
CPU:一核有难,八核围观
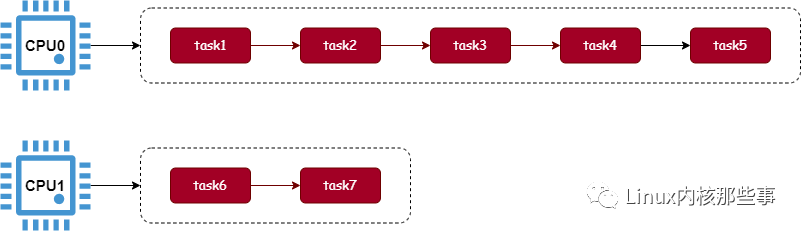
在《一文读懂 | 进程怎么绑定 CPU》这篇文章中介绍过,在 Linux 内核中会为每个 CPU 创建一个可运行进程队列,由于每个 CPU 都拥有一个可运行进程队列,那么就有可能会出现每个可运行进程队列之间的进程数不一样的问题,这就是所谓的 负载不均衡 问题,如下图所示:
(图1)
最极端的情况是,一个 CPU 的可运行进程队列拥有非常多的进程,而其他 CPU 的可运行进程队列为空,这就是著名的 一核有难,多核围观,如下图:

(图2)
为了避免这个问题的出现,Linux 内核实现了 CPU 可运行进程队列之间的负载均衡。接下来,我们将会介绍 CPU 间的负载均衡的实现原理。
本文使用的内核版本为:Linux-2.6.23
CPU 间负载均衡原理
CPU 间负载不均衡的根本原因就是,CPU 的可运行进程队列中的进程数量不均衡导致的。所以,要解决 CPU 间负载不均衡的方法就是:将最繁忙的 CPU 可运行进程队列的一些进程迁移到其他比较空闲的 CPU 中,从而达到 CPU 间负载均衡的目的。
当然,在 2.6.0 版本的内核的确是这样实现的,我们可以看看其实现代码:
static void
load_balance(runqueue_t *this_rq, int idle, cpumask_t cpumask)
{
int imbalance, idx, this_cpu = smp_processor_id();
runqueue_t *busiest;
prio_array_t *array;
struct list_head *head, *curr;
task_t *tmp;
// 1. 找到最繁忙的 CPU 运行队列
busiest = find_busiest_queue(this_rq, this_cpu, idle, &imbalance, cpumask);
if (!busiest)
goto out;
...
head = array->queue + idx;
curr = head->prev;
skip_queue:
// 2. 从最繁忙运行队列中取得一个进程
tmp = list_entry(curr, task_t, run_list);
...
// 3. 把进程从最繁忙的可运行队列中迁移到当前可运行队列中
pull_task(busiest, array, tmp, this_rq, this_cpu);
...
}
load_balance 函数主要用于解决 CPU 间负载均衡问题,其主要完成以下 3 个步骤:
从所有 CPU 的可运行队列中找到最繁忙的可运行队列。 从最繁忙可运行队列中取得一个进程。 把进程从最繁忙的可运行队列中迁移到当前可运行队列中。
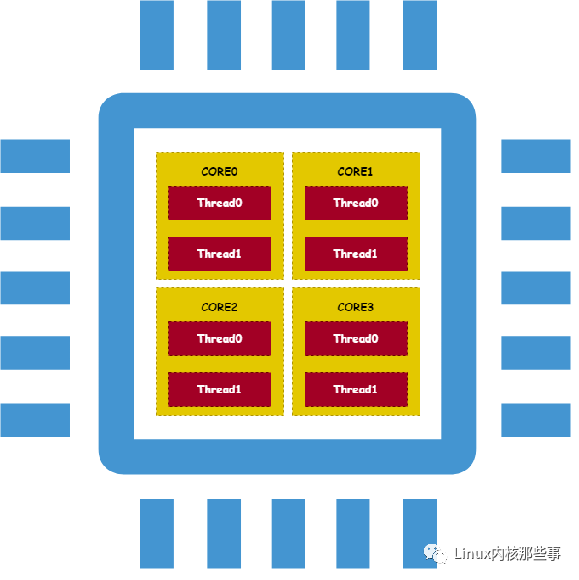
这是 2.6.0 版本的解决方案,但这个方案并不是最优的,因为现代 CPU 架构是非常复杂的,比如一个物理 CPU 有多个核心(多核),而每个核心又可以通过超线程(Hyper-Threading)来实现多个逻辑 CPU,如下图所示:
