
滴滴开源监控平台Logi-KafkaManager实战

滴滴开源了其Kafka 监控与管控平台 Logi-KafkaManager,因为有30+个集群的维护经验,使用过kafka-manager,kafka-eagle,kafka-mirrorkaker工具,所以很期待能有1个工具能够整合kafka所有工具优点于一身,这样对于生产环境中kafka集群的管理、监控、资源分配、平滑升级、数据跨机房传输是非常好的,所以在研究kafka源码的同时研究一下Logi-KafkaManager的源码和使用,滴滴提供了体验地址:http://117.51.150.133:8080/kafka ,账户:admin/admin。
一、调试环境搭建
前端调试环境
github克隆比较慢gitee很快,采取前后端分离架构(springboot+reactJS+Typescript),代码包含了几个模块common,console,core,dao,extends,task,web,其中web中有MainApplication这个项目的启动类,其他都是依赖,console模块是基于recat+typescript的前端界面(技术栈选型还是很超前的),本地分别对前后端运行查看源码,这里把console单独放在VScode中运行;
# react跟vue一样基于node,所以npm相关依赖引入和配置启动
npm config set registry https://registry.npm.taobao.org
npm config list #查看npm当前配置
npm install
# 启动react项目
npm start
console前端模块启动运行:
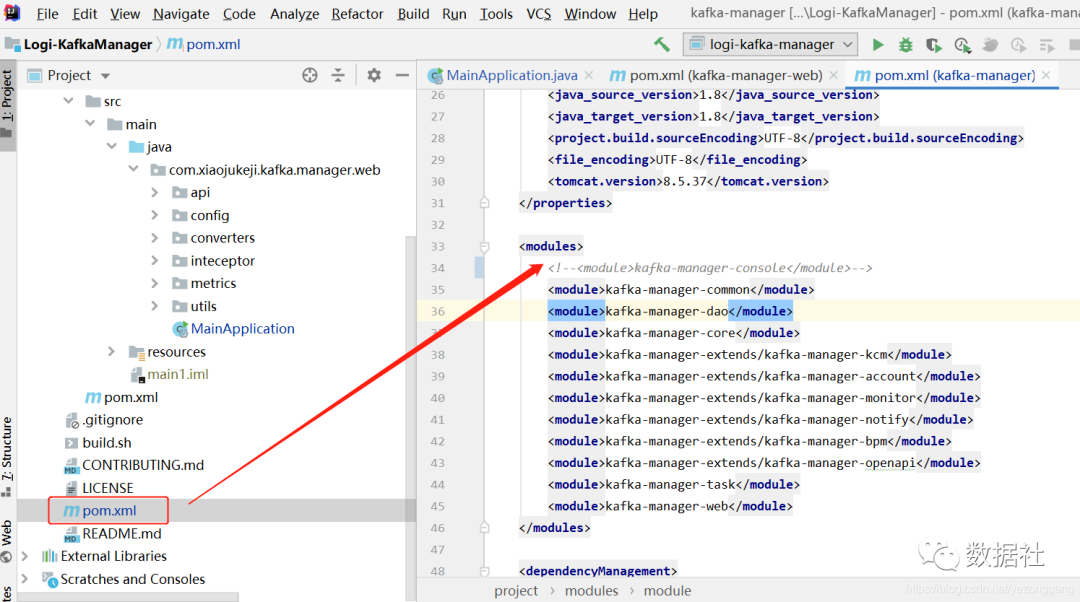
 因为前后端分别用idea和vscode,所以后端项目pom.xml需要注释掉对于console前端模块的引用:
因为前后端分别用idea和vscode,所以后端项目pom.xml需要注释掉对于console前端模块的引用:
后端调试环境
依赖Maven 3.5+(后端打包),node v12+(前端打包),Java 8+(运行环境需要),MySQL 5.7(数据存储),node因为放在vscode了所以不需要,在mysql创建kafka_manager库,并且运行sql初始化语句,同时修改springboot中的mysql配置(这里官方提供的sql语句没有加字符集设置,需要加上不然报错)
