
130 行代码搞定核酸统计。。。
点击上方[全栈开发者社区]→右上角[...]→[设为星标⭐
点击领取全栈资料:全栈资料

这段时间以来,全国各地的疫情发展牵动人心。为了更好地配合疫情防控,复旦大学自三月初以来启动了常态化核酸筛查工作。
这一工作要求辅导员挨个检查学生“健康云”核酸完成截图,确保“不漏一人”。听上去简单,做起来难。面对几十甚至上百张重复性高的截图,人工核查往往耗时耗力,一不小心还会看错看漏。
为了解决这一难题,信息科学与工程学院博士生李小康写出130行代码,快速开发出了一项小程序。
这项小程序大大提高了核酸核查的速度和精度,使得原来需要几个人核对一个多小时的800幅截图,现在只需2分钟就能拿到结果。
图源:微博截图
随后,李小康的事迹火上热搜,《人民日报》也为他点赞:“知识就是力量!”
灵光一现,说干就干
据复旦大学官方介绍,李小康是信息科学与工程学院的一名博士生,专业为生物医学工程,研究方向是医学影像与人工智能。在平时的科研生活中,他经常会接触到很多图像处理方法。
除此之外,李小康也是学院2019级信息1班辅导员。在学校进入准封闭管理之后,他同时还担任志愿者一职。

李小康正在做志愿者(图源:复旦大学公众号)
面对日常繁琐的抗疫工作,得益于长期的科研习惯和代码敏感性,李小康萌生了写一个代码程序用于自动核查核酸完成截图的想法。
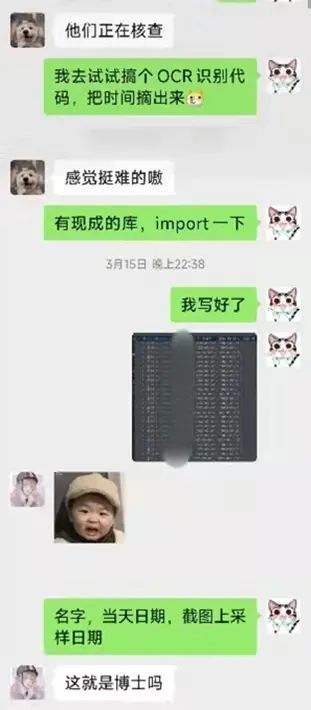
李小康与学工同事的聊天(图源:复旦大学公众号)
说干就干,3月15日晚,李小康花了一个多小时就搞定了初始代码。程序一写好,他就验证了自己班级的核酸截图数据,发现准确率很高,甚至检测出了之前人工核查时没发现的问题。
同时,程序运行的时间也很短,80多张图只需要20多秒,大大提升了核查的精度和速度,也减轻了相关人员的工作负担。
程序实现原理并不复杂
如此高效的程序是怎么实现的呢?说起原理,李小康认为并不复杂。
他首先想到了OCR(Optical Character Recognition,光学字符识别)技术,这一技术可以识别出图像中的文字,并转换为文本信息。
由于图片中的信息并不是全都有用,李小康又想到了Python中的正则表达式,它可以把想要的信息从OCR识别的文本中筛选出来。
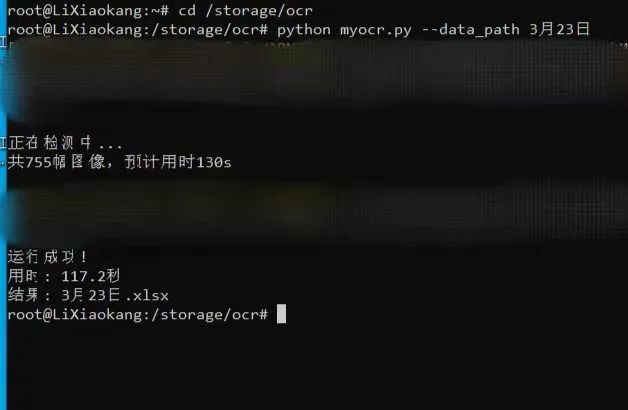
程序实际运行过程(图源:复旦大学公众号)
基于OCR文字识别+正则表达式筛选的这一思路,李小康开发的程序实现了将所需信息从识别的文本中筛选出来。在确认好每张截图的相关信息后,将所有人的结果输出到一个Excel文件中,方便人工确认。
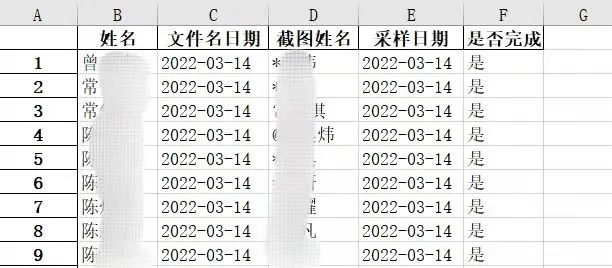
程序输出的Excel文件(图源:复旦大学公众号)
学以致用,积极战疫
谈及开发程序的初衷,李小康表示自己只是为了减少自己和身边老师的工作量。因为程序是用Python编写的,代码注释也很完整,所以会使用Python的可以很快上手。
同时为了方便不会编程的老师使用,李小康还把程序进行了封装,只需简单输入一行代码就能运行。
用李小康的原话来说:“虽然原理也很简单,只要是会写代码的人第一时间就会明白是怎么回事,但是不做相关工作,感受不到这件事情的费时费力,自然也不会想出办法。我只是用我学到的知识解决实际工作中的困难。”
复旦大学官方透露,学校信息办已经和李小康对接,正在根据需求开发新的小程序。预计不久之后,师生们就不用再手动收集核酸截图,只需通过小程序直接上传图片就能查看统计结果。
觉得本文对你有帮助?请分享给更多人
关注「全栈开发者社区」加星标,提升全栈技能
本公众号会不定期给大家发福利,包括送书、学习资源等,敬请期待吧!
如果感觉推送内容不错,不妨右下角点个在看转发朋友圈或收藏,感谢支持。
好文章,留言、点赞、在看和分享一条龙