(图3)
如上图所示,一个物理 CPU 中拥有 4 个核心,而每个核心又拥有 2 个超线程。在 Linux 内核中,会为每个超线程定义一个可运行进程队列,所以 Linux 内核会为上面的 CPU 定义 8 个可运行进程队列。
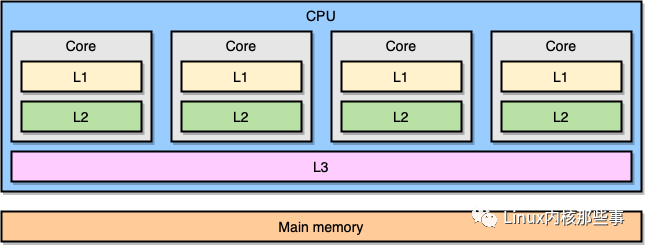
现在问题来了,在上面的 CPU 架构中,不同的可运行队列之间的进程迁移代价是不一样的。因为同一个核心的不同超线程共用了所有的缓存,所以同一个核心不同超线程间的进程迁移代价是最小的。
而同一个物理 CPU 不同核心间也会共用某些缓存,所以不同核心间的进程迁移的代价会比同一核心不同超线程间的进程迁移稍大。由于现在很多主板都支持安装多个物理 CPU,而不同物理 CPU 间基本不会共用缓存,所以不同物理 CPU 间的进程迁移代价最大。如下图所示(图中的 L1、L2 和 L3 分别指一级、二级和三级缓存):
(图4)
为了解决进程迁移成本的问题,新版本的 Linux 内核引入了 调度域 和 调度组。
调度域与调度组
从前面的分析可知,根据 CPU 的物理架构可以划分为:不同的物理 CPU、相同 CPU 不同的核心、相同核心不同的超线程等,如下图所示:

(图5)
在 Linux 内核中,把这个层级成为 调度域。从前面的分析可知,越下层的调度域共用的缓存就越多,所以在进程迁移时,优先从底层的调度域开始进行。
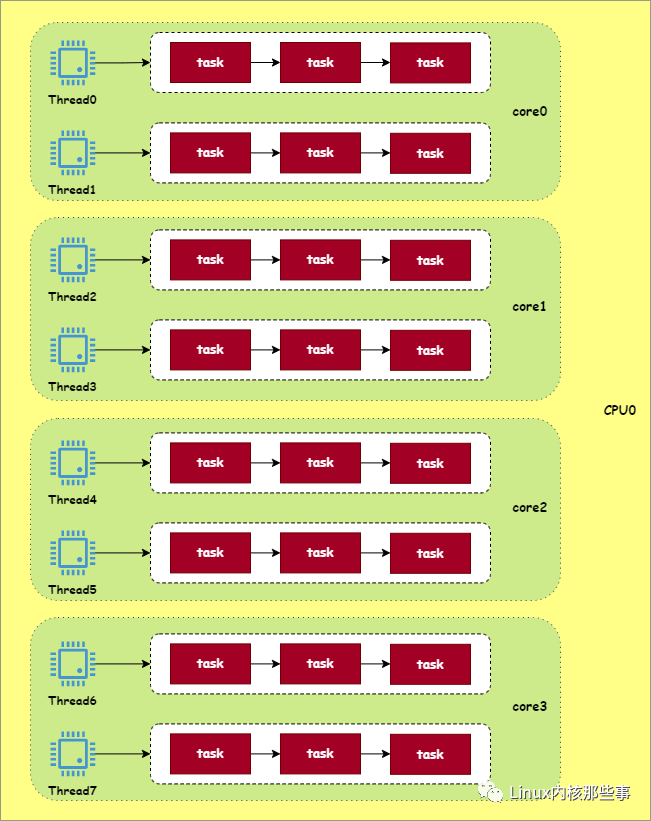
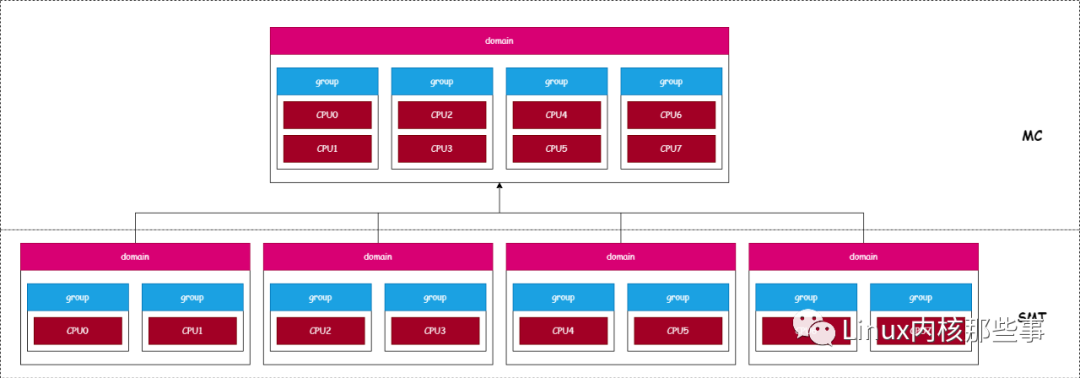
由于内核为每个超线程定义一个可运行队列,所以图 3 中的 CPU 拥有 8 个可运行队列。而根据不同的调度域,可以把这 8 个可运行队列划分为不同的 调度组,如下图所示:
(图6)
如上图所示,由于每个超线程都拥有一个可运行队列,所以图 3 的 CPU 拥有 8 个可运行队列,而这些可运行队列可以根据不同的核心来划分为 4 个调度组,而这 4 个调度组可以根据不同的物理 CPU 来划分成 1 个调度组。
由于越底层的调度域共用的缓存越多,所以对 CPU 可运行队列进行负载均衡时,优先从底层调度域开始。比如把 Thread0 可运行队列的进程迁移到 Thread1 可运行队列的代价要比迁移到 Thread2 可运行队列的小,这是由于 Thread0 与 Thread1 属于同一个核心,同一个核心共用所有的 CPU 缓存。
在 Linux 内核中,调度域使用 sched_domain 结构表示,而调度组使用 sched_group 结构表示。我们来看看 sched_domain 结构的定义:
struct sched_domain {
struct sched_domain *parent; /* top domain must be null terminated */
struct sched_domain *child; /* bottom domain must be null terminated */