mysql --default-character-set=utf8 -uroot -p123456 -P3306 -D kafka_manager < create_mysql_table.sql
将web模块的MainApplication.java配置成应用主类即可启动;
2021-01-25 19:33:22.642 INFO 18000 --- [ main] c.x.kafka.manager.web.MainApplication : MainApplication started
由于是本地运行,console模块的API的proxy/target需要修改:
proxy: {
'/api/v1/': {
target: 'http://127.0.0.1:8080',
//target: 'http://10.179.37.199:8008',
// target: 'http://99.11.45.164:8888',
changeOrigin: true,
}
以上,本地独立运行了基于前后端分离的调试环境;可以看见前端读取的是mysql库中kafka集群配置;
二、功能架构
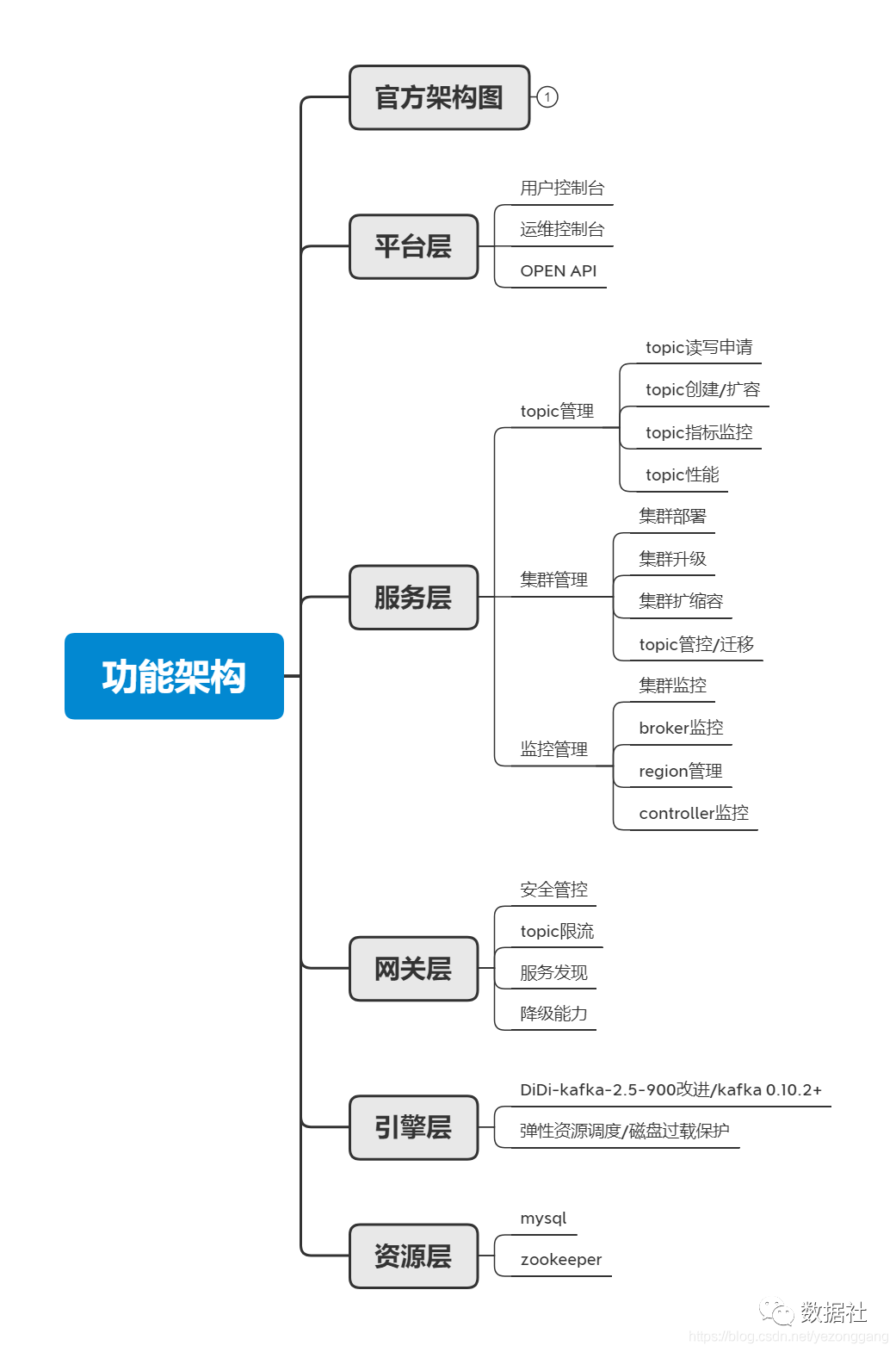
按照官方提供的功能架构图理解,因为logi-kafka-manager的定位是kafka集群全方位管控系统,它以kafka集群为主体,封装和集成了kafka对外提供的用户API,,以kafka集群和topic资源为运营对象,面向应用系统用户(topic使用者)、kafka/管控平台开发者、kafka/管控平台运维者提供便捷的资源管理能力。按照这个思维理解,官方给的功能架构包括:资源层(zk和mysql元数据存储)、引擎层(kafka集群为主体)、网关层(kafka服务基础管理能力)、服务层(高级用户api)、平台层(面向不同用户);
三、部署验证
windows环境下的部署/调试环境
这里在win系统下本地kafka+logi-kafka-manager的联调测试验证,用于对于kafka+logi-kafka-manager的源码研究和联调,关于win环境下如何部署zookeeper以及idea中运行kafka集群可以参考之前系列文章:《kafka实践(十二):生产者(KafkaProducer)源码详解和调试》,环境配置如下:
