
Amoro 开源 | 从 Arctic 到 Amoro:我们的开源旅程和愿景
大家好,我是 Arctic Maintainer 成员凌断,去年 8 月我们开源了 Arctic 项目,感谢各位小伙伴一年来的陪伴,借这个一周年的时机,我想跟大家分享一些信息。
01
项目更名
第一,Arctic 项目名称今日起正式变更为 Amoro [/aˈmoro/],项目官网和 GitHub 同步变更:
官网:https://amoro.netease.com/
文档:https://amoro.netease.com/docs/latest/
源码:https://github.com/NetEase/amoro
原先以 Arctic 命名的官网,文档和源码地址会重新定向到 Amoro。
虽然 Arctic 这个名称深受大家喜爱,但与一些知名软件商标冲突,不利于长期规划,下面列举两个 Arctic 商标冲突的软件:
Man Group 开源的名为 Arctic 的 Python 数据库项目:https://github.com/man-group/arctic
Dremio 的 Arctic 组件:https://www.dremio.com/platform/arctic/
另一方面,Arctic 的灵感更多源于 Apache Iceberg 这个优秀的开源项目,但是在这开源的一年时间里我们发现一个可以适配更多数据湖格式的湖仓管理系统更加符合社区用户的需要,后续我们依然会围绕 Iceberg 去构建更多湖仓一体和湖原生实践,同时也会在社区的驱动下对接更多的数据湖格式,希望这个开源项目能够为这个方向带来一些有意义的变化,为此我们期望能够赋予这个项目一个更加通用的名称。
我们认为字母 A 和这个项目有缘(下面会展开聊聊),所以在 ChatGPT 中输入了以下的 propmt。
给我想一个以字母 A 开头,字符不超过 6 位,朗朗上口易于传播的软件名称,避免跟已知软件存在商标冲突。
经过多次纠偏和商标确认,得到了 Amoro [/aˈmoro/] 这个名字,下面是全新设计的 LOGO,这里特别感谢家超同学在视觉设计上的创意和付出:
02
项目定位
我想通过倒立的字母 A 来聊聊这个项目是什么,为什么做:
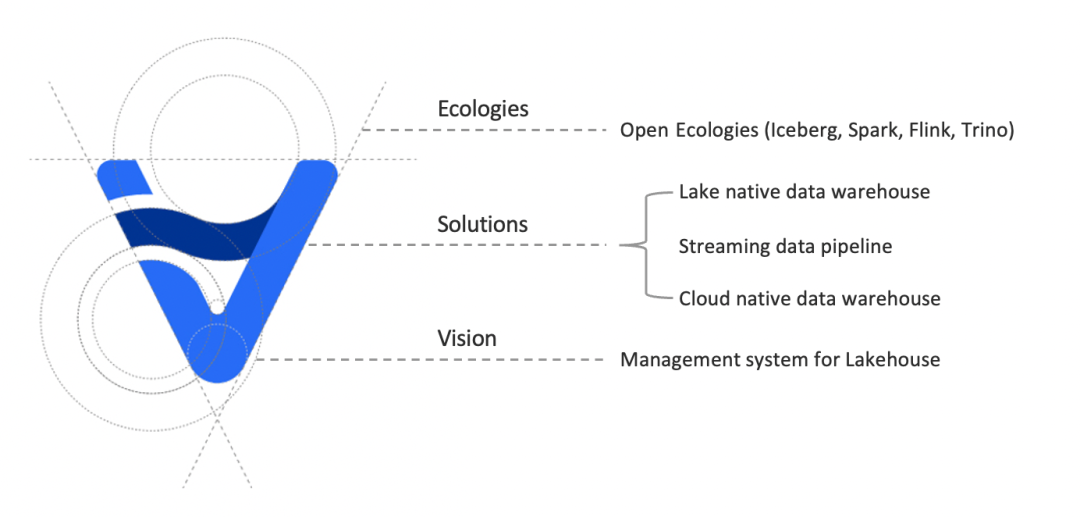
拥抱开源生态
倒立的 A 最上面的部分是一个向上的开口,就像是一个人张开双臂拥抱这个世界,也象征着这个项目会以最开放的方式和各种开源软件一起工作,包括:
不会从 0 做一个数据湖 format
以社区驱动积极对接不同数据湖 format
以社区驱动积极对接各种计算引擎
尽可能以可插拔的架构来对接服务,比如 Kyuubi,消息队列
我想举两个例子来说明 Amoro 的开放性。
第一,Amoro 目前活跃的社区用户,绝大多数都是 Apache Iceberg 的原生用户,Amoro 提供了原生 Iceberg 的自优化和管理功能,在 0.5 版本中,Amoro 实现了 Iceberg Restful Catalog 接口,意味着原生 Iceberg 用户可以使用 Iceberg 提供的 Restful Catalog 访问 Amoro,用户可以在这里感受到类似于 Hive 和 HMS 天然集成的特性,未来 AMS 还会基于 Iceberg Metrics 扩展更多有价值的度量指标,这里必须要感谢 Iceberg 社区对用户需求的洞察和高瞻远瞩。
