点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达
ResNet 发布至今已经有六年多了,但它的工作原理至今仍然是个迷。最近Reddit 上一个网友发帖表示,是否ResNet的创新出发点就有问题?
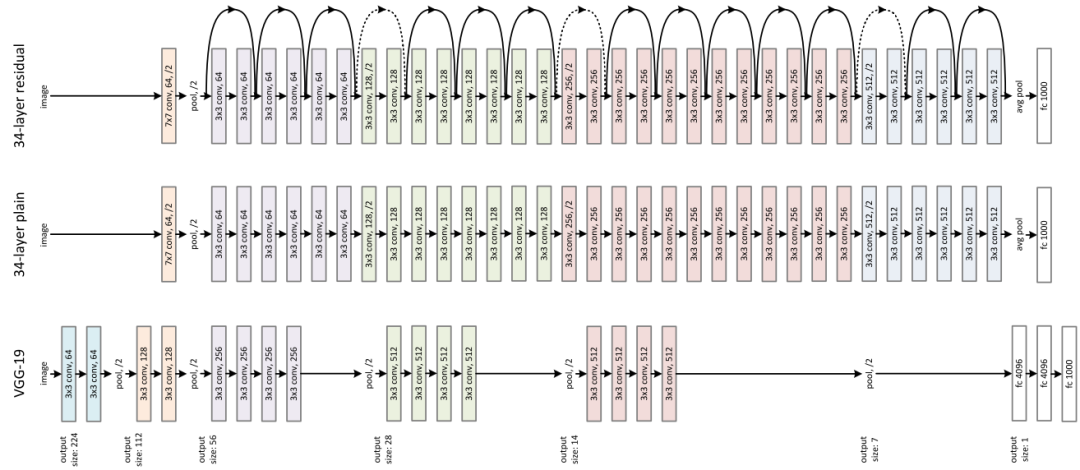
2015年,一个里程碑的神经网络模型ResNet发布。因为在过深的网络训练会产生梯度消失和梯度爆炸,并且训练过深的网络中会出现准确率下降的问题,而RestNet 采用残差连接很容易让研究人员训练出上百层甚至上千层的网络。在ResNet论文观察到的退化问题(degradation problem),即34层的网络在整个训练过程中比18层的网络具有更高的训练误差,但18层网络的解空间显然是34层网络的子空间。一个很自然的假设是这个问题和RNN 网络中观察到的梯度消失问题(Vanishing Gradient Problem)相同,也是长短时记忆网络(Long-Short Term Memory Networks, LSTM)主要改进的问题。但论文的作者Kaiming 大神当时并不这么认为,他在论文中写道「我们认为这种优化困难不太可能是由梯度消失引起的,因为这些普通神经网络使用 BN 进行训练,确保前向传播的信号具有非零方差可以缓解这个问题。我们还验证了反向传播的梯度,结果可以看到表现出 BN 的结果也很正常。因此,前向或后向的信号都不会消失。事实上,34 层的普通网络仍然能够达到有竞争力的精度,这表明这个解决方法在一定程度上是有效的。我们推测普通神经网络的收敛速度可能呈指数级低,这会影响训练误差的减少。未来将研究这种优化困难的原因。」这个论点也被网友称为「ResNet 假说」,而关于ResNet 假说的正确性最近又在Reddit 上引起了热议。提问者认为,最近的许多论文和教程似乎都假设 ResNet 假设是错误的,论文的作者大多添加了跳跃连接以「改进梯度传播流」,并引用了原始的 ResNet 论文来支持这一主张。虽然添加跳跃连接会改善梯度流是很有道理的,但首先是什么导致了退化问题依然没有答案。跳过连接通过改进梯度流来解决退化问题的想法似乎与 ResNet 假设明显矛盾;那么这个想法是从哪里来的呢?ResNet 假说是否被证伪了?有网友从技术角度认为并没有完整的分析,关于 ResNets 的工作原理主要存在三种相互竞争的假说,并且给出了相关的论文:1、进行了迭代细化(iterative refinement)这篇论文从分析和实证两方面研究了resnet。研究人员通过显示残差连接自然地鼓励残差块的特征在从一个块到下一个块的过程中沿着损失的负梯度移动,从而在resnet中形式化了迭代细化的概念。此外,实证分析表明,resnet能够进行表征学习和迭代优化。通常,Resnet块倾向于将表示学习行为集中在前几层,而更高层执行特征的迭代细化。最后,研究人员观察到共享残差层会导致表示爆炸和反直觉的过拟合,文中提出了一个简单的策略可以帮助缓解这个问题。这项工作中对残差网络提出了一种新颖的解释:这个模型可以被视为许多不同长度路径的模型的集成。此外,残差网络似乎通过在训练期间仅利用短路径来实现非常深的网络。为了支持这一观察,研究人员将残差网络重写为一个显式的路径集合。研究结果表明,这些路径表现出类似整体的行为并不强烈地相互依赖。并且大多数路径都比人们预期的要短,在训练期间也只需要短路径,因为较长的路径不会产生任何梯度。例如,具有 110 层的残差网络中的大部分梯度来自仅 10-34 层深的路径。这篇论文的结果认为Resnet 能够训练非常深的网络的关键特征之一是残差网络通过引入可以在非常深的网络范围内携带梯度的短路径来避免梯度消失问题。答主也看过一些神经切线内核(neural tangent kernel stuff)的东西,但他仍然不明白其中的原理,并且他也认为没有人真正坐下来试图弄清楚真正的解释是什么。不过他有一个想法,可以通过考虑具有重叠跳过连接(overlapping skip connections)的网络来测试集成理论(ensemble theory),这些网络具有集成论文中定义的最大多样性(maximal multiplicity)。并且可以改变跳过连接长度的同时保持多重性不变,但还没有人这样做过任何与此有关的实验。还可以尝试的另一件事是使 Resnets 的梯度流保证完美而无需跳过连接的情况,但是当用户添加残差连接时,大多数此类事情都无法达到完美的情况,因此必须考虑新的方式来达成完美梯度传播。另一个高赞网友表示,捷径连接(shortcut connections)改善了损失情况,能够使优化变得更加容易,有很多研究结果都支持这一点。The Shattered Gradients Problem: If resnets are the answer, then what is the question? (ICML 2017) 表明 ResNet 具有更稳定的梯度。Visualizing the Loss Landscape of Neural Nets (NeurIPS 2018) 再次表明 ResNets 具有更平滑的损失表面。并且也有研究表示,可以不需要捷径来学习有效的表示,但优化会更难。例如,Fixup Initialization: Residual Learning without Normalization (ICLR 2019) 表明,如果你对初始化结果进行多次调整,那你可以在没有残差连接的情况下训练 ResNets 以获得不错的结果。RepVGG:Making VGG-style ConvNets Great Again (CVPR 2021) 表明可以在训练后移除捷径并仍然拥有性能不错的网络。但这仍然符合 ResNet 的原始想法:将每个块初始化为一个identify function,因此最初看起来好像参数实际上并不存在,也对网络训练没有产生任何影响,然后逐渐让块的效果发挥作用。也有网友认为标题的用词实在不准确,因为debunked 相当于直接给Resnet判定为错误,提问者也表示自己确实是标题党了,但标题无法更改了。参考资料:
https://www.reddit.com/r/MachineLearning/comments/px3hzd/d_has_the_resnet_hypothesis_been_debunked/