本地启动zookeeper(3.4.12),服务端口2181; 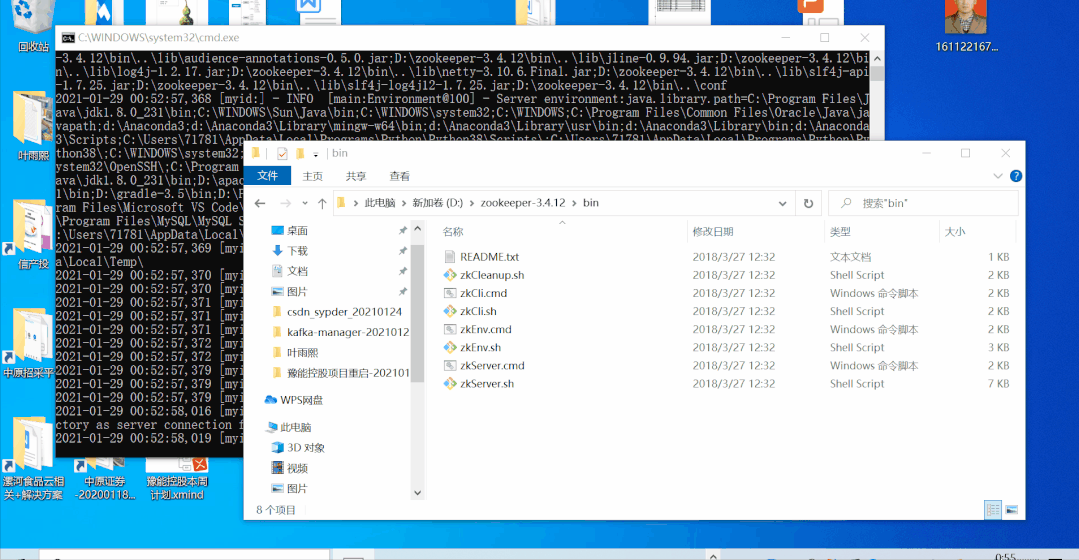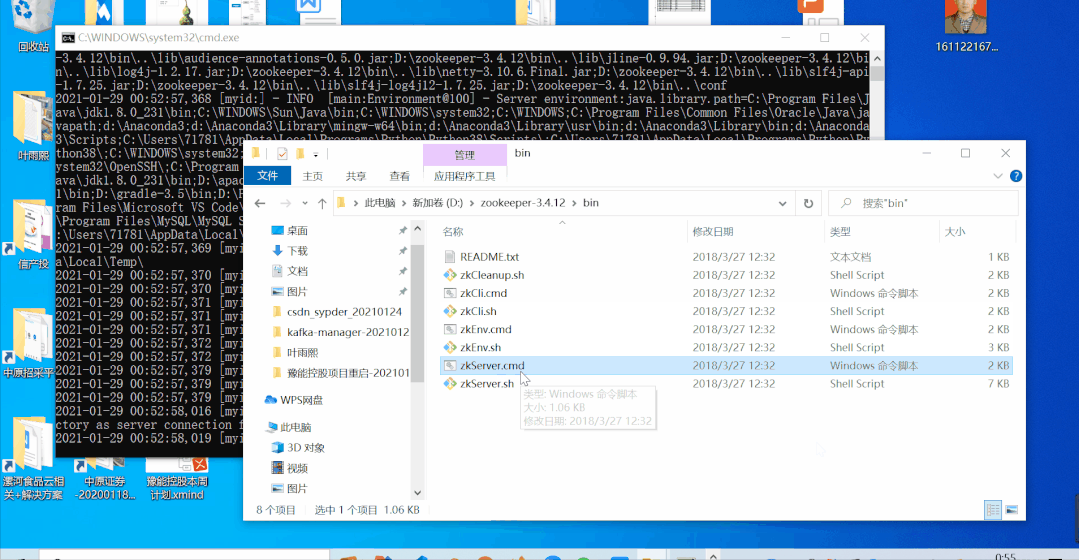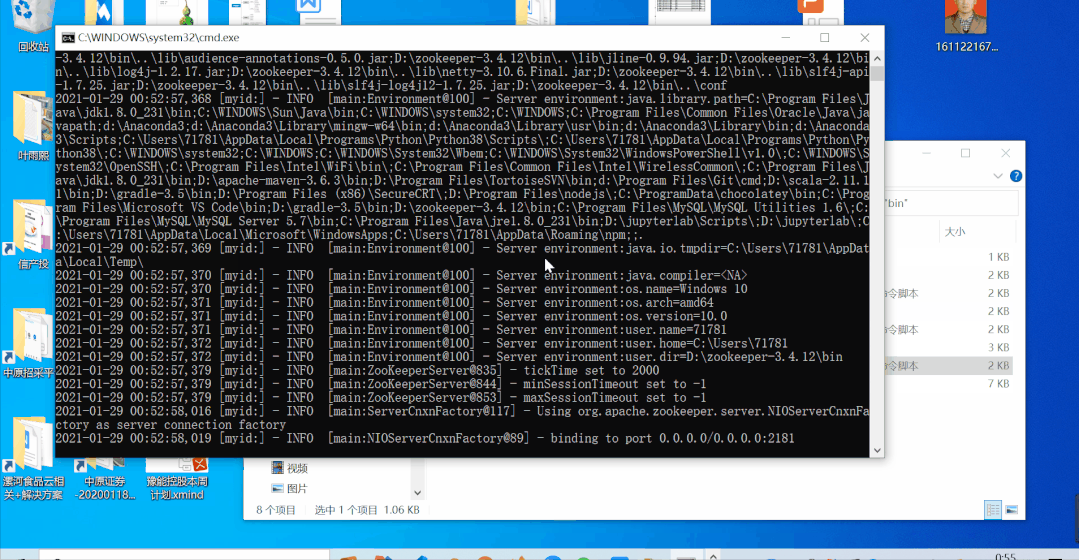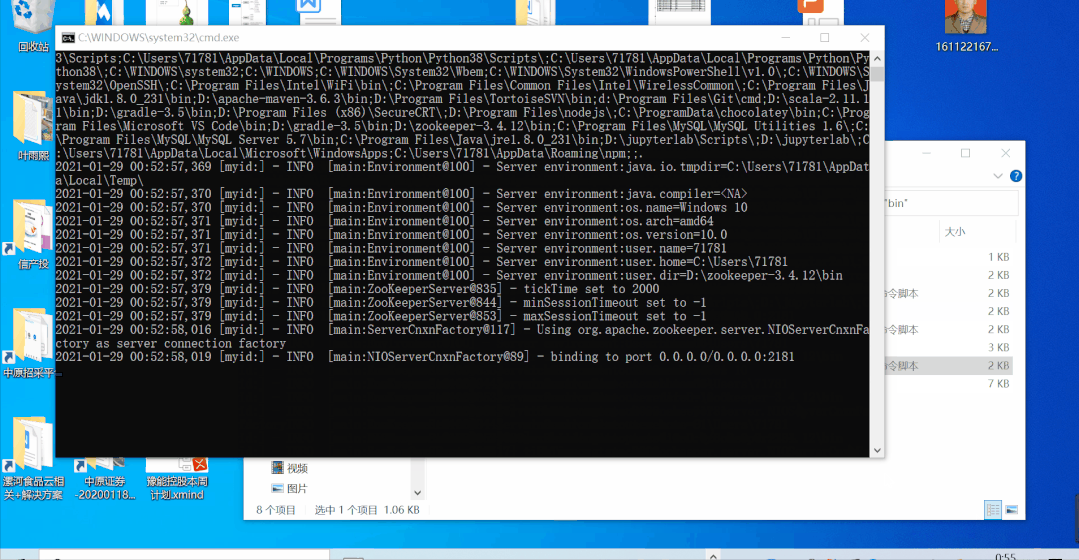
idea上本地启动kafka集群(1.0版本),对外暴露9999端口服务,且本地已创建yzg这个topic; 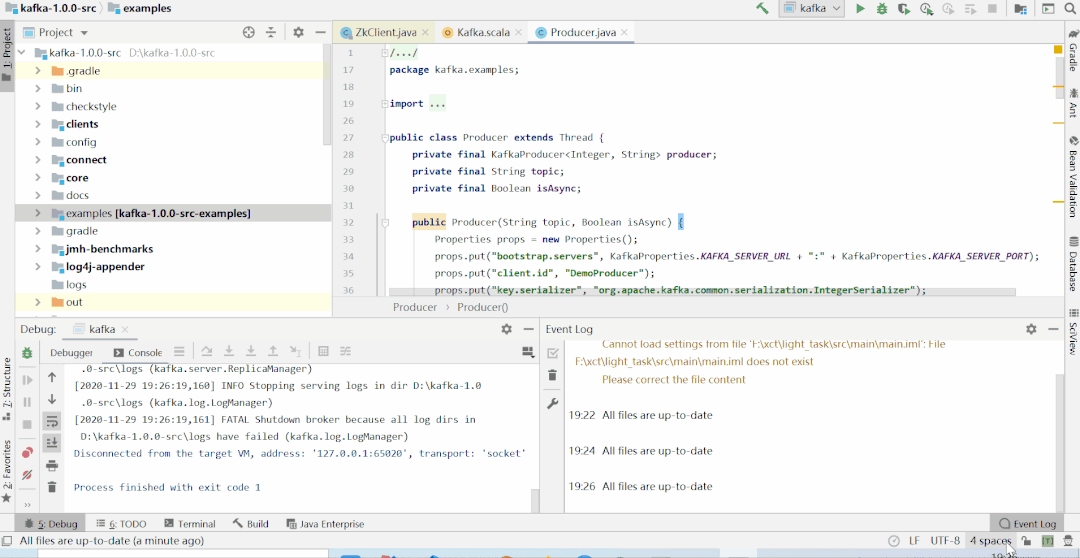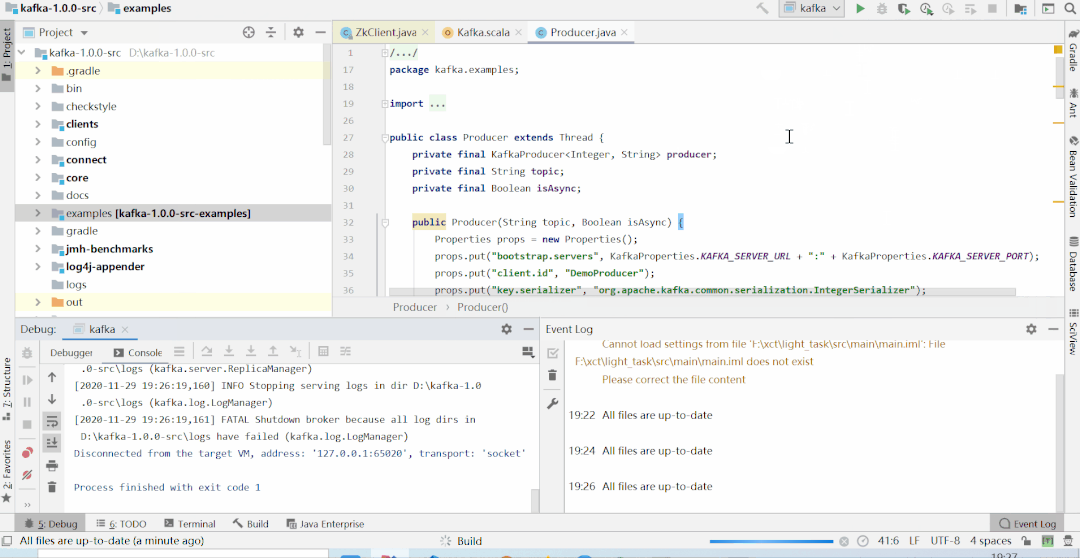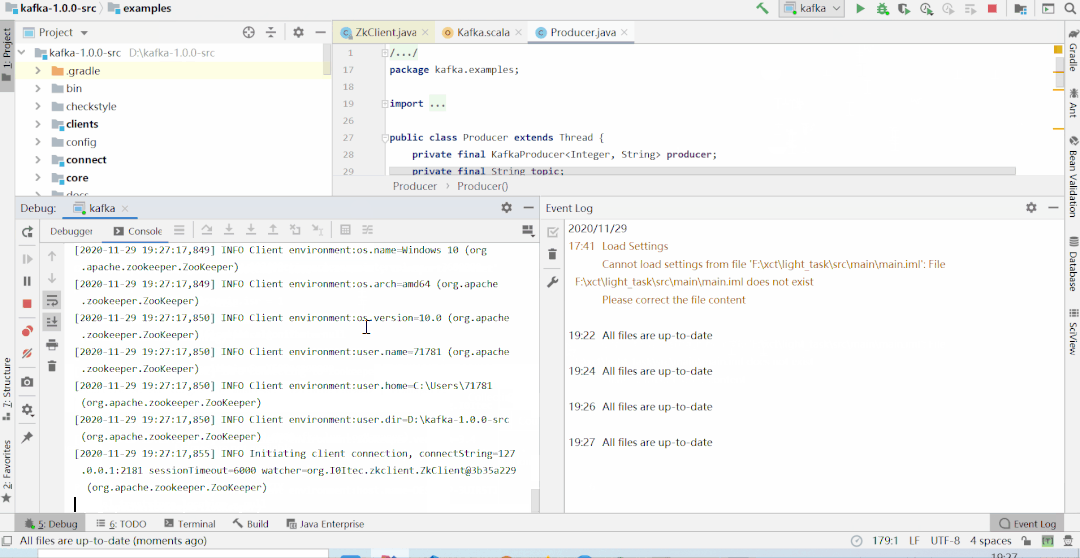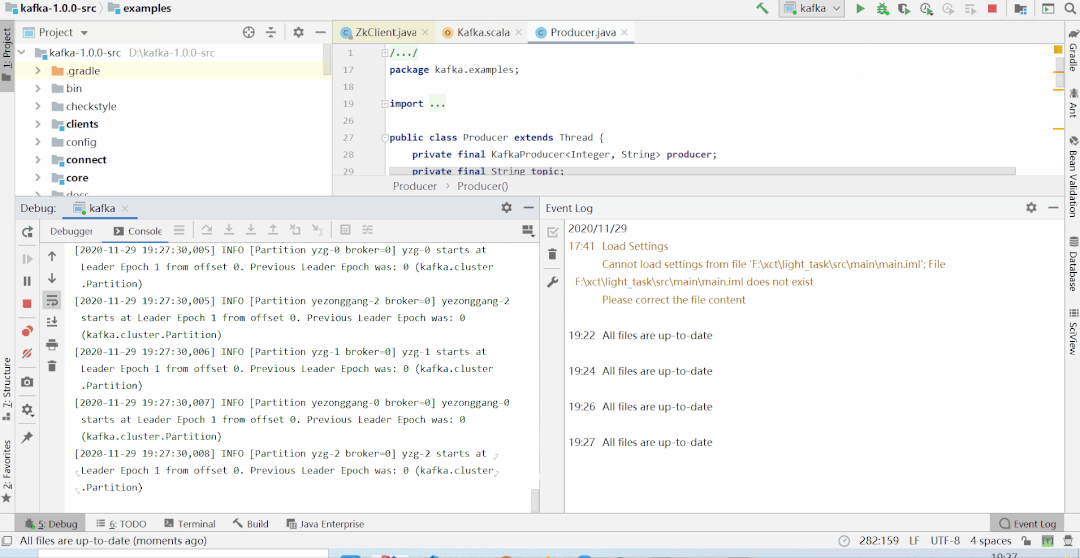
idea上本地启动logi-kafka-manager后端模块,参考上面配置; vscode本地启动console前端模块,本地调试环境搭建完毕:http://127.0.0.1:1025/