第二,Amoro 支持对接既有的 Metastore,比如 HMS,AWS Glue。我们观察到社区里很多用户使用了 HMS,可能还基于 HMS 做了授权鉴权,Amoro 可以通过 external catalog 的功能将 HMS 作为扩展的元数据存储,同时还能提供自优化,快照管理等特性。用户可以快速将 Amoro 应用于现有的系统,在社区实践中,曾出现过第一天测试,第二天上线的案例。
场景与价值
A 的中央部分是两点一横,对应 Amoro 的应用场景。
一点:湖原生数仓
当我们使用数据库,或者如 TeraData、GP 一类的 MPP 数仓,大家习惯于把他们当做一个黑盒,用标准的 SQL 或工具来使用数据,当我们把技术栈切到数据湖,会发现大家似乎习惯于把工作拆成一个个模块:数据加工,ETL 用 Spark/Flink,数据分析用 Trino、Presto 和 Impala,相比传统数仓,数据湖开放的特性和生态给业务带来了超大规模的扩展性、伸缩性和相对可控的成本,但也丧失了传统数据库和数仓开箱即用的特性。
对此我们的工程师可能会想很多办法,比如自己开发一个定时调度的数据优化平台,或者把数据 layout 优化的工作直接丢给用户,这个谁用谁知道,把原先数据库和数仓内部极其复杂的数据合并和优化规则交给业务平台去做,这基本是一项不可能做好的事情,尤其当你想用新的数据湖 format 统一实时和离线数仓,数据的优化规则可能需要翻天覆地的变化。
在我们和业务共创的过程中,我们看到了大量这样的需求:业务希望用一套数据湖技术栈,同时做离线数仓和实时数仓,数据可能实时摄取,也可能离线写入。既想要数据湖的低成本,高弹性,可以使用成套的数据湖工具(大数据平台),也可以有传统数据库和数仓黑盒使用的体验,业务只管使用数据:
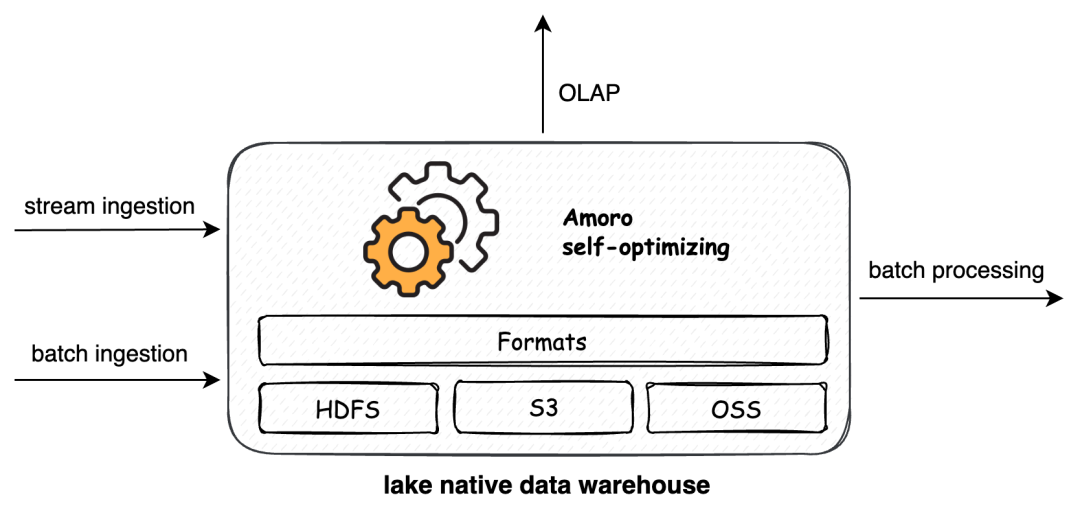
我们将这种场景命名为湖原生数仓,湖是新型的数据湖 format,能够为业务带来 ACID,流批统一等特性,数仓强调开箱即用,自管理和自优化的能力,我们希望通过 Amoro 结合数据湖 format 实现湖原生数仓的愿景。
湖原生数仓本质上是 Lakehouse(虽然这个概念足够通用,但不得不承认,当我跟另一位同学讲 Lakehouse 的时候,很难说他想到的东西和我一样) 在数仓方向上的精准抽象,当我们说湖仓一体时,绝大多数场景讲的就是湖原生数仓。
一横:流式 pipeline
对实时业务,过去大部分实践是从数据源到数仓定义一个独立的 ETL 任务,随着业务对数据时效性越来越重视,大家开始研究实时数仓和实时计算的体系化研发、数据分层、资产复用和数据治理。2018 年 Databricks 就提出用 Delta 架构实现流批架构的统一,即所谓的流批一体,而在流批一体之前,首先要做好流式的 pipeline,再将批的选择权交给用户:
