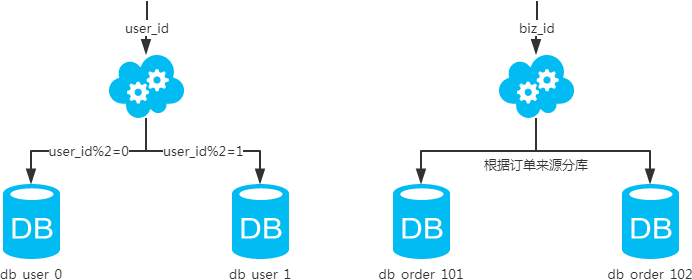
每个库的结构都一样; 每个库的数据都不一样,没有交集; 所有库的并集是全量数据;
2、水平分表
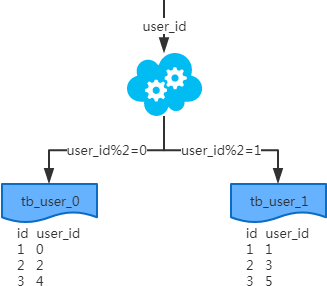
每个表的结构都一样; 每个表的数据都不一样,没有交集; 所有表的并集是全量数据;
3、垂直分库
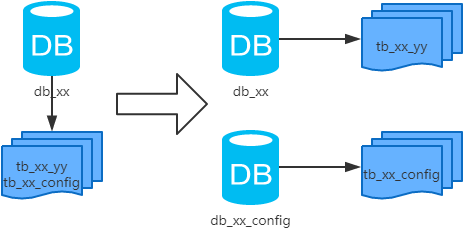
每个库的结构都不一样; 每个库的数据也不一样,没有交集; 所有库的并集是全量数据;
4、垂直分表
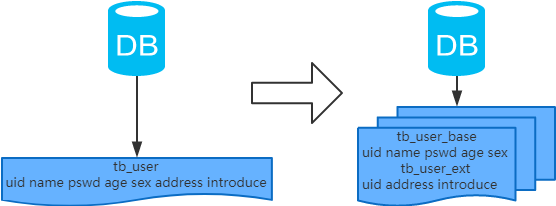
每个表的结构都不一样; 每个表的数据也不一样,一般来说,每个表的字段至少有一列交集,一般是主键,用于关联数据; 所有表的并集是全量数据;
三、分库分表工具
sharding-sphere:jar,前身是sharding-jdbc; TDDL:jar,Taobao Distribute Data Layer; Mycat:中间件。
注:工具的利弊,请自行调研,官网和社区优先。
四、分库分表步骤
1、非partition key的查询问题
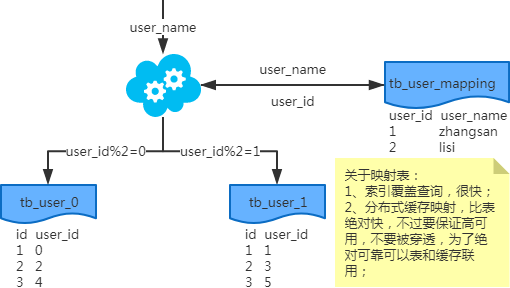
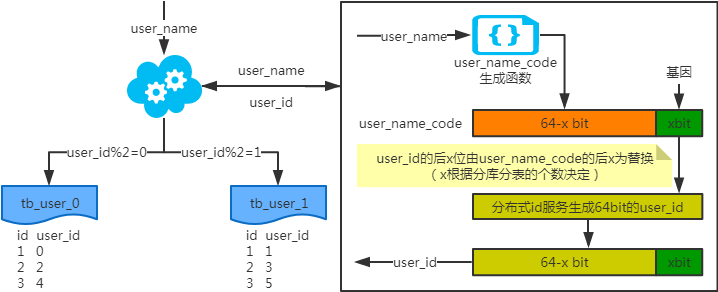
注:写入时,基因法生成user_id,如图。关于xbit基因,例如要分8张表,23=8,故x取3,即3bit基因。根据user_id查询时可直接取模路由到对应的分库或分表。 根据user_name查询时,先通过user_name_code生成函数生成user_name_code再对其取模路由到对应的分库或分表。id生成常用snowflake算法。
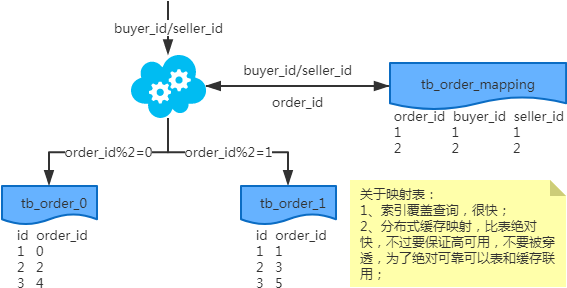
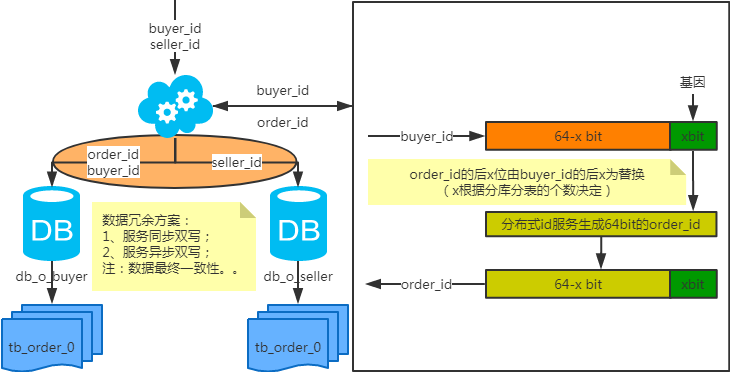
注:按照order_id或buyer_id查询时路由到db_o_buyer库中,按照seller_id查询时路由到db_o_seller库中。感觉有点本末倒置!有其他好的办法吗?改变技术栈呢?
