
Kubernetes Informer 机制解析

Kubernetes 的控制器模式是其非常重要的一个设计模式,整个 Kubernetes 定义的资源对象以及其状态都保存在 etcd 数据库中,通过a piserver 对其进行增删改查,而各种各样的控制器需要从apiserver及时获取这些对象以及其当前定义的状态,然后将其应用到实际中,即将这些对象的实际状态调整为期望状态,让他们保持匹配。因此各种控制器需要和apiserver进行频繁交互,需要能够及时获取对象状态的变化,而如果简单的通过暴力轮询的话,会给apiserver造成很大的压力,且效率很低,因此,Kubernetes设计了Informer这个机制,用来作为控制器跟apiserver交互的桥梁,它主要有两方面的作用:
依赖Etcd的List&Watch机制,在本地维护了一份 所关心的API对象的缓存。Etcd的Watch机制能够使客户端及时获知这些对象的状态变化,然后更新本地缓存,这样就在客户端为这些API对象维护了一份和Etcd数据库中几乎一致的数据,然后控制器等客户端就可以直接访问缓存获取对象的信息,而不用去直接访问apiserver,这一方面显著提高了性能,另一方面则大大降低了对apiserver的访问压力;依赖Etcd的Watch机制,触发控制器等客户端注册到Informer中的事件方法。客户端可能会某些对象的某些事件感兴趣,当这些事件发生时,希望能够执行某些操作,比如通过apiserver新建了一个pod,那么kube-scheduler中的控制器收到了这个事件,然后将这个pod加入到其队列中,等待进行调度。
Kubernetes的各个组件本身就内置了非常多的控制器,而自定义的控制器也需要通过Informer跟apiserver进行交互,因此,Informer在Kubernetes中应用非常广泛,出镜率很高,本篇文章就重点分析下Informer的机制原理,以加深对其的理解。
使用方法
先来看看Informer是怎么用的,以Deployment控制器为例,来看下其使用Informer的相关代码:
1. 创建Informer工厂
# kubernetes/cmd/kube-controller-manager/app/controllermanager.go
sharedInformers := informers.NewSharedInformerFactory(versionedClient, ResyncPeriod(s)())
首先创建了一个SharedInformerFactory,这个结构主要有两个作用:一个是用来作为创建Informer的工厂,典型的工厂模式,在Kubernetes中这种设计模式也很常用;一个是共享Informer,所谓共享,就是多个Controller可以共用同一个Informer,因为不同的Controller可能对同一种API对象感兴趣,这样相同的API对象,缓存就只有一份,通知机制也只有一套,大大提高了效率,减少了资源浪费。
2. 创建对象Informer结构体
# kubernetes/cmd/kube-controller-manager/app/apps.go
dc, err := deployment.NewDeploymentController(
ctx.InformerFactory.Apps().V1().Deployments(),
ctx.InformerFactory.Apps().V1().ReplicaSets(),
ctx.InformerFactory.Core().V1().Pods(),
ctx.ClientBuilder.ClientOrDie("deployment-controller"),
)
使用InformerFactory创建出对应版本的对象的Informer结构体,如Deployment对象对应的就是deploymentInformer结构体,该结构体实现了两个方法:Informer()和Lister(),前者用来构建出最终的Informer,即我们本篇文章的重点:SharedIndexInformer,后者用来获取创建出来的Informer的缓存接口:Indexer,该接口可以用来查询缓存的数据。Deployment Controller关心的API对象为Deployment, ReplicaSet, Pod,分别为这三种API对象创建了Informer。
3. 注册事件方法
# kubernetes/pkg/controller/deployment/deployment_controller.go
dInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: dc.addDeployment,
UpdateFunc: dc.updateDeployment,
// This will enter the sync loop and no-op, because the deployment has been deleted from the store.
DeleteFunc: dc.deleteDeployment,
})
rsInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: dc.addReplicaSet,
UpdateFunc: dc.updateReplicaSet,
DeleteFunc: dc.deleteReplicaSet,
})
podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
DeleteFunc: dc.deletePod,
})
dc.dLister = dInformer.Lister()
dc.rsLister = rsInformer.Lister()
dc.podLister = podInformer.Lister()
这里,首先调用Infomer()创建出来SharedIndexInformer,然后向其中注册事件方法,这样当有对应的事件发生时,就会触发这里注册的方法去做相应的事情。其次调用Lister()获取到缓存接口,就可以通过它来查询Informer中缓存的数据了,而且Informer中缓存的数据,是可以有索引的,这样可以加快查询的速度。
4. 启动Informer
# kubernetes/cmd/kube-controller-manager/app/controllermanager.go
controllerContext.InformerFactory.Start(controllerContext.Stop)
这里InformerFactory的启动,会遍历Factory中创建的所有Informer,依次将其启动。
机制解析
Informer的实现都是在client-go这个库中,通过上述的工厂方法,其实最终创建出来的是一个叫做SharedIndexInformer的结构体:
# k8s.io/client-go/tools/cache/shared_informer.go
type sharedIndexInformer struct {
indexer Indexer
controller Controller
processor *sharedProcessor
cacheMutationDetector MutationDetector
listerWatcher ListerWatcher
......
