
中国邮政邮科院 X DorisDB:统一OLAP平台,大幅降低运维成本
邮政科学研究规划院有限公司(以下简称“邮科院”),作为中国邮政集团有限公司的科研智库单位,专注于战略规划、企业管理、工程设计、物流装备、智能终端、质量检测、标准化研究等领域,在助力中国邮政战略转型和经营发展中发挥着重要支撑作用。
邮科院数据组负责全院大数据体系架构的建设,支撑日常BI运营分析、科研数据产品、物流数据、网点画像等业务场景。邮科院数据组通过使用DorisDB,统一了实时和离线的分析场景,替换了ClickHouse、Presto、MySQL等系统,解决了原有多套系统带来的运维和使用复杂性,简化了数据ETL流程,同时大幅提升OLAP、Adhoc等场景的查询效率。本文主要介绍邮科院数据组基于新一代极速全场景MPP数据库DorisDB,在数据服务体系和数据应用场景中的实践和探索。
业务背景
随着科研数据积累越来越大,数据规模和体量也急剧膨胀。科研的原始数据通常来源于研报抽取、日志埋点文件、业务数据库、三方接口等。过去通常基于CDH/Hadoop等大数据分布式计算框架和数据集成工具,构建离线的数据仓库,并对数据进行适当的分层、建模、加工和管理,构建各类分析主题。邮科院数据体系中沉淀了诸多研报主题数据,例如:电商流量数据,物流企业财务数据,行业报告相关的数据等。
上层数据应用对查询的响应延迟和时效性要求高,会将数据通过数据同步工具同步到MySQL、ElasticSearch、Presto、HBase、ClickHouse等数据库系统中,来支撑上层数据应用的查询要求。
邮科院的大数据总体架构如下图所示,从下到上可以分为数据接入层、数据计算层、数据服务层和数据应用层。
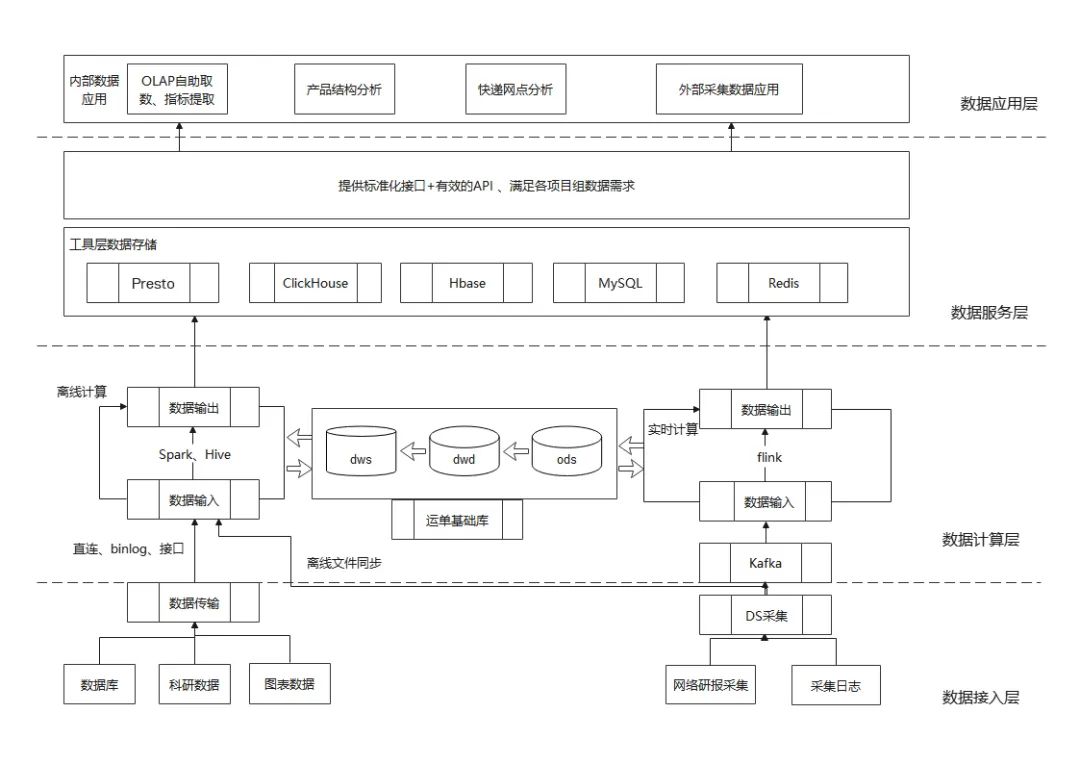
数据计算层使用科研工作各分析场景下产生的模型/方案/业务的明细数据,进行离线数据计算,对TB级别的明细数据进行调度、聚合、计算,在数仓里沉淀出大量明细表、聚合表和最终的数据报表。
数据计算层生成的各类数据表,会同步到数据服务层,由数据服务层提供接口给数据应用层使用,满足不同的数据业务需求。
业务痛点
数据服务层的愿景是开放数仓能力,建立统一的数据服务出口,针对不同的数据业务分析场景(数据规模、QPS、UDF支持、运维成本等),原有架构在底层使用了不同的查询引擎:
大数据量、低QPS:使用Hive、Presto、ClickHouse等基于Hadoop生态的离线批任务计算框架和MPP数据库来解决。