本地测试增加kafka集群到logi-kafka-manager内进行统一管理,新增的本地集群的zk地址和kafka地址,就可以统一管理broker和topic,以及后续的资源分配,win下实现环境配置方便源码调整和kafka/管控平台人员的调试;
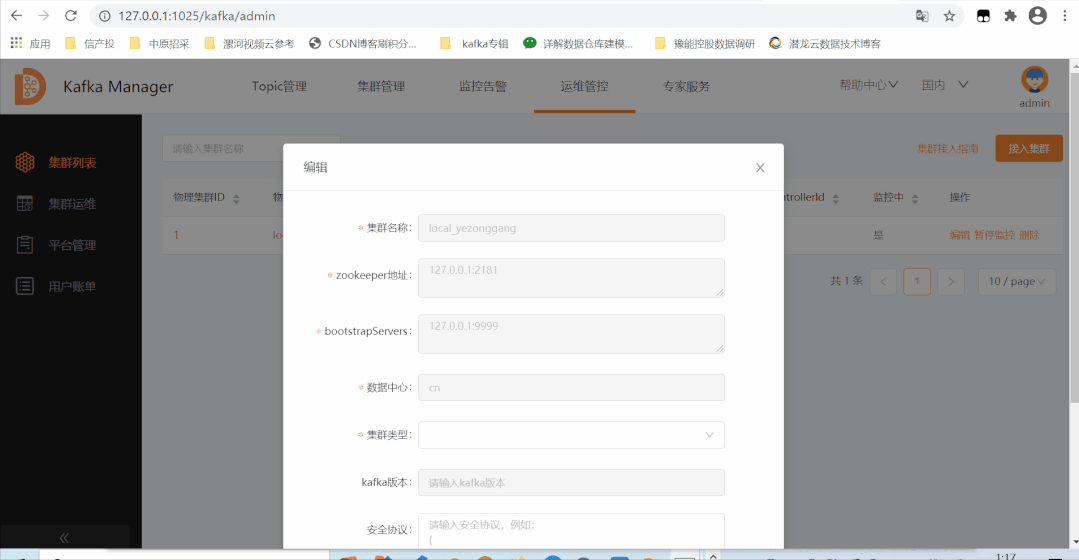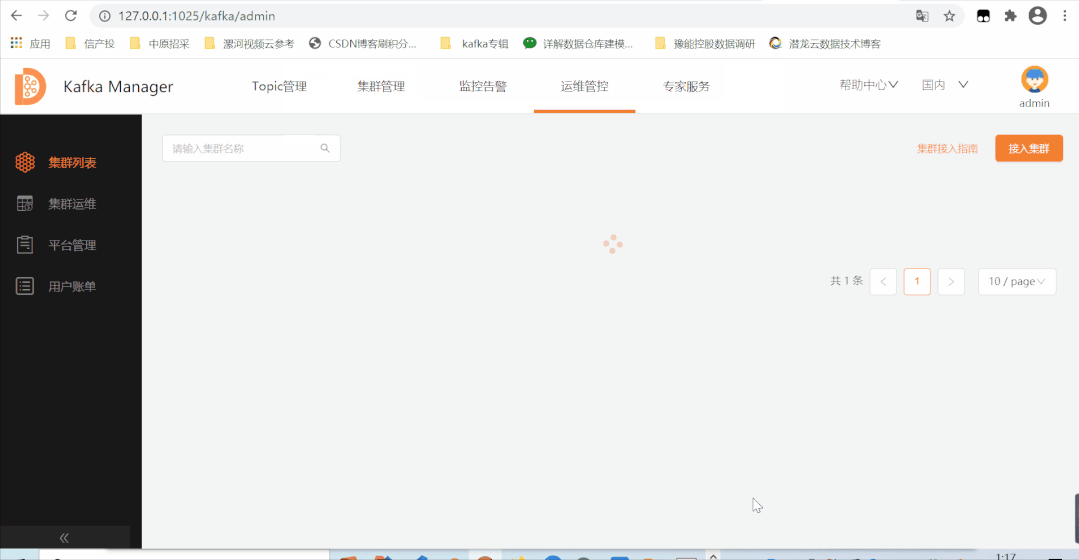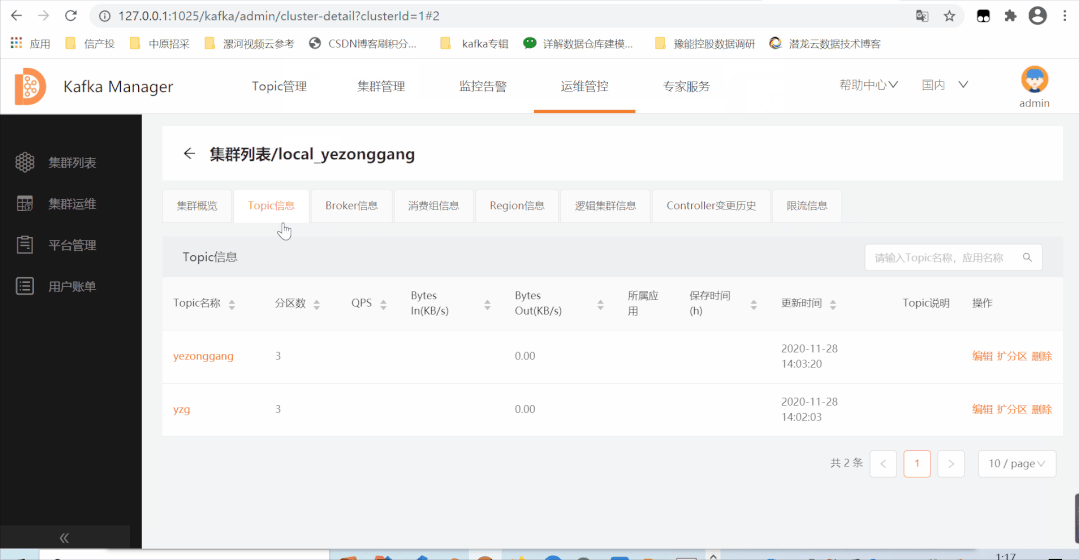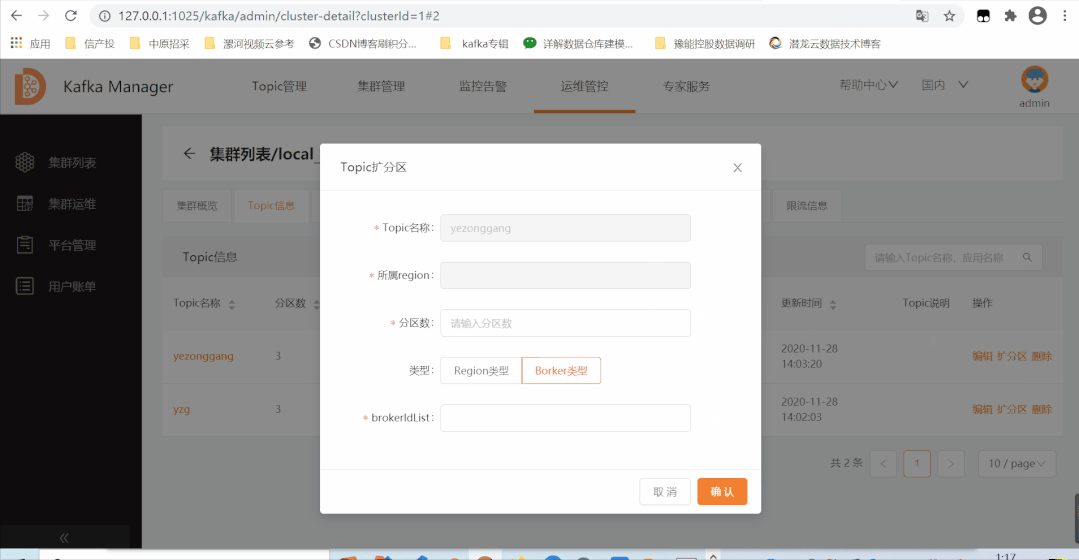
linux环境下生产使用
linux环境下的生产部署使用则更为简单,zk和kafka部署完成后,按照官方文档指引进行前后端统一部署,不再验证;
# mvn会调用npm模块下载node依赖
mvn install
# application.yml 是配置文件
cp kafka-manager-web/src/main/resources/application.yml kafka-manager-web/target/