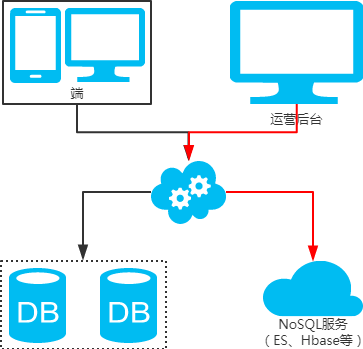
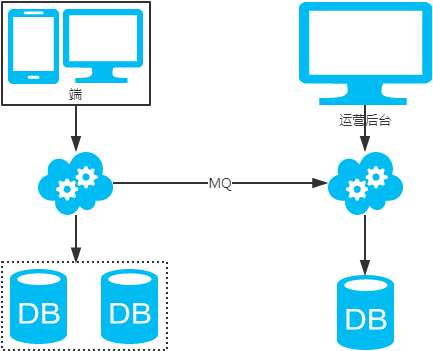
2、非partition key跨库跨表分页查询问题
注:用NoSQL法解决(ES等)。
3、扩容问题
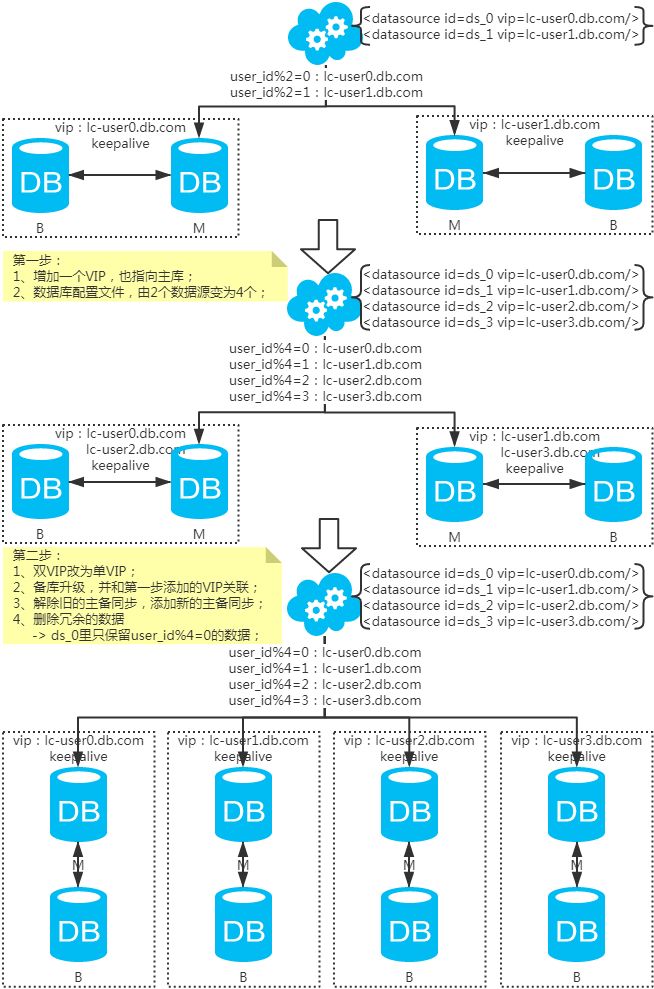
注:扩容是成倍的。
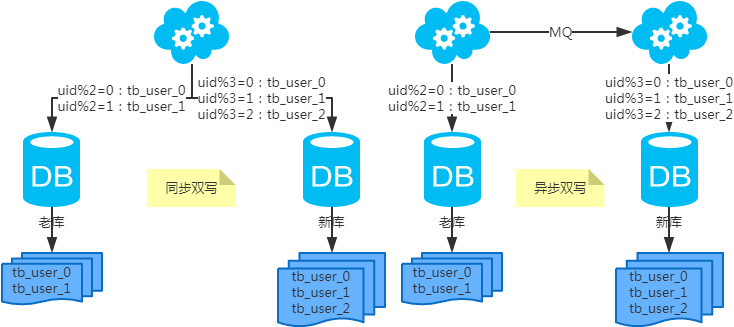
第一步:(同步双写)修改应用配置和代码,加上双写,部署; 第二步:(同步双写)将老库中的老数据复制到新库中; 第三步:(同步双写)以老库为准校对新库中的老数据; 第四步:(同步双写)修改应用配置和代码,去掉双写,部署;
注:双写是通用方案。
六、分库分表总结
分库分表,首先得知道瓶颈在哪里,然后才能合理地拆分(分库还是分表?水平还是垂直?分几个?)。且不可为了分库分表而拆分。 选key很重要,既要考虑到拆分均匀,也要考虑到非partition key的查询。 只要能满足需求,拆分规则越简单越好。
七、分库分表示例
示例GitHub地址:https://github.com/littlecharacter4s/study-sharding
本文由“壹伴编辑器”提供技术支持
- End - 本公众号全部博文已整理成一个目录,请在公众号后台回复「 m」获取!推荐阅读: 1、学生党学编程,有这个开源项目就够了!
2、太赞了!程序员应该访问的最佳网站都在这里了!
3、再见,Navicat!
4、一款基于 Python 语言的 Linux 资源监视器!
5、900 多道 LeetCode 题解,这个 GitHub 项目值得 Star!
6、SSH 只能用于远程 Linux 主机?那说明你见识太小了!好文和朋友一起看~
评论