小数据量、高QPS:使用MySQL、ElasticSearch、HBase、MongoDB等关系型/非关系型数据库来解决。
使用多套查询引擎,我们遇到如下问题和挑战:
离线/实时ETL任务过多,处理逻辑大部分为简单聚合/去重,聚合表数量庞大,导致运营和运维上的成本增加;
针对中等数据量、中等QPS的查询场景,如何能兼顾数据规模的同时,有较友好的查询响应延迟;
大数据量下插入、更新的实时数据场景无法得到支持,例如:网点画像、实时数据导入、邮路路径、研报数据汇总等。
OLAP引擎选型
针对如上的问题和挑战,我们的目标是寻求尽可能少的OLAP引擎,利用在明细表上现场计算来解决ETL任务、数仓表过多问题,同时需要兼顾在数据规模、查询QPS、响应耗时、查询场景方面的权衡。
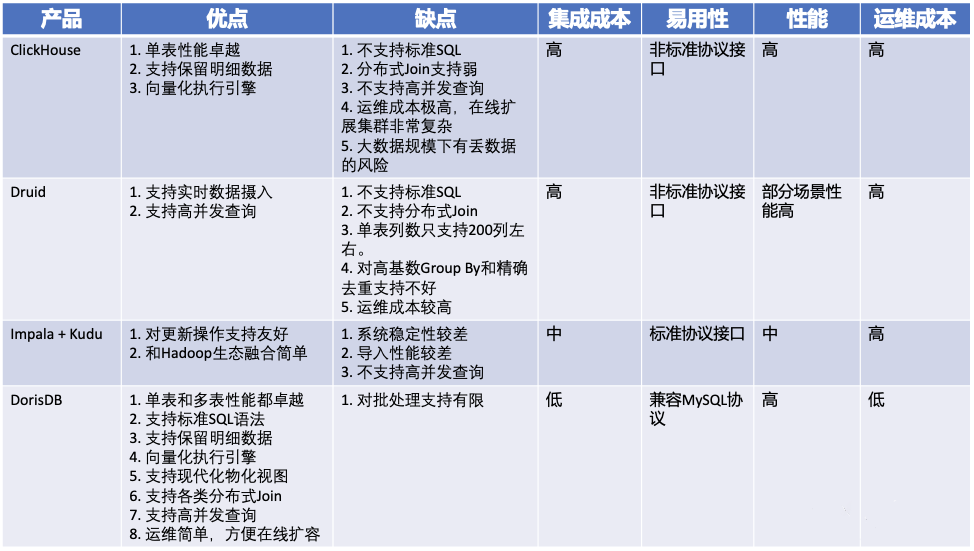
目前市面上OLAP引擎百花齐放,诸如Impala、Druid、ClickHouse、DorisDB。经过一番调研,我们最终选择了DorisDB。DorisDB是基于MPP架构的分析型数据库,自带数据存储,整合了大数据框架的优势,支持主键更新、支持现代化物化视图、支持高并发和高吞吐的即席查询等诸多优点,天然能解决我们上述的问题。
DorisDB应用实践
DorisDB已经投入生产环境,主要作为离线/实时数据的OLAP数据库使用。离线数据主要存储于HDFS中,通过DataX任务批量同步数据到DorisDB;另一部分实时数据主要存储于Kafka中,使用DorisDB的routine load功能实时将数据从kafka写入到DorisDB。
在没有引入DorisDB之前,我们使用的底层引擎是MySQL、Presto on HDFS和ClickHouse等系统,对明细表/聚合表进行查询。这几种方式都存在着不少问题:
MySQL处理上亿规模的数据,无论使用分库分表、分区表、集群化部署的PolarDB方案,都会存在慢查询、数据库扛不住、运维困难的窘境;
Presto on HDFS的方案更偏向于分析型数据业务,虽然能存储海量的数据,计算能力不错,唯一致命的在于无法满足在线业务的高吞吐QPS,查询比较难做到毫秒级。
ClickHouse对Join支持较弱,通常使用大宽表建模,不够灵活,另外运维也比较复杂。
在引入DorisDB替换MySQL、Presto和ClickHouse后,DorisDB带来的业务效果如下:
支撑了在线报表查询+数据分析业务,服务于对内运营+对外行业分析的数据产品,报表业务查询大部分耗时在毫秒级别,分析型业务查询大部分耗时在秒级别;
支持10亿规模的明细表查询,月、季、年等维度统计数据现场算聚合统计、精准去重等,查询耗时都能控制在500ms以内;
千万级别的多表的Join和union查询,经过Colocate Join特性优化,查询响应在秒级。
另外,我们还将DorisDB应用到实时数据分析场景, DorisDB在实时数据分析主要有如下优势:
实时写入性能:目前DorisDB支持HTTP方式的 Stream Load,可以自定义的分钟级别微批写入,以及Routine Load功能,可以将Kafka 的数据实时同步到DorisDB中,满足当前实时数据分析业务;
统一离线和实时分析:实时数据和离线数据更好的在DorisDB中进行融合,灵活支撑应用,数据存储策略通过DorisDB动态分区的功能进行自动管理;
SQL Online Serving:高效的SQL即席查询能力,能够兼容业界标准的SQL规范,支撑业务灵活复杂的访问,提高取数开发的效率。
总结和规划
未来,邮科院在DorisDB的应用和实践上还有不少规划:
除了unique和duplicate数据模型,未来会将符合的数据场景迁移至aggregation模型,并使用物化视图,进一步降低数仓开发维护成本,降低查询延迟;
DorisDB on ES的功能也值得我们深挖和探索,解决原生ES集群无法支持跨索引Join的能力;
更多数据应用层的场景接入DorisDB,例如网点画像服务、邮路路径分析等,将进一步拓展DorisDB在实时数据写入、批量数据更新场景中的应用;
与科研数据分析平台、数仓平台深度打通,完善数据整体架构,作为数据团队的基础设施去保障稳定性和服务;
考虑使用多云架构,自主可控的数仓架构可以灵活的在多云间切换迁移,降低单一云厂商的依赖,控制成本提高可用性。
......
最后的最后,感谢DorisDB技术团队给予的热情、靠谱的答疑解惑和技术支持!!!另外,邮科院数据组热烈欢迎对数据分析感兴趣的同学发送简历到:xiexiangcpri@chinapost.com.cn


Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点
4万字长文 | ClickHouse基础&实践&调优全视角解析
你好,我是王知无,一个大数据领域的硬核原创作者。
做过后端架构、数据中间件、数据平台&架构、算法工程化。
专注大数据领域实时动态&技术提升&个人成长&职场进阶,欢迎关注。