struct sched_group *groups; /* the balancing groups of the domain */
cpumask_t span; /* span of all CPUs in this domain */
...
};
下面介绍一下 sched_domain 结构各个字段的作用:
parent:由于调度域是分层的,上层调度域是下层的调度域的父亲,所以这个字段指向的是当前调度域的上层调度域。child:如上所述,这个字段用来指向当前调度域的下层调度域。groups:每个调度域都拥有一批调度组,所以这个字段指向的是属于当前调度域的调度组列表。span:这个字段主要用来标记属于当前调度域的 CPU 列表(每个位表示一个 CPU)。
我们接着分析一下 sched_group 结构,其定义如下:
struct sched_group {
struct sched_group *next;
cpumask_t cpumask;
...
};
下面介绍一下 sched_group 结构各个字段的作用:
next:指向属于同一个调度域的下一个调度组。cpumask:用于标记属于当前调度组的 CPU 列表(每个位表示一个 CPU)。
它们之间的关系如下图所示:
(图7)
CPU 间负载均衡实现
要实现 CPU 间的负载均衡,只需要将最繁忙的可运行队列中的一部分进程迁移到空闲的可运行队列中即可。但由于 CPU 缓存的原因,对使用不同的 CPU 缓存的可运行队列之间进行进程迁移,将会导致缓存丢失,从而导致性能损耗。所以,Linux 内核会优先对使用相同 CPU 缓存的可运行队列之间进行进程迁移。
1. CPU 间负载均衡触发时机
当 CPU 的负载不均衡时,内核就需要对 CPU 进行负载均衡。负载均衡的触发时机比较多,如进程被创建、进程被唤醒、进程休眠和时钟中断等,这里我们介绍一下在时钟中断时怎么进行 CPU 间的负载均衡。
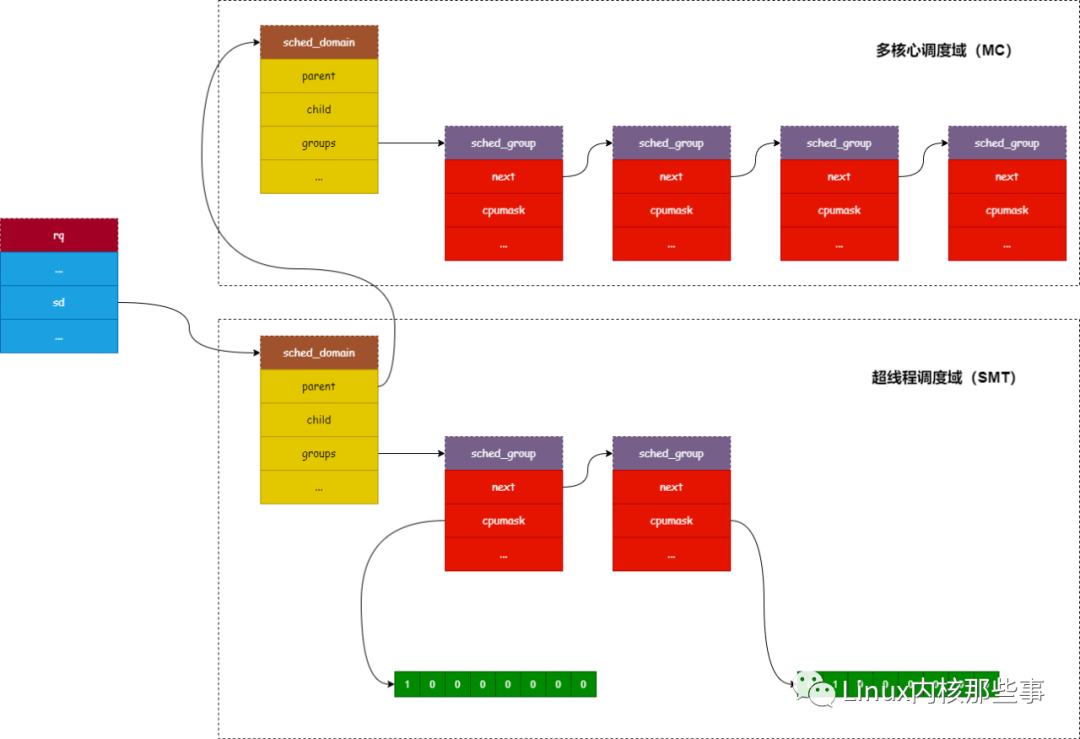
在 Linux 内核中是通过 rq 结构来描述一个可运行进程队列的,它有个名为 sd 的字段用于指向其所属的 调度域 层级的最底层,如下所示:
struct rq {
...
struct sched_domain *sd;
...
}
它与调度域和调度组的关系如下图所示:
(图8)
在时钟中断下半部处理中,会通过调用 run_rebalance_domains 函数来对 CPU 进行负载均衡处理,而 run_rebalance_domains 接着会通过调用 rebalance_domains 函数来完成负载均衡的工作,其实现如下:
static inline void
rebalance_domains(int cpu, enum cpu_idle_type idle)
{
int balance = 1;
struct rq *rq = cpu_rq(cpu);
unsigned long interval;
struct sched_domain *sd;