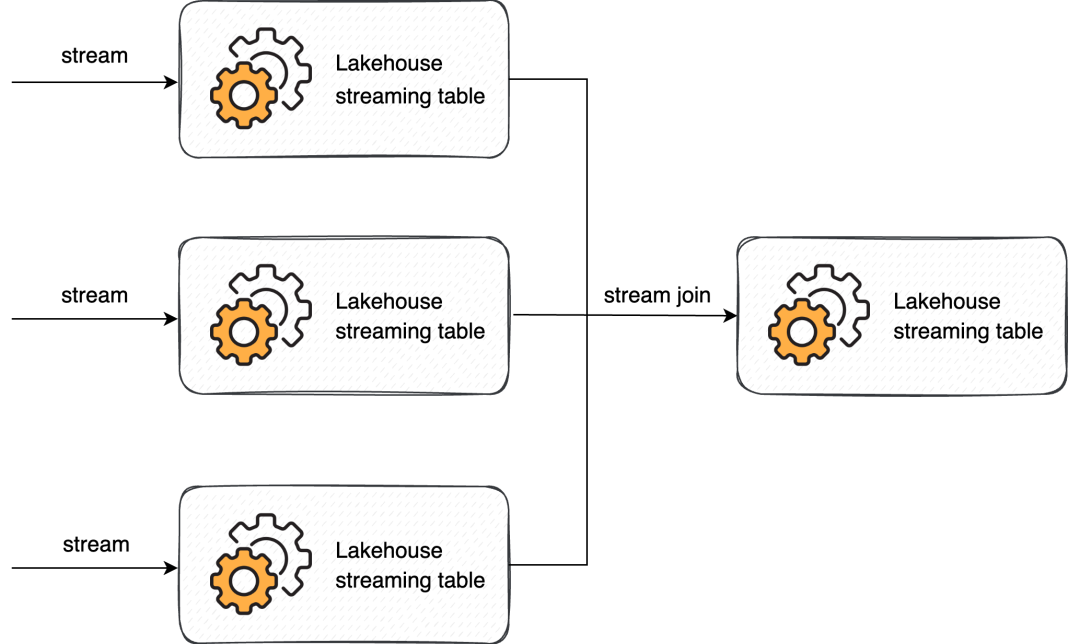
流式 pipeline 需要用的技术有 Incremental query、CDC、基于湖的维表 join,基于湖的多流 join等。CDC 和增量读是相对成熟的功能,但基于湖做多表关联,解决引擎大状态问题,这是个湖与引擎高度耦合的功能,我们认为整个行业在这块的成熟度还有所不足,尤其在超大规模数据的场景下,需要 case by case 地解决问题。
对流式 pipeline 的场景,Amoro 提供了一套 Mixed format,可以更好地应对 CDC,毫秒级 pipeline 的需求,同时在 Self-optimizing 和 Merge-on-read 方面提供了基于 bucket 的性能优化,其中 Mixed Hive 能够额外提供 Hive 原生读写的功能,感兴趣的同学可以参阅:
https://amoro.netease.com/docs/latest/formats-overview/
未来 Amoro 希望通过对接不同数据湖 format 来探索这个场景的更多可能性,比如目前社区已经在推进和 Paimon 的集成,我们有理由相信 Paimon 在流式场景下可以给用户带来更多惊喜。
另一点:云原生数仓
数据湖 format 技术在国内讨论更多的是 CDC,流批一体这样的场景,立项之初这也是 Amoro 主要关注的点。但熟悉 Iceberg 的同学可能知道,Iceberg 诞生的重要背景之一,是面向 AWS S3 构建数仓的需求,Hive 在对象存储之上有诸多不足,在 Iceberg 之上都有得到妥善解决,技术点这里不多做讨论。
云原生数仓可以认为是纯粹面向对象存储的数仓方案,业务往往会选择一个全新的技术栈,比如用 Iceberg 代替 Hive,用 AWS Glue 代替 HMS,而 Amoro 提供的 AMS 实现了 Iceberg 的 Restful catalog 接口;提供了数据自管理和优化的特性;提供了时效性、性能、成本的度量和管理功能,能够在云原生数仓的场景下作为 Iceberg 的最佳伴侣来使用。
定位和愿景
Amoro 是什么,这个答案既要回答立项的初心,也要代表项目长期的定位和愿景:
"Amoro is a Lakehouse management system built on open data lake formats. Working with compute engines including Flink, Spark, and Trino, Amoro brings pluggable and self-managed features for Lakehouse to provide out-of-the-box data warehouse experience, and helps data platforms or products easily build infra-decoupled, stream-and-batch-fused and lake-native architecture."