cd kafka-manager-web/target/
nohup java -jar kafka-manager-web-2.1.0-SNAPSHOT.jar --spring.config.location=./application.yml > /dev/null 2>&1 &
四、工具理解
应用开发人员
针对应用开发人员,只关心其当前的应用系统的数据(多为日志数据)应发到哪个集群下的哪个topic?,因此logi-kafka-manager提供了“Topic管理”--“集群管理”--“监控告警”应用菜单服务,能提供以下几种服务:
创建/申请应用
在“Topic管理”内对当前的申请应用,匹配需要使用的topic资源(可调整配额和分区)
kafka集群接入申请
在“监控告警”内自定义告警规则;(对消费偏移量、消费速率、集群状态、topic状态进行自定义监控,并实时预警,太有用了!)
资源申请服务
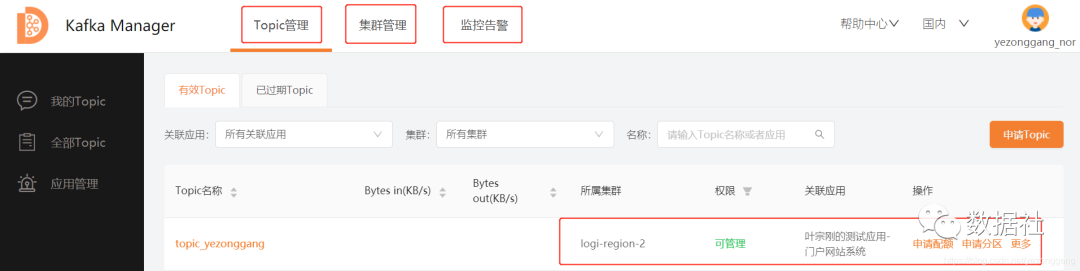
kafka/管控开发人员
针对kafka/管控开发人员,需要进行应用系统、kafka集群、kafka管控平台的综合管理,增加“运维管控”菜单,提供对于kafka集群的server.config配置等集群运维能力和用户计费账单管理能力,能提供以下几种服务:
创建/申请应用 在“Topic管理”内对当前的申请应用,匹配需要使用的topic资源(可调整配额和分区) 在“监控告警”内自定义告警规则 kafka集群接入、升级、配置修改能力 应用管理能力 平台用户计费账单管理能力 资源申请服务 
kafka/管控运维人员
针对kafka/管控运维人员,需要及时发现解决kafka集群问题和快速修复,提供“专家服务”,罗列常见问题和解决方法,提供以下几种服务:
创建/申请应用 在“Topic管理”内对当前的申请应用,匹配需要使用的topic资源(可调整配额和分区) 在“监控告警”内自定义告警规则 kafka集群接入、升级、配置修改能力 应用管理能力 平台用户计费账单管理能力 kafka集群常见问题及修复方案 资源申请服务 
五、对社区的建议
对于logi-kafka-manager工具,期待整合Mirror-maker跨机房数据传输工具,更方便地配置数据实时传输和效率监控!
更多阅读
特别推荐

点击下方阅读原文加入社区会员