
高手过招, 为什么 Redis Cluster 是16384个槽位?
我们都知道Redis的集群有三种方案:
1、主从复制模式 2、Sentinel(哨兵)模式 3、Redis Cluster模式
当然使用随着海量数据的存储要求,单台Redis配置有限,已经满足不了我们的需求。我们考虑采用分布式集群方案。
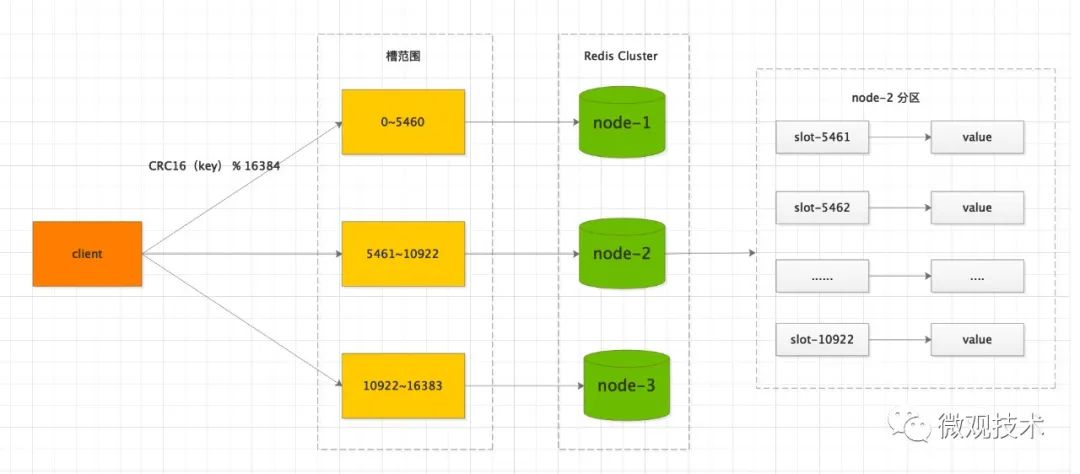
Redis Cluster 采用数据分片机制,定义了 16384个 Slot槽位,集群中的每个Redis 实例负责维护一部分槽以及槽所映射的键值数据。
客户端可以连接集群中任意一个Redis 实例,发送读写命令,如果当前Redis 实例收到不是自己负责的Slot的请求时,会将该slot所在的正确的Redis 实例地址返回给客户端。
客户端收到后,自动将原请求重新发到这个新地址,自动操作,外部透明。

★是不是有点似曾相识的感觉,HTTP 协议也有重定向功能。玩法跟这个差不多。HTTP 响应头有一个
”Location字段,当状态码是301或者302时,客户端会自动读取Location中的新地址,自动重定向发送请求。
Redis key的路由计算公式:slot = CRC16(key) % 16384
添加、删除或者修改某一个节点,都不会造成集群不可用的状态。使用哈希槽的好处就在于可以方便的添加或移除节点。
当需要增加节点时,只需要把其他节点的某些哈希槽挪到新节点;当需要移除节点时,只需要把移除节点上的哈希槽挪到其他节点。
CRC16的算法原理:
根据CRC16的标准选择初值CRCIn的值 将数据的第一个字节与CRCIn高8位异或 判断最高位,若该位为 0 左移一位,若为 1 左移一位再与多项式Hex码异或 重复3直至8位全部移位计算结束。 重复将所有输入数据操作完成以上步骤,所得16位数即16位CRC校验码。
CRC16 算法最大值
CRC16 算法,产生的hash值有 16 bit 位,可以产生 65536(2^16)个值 ,也就是说值分布在 0 ~ 65535 之间
这时候,疑问来了,槽位总数为什么是 16384 ?65536 不可以吗?

这个问题,Redis 官方 Issues 也有朋友提出来过
地址:
https://github.com/redis/redis/issues/2576

antirez 大神对这个问题做了回复,简单归纳起来,有以下原因:
正常的心跳数据包携带节点的完整配置,它能以幂等方式来更新配置。如果采用 16384 个插槽,占空间 2KB (16384/8);如果采用 65536 个插槽,占空间 8KB (65536/8)。
Redis Cluster 不太可能扩展到超过 1000 个主节点,太多可能导致网络拥堵。
16384 个插槽范围比较合适,当集群扩展到1000个节点时,也能确保每个master节点有足够的插槽,
8KB 的心跳包看似不大,但是这个是心跳包每秒都要将本节点的信息同步给集群其他节点。比起 16384 个插槽,头大小增加了4倍,ping消息的消息头太大了,浪费带宽。
Redis主节点的哈希槽配置信息是通过 bitmap 来保存的