首先 Amoro 是湖仓管理系统,这里我们借鉴了数据库管理系统的叫法,可能很多同学乍一听会觉得管理系统会类似于实时计算、离线开发一类的工具平台,这里我稍稍做个澄清:工具的目标是帮助用户更高效、便利地执行某种流程,而Amoro 的目标是将一些流程向用户屏蔽,交给用户一个黑盒,他的定位更多是一个基础软件,所以 Amoro 的 MS 类似于 DBMS 中的 MS,我们经常讲一句话:build a box for lakehouse。
这里抛砖引玉一下,我们经常在数据库和传统数仓中看到一些面向 information_schema 的标准化指令,Amoro 希望可以做 Lakehouse 的 information_schema,后续我们会尝试带动社区推进这块功能的标准化。
其次 Amoro 不像数据库和传统数仓一样是个纯粹地黑盒,它开放的特性可以很好地契合由开源技术栈构建的各种大数据平台和产品,帮助这些平台快速上手 Iceberg 这类新型数据湖 format,体现湖原生数仓、湖仓一体的业务价值,所以它即可面向数仓用户,也可以面向平台开发者,在我们的社区实践中,后者的比例是占大头的。
03
活动预告
基础软件是现代数据栈发展的核心驱动力,而在大数据领域,开源又是基础软件发展的必要路径。过去多年来我们团队为公司研发了多项基础软件,有的因为关键业务发展不利而消亡,有些至今活跃在生产一线,我最大的感受是闭源软件,尤其那些自给自足而不是为 2B 而生的项目,无论多底层,很容易受制于组织架构和生产关系的割裂,或公司业态不够丰富,而无法在通用性和标准化上做到极致。
这也正是我们做开源的初衷,我们希望通过纯粹的开源精神,为我们的用户,为这个行业打磨一套在湖仓领域的基础软件,Make something different!
回顾过去一年,社区已有 20+ 个来自不同企业的开发者参与贡献,10+ 个生产用户案例。在社区生态上,也将持续建设,以更多的方式让用户了解参与 Amoro,包括但不限于项目的捐赠,放弃掌控权,成为一个多方共建的开源社区。
接下来做个预告,Amoro 即将发布 0.5 的新版本!社区也将组织一场试用和贡献活动,欢迎各位小伙伴关注、试用 Amoro 新发布的版本,有任何问题可以随时反馈社区,同时也欢迎更多的开发者能参与到 Amoro 的共建中来,让社区能更加丰富、更有趣!
Have fun!
END
看到这里 记得关注、点赞、转发 一键三连哦~

精彩回顾:
Arctic助力传媒实现低成本的大数据准实时计算
Arctic 自动优化湖仓原理解析
万字长文详解开源流式湖仓服务Arctic
从Delta 2.0开始聊聊我们需要怎样的数据湖
手把手教你使用 Arctic 自动优化 Apache Iceberg
关于 Amoro 的更多资讯可查看:
官网:https://amoro.netease.com/
文档:https://amoro.netease.com/docs/latest/
源码:https://github.com/NetEase/amoro
社群:后台回复【社群】添加小助手(或扫描下方二维码↓,邀你进群)

点击下方【阅读原文】可直接跳转 Amoro 官网
评论