
Easyocr - 3行代码识别图片中的任意语言文字

今天给大家介绍一个超级简单且强大的OCR文本识别工具:easyocr.
这个模块支持70多种语言的即用型OCR,包括中文,日文,韩文和泰文等。
下面是这个模块的实战教程。
1.准备
开始之前,你要确保Python和pip已经成功安装在电脑上。
请选择以下任一种方式输入命令安装依赖:
1. Windows 环境 打开 Cmd (开始-运行-CMD)。
2. MacOS 环境 打开 Terminal (command+空格输入Terminal)。
3. 如果你用的是 VSCode编辑器 或 Pycharm,可以直接使用界面下方的Terminal.
pip install easyocr它会安装除了模型文件之外的所有依赖,模型文件则会在运行代码的时候下载。
对于Windows,如果在安装 Torch 或 Torchvision 时报错了,请按照https://pytorch.org 的官方说明安装 Torch 和 Torchvision。
如果你想使用显卡进行计算,你需要搜索下载CUDA,并在Pytorch网站上,确保选择正确的CUDA版本。如果仅打算在CPU模式下运行,请选择CUDA = None。
2.实战教程
这个模块用起来真的非常简单,三行代码完事了:
import easyocr
reader = easyocr.Reader(['ch_sim','en'])
result = reader.readtext('test.png')运行的过程中会安装所需要的模型文件,像下面这样:

不过它的下载速度非常慢,而且经常会失败,因此这里给出第二个解决方案:先下载好模型文件,再将其放置到所需要的位置:
如果下载速度太慢,可以评论区获取网盘下载地址, 下载我上传到微云网盘的文字检测模型(CRAFT)和中文简体模型文件包。
下载完模型后,将文件放到下面这个位置。
Windows:C:\Users\用户名.EasyOCR\model
Linux:~/ .EasyOCR / model
如下图所示:
重新执行脚本不会再提醒下载模型了:
import easyocr
reader = easyocr.Reader(['ch_sim'])
result = reader.readtext('test.png')
print(result)我随便截了一个直播弹幕的图片保存在脚本所在的文件夹下,命名为test.png:

结果如下:
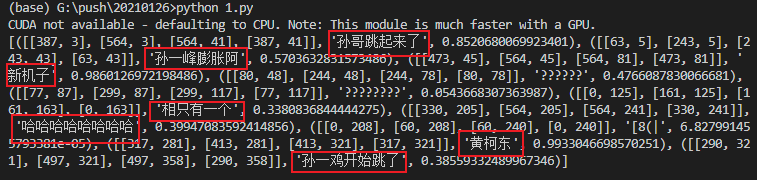
基本上所有应该识别的文字都识别出来了,效果非常不错。
另外也可以看到,输出采用列表格式,每个item分别表示对应文字的边界框,识别文本结果和置信度。
这个模块还能识别多语种的情况:

我将这张图片命名为test2.jpg,修改代码中对应的图片名称:
import easyocr
reader = easyocr.Reader(['ch_sim','en'])
result = reader.readtext('test2.jpg')
print(result)效果如下:
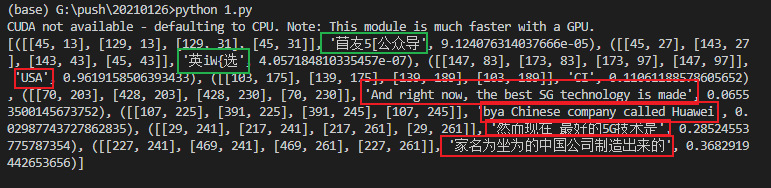
这张图片很复杂,而且是中英文混杂在一起的情况,但是可以看到模型除了左上角的水印,图片中的文字基本都是识别出来了,尽管有部分文字识别错误,但还在可以接受的范围之内。
不过需要注意的是,虽然可以一次性识别许多种语言,但并非所有语言都可以一起用,通常是公共语言和一个特殊语种可以一起识别,相互兼容,比如英语和日语。
如果你的电脑没有GPU或者显存不足,可以加一个gpu=false的参数仅使用CPU运行:
reader = easyocr.Reader(['ch_sim','en'], gpu = False)另外,这个模块还支持直接使用命令行运行,相当方便,大家可以试试:
easyocr -l ch_sim en -f test.png --detail=1 --gpu=True我们的文章到此就结束啦~
老表荐书
图书介绍:
《Excel+Python 飞速搞定数据分析与处理》xlwings创始人倾力打造,手把手教学“将Python作为Excel的脚本语言”开源Python库xlwings的诞生很好地回答了这些问题,它让Excel和Python珠联璧合。而作为xlwings的创始人,本书作者将展示如何借用Python的力量,让Excel快得飞起来!

点击下方小程序直接购买学习
购买后加我微信,准备开启一期技术图书:实践读书会,21天读《Excel+Python 飞速搞定数据分析与处理》+实践+直播交流,参与规则:
1、必须购买本书,购买后扫码加我微信:pythonbrief;
2、参与需缴纳9.9元老表读书会基金,完成学习后会退还6.6元(剩余费用用于维持读书会奖励和后期发展)
3、坚持连续21天学习,服务包括参与群内讨论+3次小作业+1次大作业+2次直播
4、学习完成标准:第一次简单点,完成3小+1大作业即算完成学习
【注】本期限额30人,报名成功与否,按缴纳报名费用转账时间为准,预计下周开始,最近两天忙,消息回复较慢。