传输过程中,会对bitmap进行压缩,bitmap的填充率越低,压缩率越高。
bitmap 填充率 = slots / N (N表示节点数),
所以,插槽数偏低的话, 填充率会降低,压缩率会升高。
综合下来,从心跳包的大小、网络带宽、心跳并发、压缩率等维度考虑,16384 个插槽更有优势且能满足业务需求。
★万事万物,都是相互制衡的,”大“ 不一定是最好的,合适最重要。”
接下来,我们看下master节点间心跳数据包格式:
消息格式分为:消息头和消息体。消息头包含发送节点自身状态数据,接收节点根据消息头就可以获取到发送节点的相关数据,
代码位置:
/usr/src/redis/redis-5.0.7/src/cluster.h
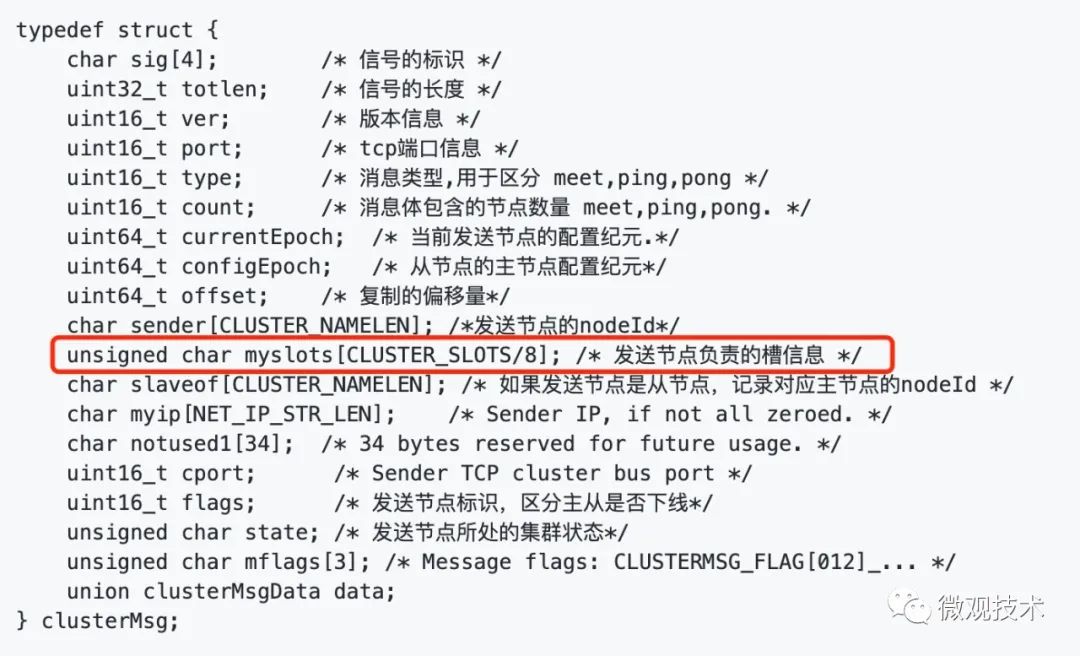
其中,消息头有一个myslots的char类型数组,unsigned char myslots[CLUSTER_SLOTS/8];,数组长度为 16384/8 = 2048 。底层存储其实是一个bitmap,每一个位代表一个槽,如果该位为1,表示这个槽是属于这个节点。
消息体中,会携带一定数量的其他节点信息用于交换,约为集群总节点数量的1/10,节点数量越多,消息体内容越大。10个节点的消息体大小约1kb。
划重点:
细心的同学可能会有疑问,char不是占2个字节吗?数组长度为什么是 16384/8?不应该是 16384/16 吗?
因为,Redis 是 C 语言开发的,char 占用一个 字节;而 Java 语言 char 占用 两个 字节。
master节点间心跳通讯
Redis 集群采用 Gossip(流言)协议, Gossip 协议工作原理就是节点彼此不断通信交换信息,一段时间后所有的节点都会知道集群完整的信息,类似流言传播。
集群中每个节点通过一定规则挑选要通信的节点,每个节点可能知道全部节点,也可能仅知道部分节点,只要这些节点彼此可以正常通信,最终它们会达到一致的状态。当节点出现故障、新节点加入、主从角色变化、槽信息变更等事件发生时,通过不断的 ping/pong 消息通信,经过一段时间后所有的节点都会知道整个集群 全部节点的最新状态,从而达到集群状态同步的目的。
具体规则如下:
1、每秒会随机选取5个节点,找出最久没有通信的节点发送ping消息 2、每隔 100毫秒 都会扫描本地节点列表,如果发现节点最近一次接受pong消息的时间大于cluster-node-timeout/2 ,则立刻发送ping消息
因此,每秒单master节点发出ping消息数量:
总结:
1、每秒 redis节点需要发送一定数量的ping消息作为心跳包,如果槽位为 65536,这个ping消息的消息头太大了,浪费带宽。
2、业务上看,集群主节点数量基本不可能超过1000个。集群节点越多,心跳包的消息体携带的数据越多。如果节点超过1000个,会导致网络拥堵。因此redis作者,不建议redis cluster节点数量超过1000个。
3、槽位越小,节点少的情况下,压缩率更高

【另类见解】秒杀其实很简单!!

Redis缓存那点破事 | 绝杀面试官 25 问!