unsigned long next_balance = jiffies + 60*HZ;
int update_next_balance = 0;
// 遍历可运行队列的调度组层级 (从最底层开始)
for_each_domain(cpu, sd) {
...
// 由于对 CPU 进行负载均衡可能会导致 CPU 缓存丢失
// 所以对 CPU 进行负载均衡不能太频繁, 必须隔一段时间才能进行
// 这里就是判断上次进行负载均衡与这次的间隔是否已经达到合适的时间
// 如果时间间隔已经达到一段时间, 那么就调用 load_balance 函数进行负载均衡
if (time_after_eq(jiffies, sd->last_balance + interval)) {
if (load_balance(cpu, rq, sd, idle, &balance)) {
idle = CPU_NOT_IDLE;
}
sd->last_balance = jiffies;
}
...
}
...
}
由于每个 CPU(超线程)都有一个可运行队列,而 rebalance_domains 函数的工作就是获取当前 CPU (超线程)的可运行队列,然后从最底层开始遍历其调度域层级(由于越底层的调度域,进行进程迁移的代价越小)。
由于对 CPU 进行负载均衡可能会导致 CPU 缓存丢失,所以对 CPU 进行负载均衡不能太频繁(需要隔一段时间才能进行)。那么在对 CPU 进行负载均衡前,就需要判断上次进行负载均衡与这次的时间间隔是否合理。如果时间间隔合理, 那么就调用 load_balance 函数对调度域进行负载均衡。
load_balance 函数实现如下:
static int
load_balance(int this_cpu, struct rq *this_rq, struct sched_domain *sd,
enum cpu_idle_type idle, int *balance)
{
...
redo:
// 1. 从调度域中找到一个最繁忙的调度组
group = find_busiest_group(sd, this_cpu, &imbalance, idle, &sd_idle,
&cpus, balance);
...
// 2. 从最繁忙的调度组中找到一个最繁忙的运行队列
busiest = find_busiest_queue(group, idle, imbalance, &cpus);
...
if (busiest->nr_running > 1) {
...
// 3. 从最繁忙的运行队列中迁移一些任务到当前任务队列
ld_moved = move_tasks(this_rq, this_cpu, busiest, imbalance, sd, idle,
&all_pinned);
...
}
...
return 0;
}
load_balance 函数主要完成 3 个工作:
从 调度域中找到一个最繁忙的调度组。从最繁忙的 调度组中找到一个最繁忙的可运行队列。从最繁忙的 可运行队列中迁移一些任务到当前可运行队列。
这样就完成了 CPU 间的负载均衡处理。