}
func NewSharedIndexInformer(lw ListerWatcher, exampleObject runtime.Object, defaultEventHandlerResyncPeriod time.Duration, indexers Indexers) SharedIndexInformer {
realClock := &clock.RealClock{}
sharedIndexInformer := &sharedIndexInformer{
processor: &sharedProcessor{clock: realClock},
indexer: NewIndexer(DeletionHandlingMetaNamespaceKeyFunc, indexers),
listerWatcher: lw,
objectType: exampleObject,
resyncCheckPeriod: defaultEventHandlerResyncPeriod,
defaultEventHandlerResyncPeriod: defaultEventHandlerResyncPeriod,
cacheMutationDetector: NewCacheMutationDetector(fmt.Sprintf("%T", exampleObject)),
clock: realClock,
}
return sharedIndexInformer
}
可以看到,在创建SharedIndexInformer时,就创建出了processor, indexer等结构,而在Informer启动时,还创建出了controller, fifo queue, reflector等结构,这些结构之间的关系如下图所示:
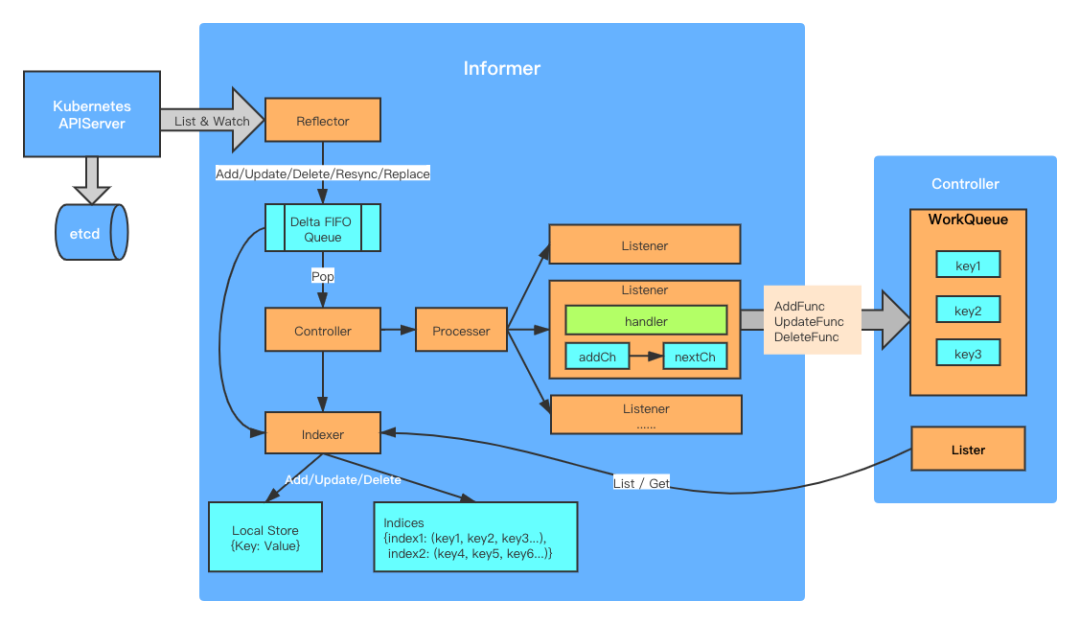
Reflector
Reflector的作用,就是通过List&Watch的方式,从apiserver获取到感兴趣的对象以及其状态,然后将其放到一个称为”Delta”的先进先出队列中。
所谓的Delta FIFO Queue,就是队列中的元素除了对象本身外,还有针对该对象的事件类型:
type Delta struct {
Type DeltaType
Object interface{}
}
目前有5种Type: Added, Updated, Deleted, Replaced, Resync,所以,针对同一个对象,可能有多个Delta元素在队列中,表示对该对象做了不同的操作,比如短时间内,多次对某一个对象进行了更新操作,那么就会有多个Updated类型的Delta放入到队列中。后续队列的消费者,可以根据这些Delta的类型,来回调注册到Informer中的事件方法。
而所谓的List&Watch,就是先调用该API对象的List接口,获取到对象列表,将它们添加到队列中,Delta元素类型为Replaced,然后再调用Watch接口,持续监听该API对象的状态变化事件,将这些事件按照不同的事件类型,组成对应的Delta类型,添加到队列中,Delta元素类型有Added, Updated, Deleted三种。
此外,Informer还会周期性的发送Resync类型的Delta元素到队列中,目的是为了周期性的触发注册到Informer中的事件方法UpdateFunc,保证对象的期望状态和实际状态一致,该周期是由一个叫做resyncPeriod的参数决定的,在向Informer中添加EventHandler时,可以指定该参数,若为0的话,则关闭该功能。需要注意的是,Resync类型的Delta元素中的对象,是通过Indexer从缓存中获取到的,而不是直接从apiserver中拿的,即这里resync的,其实是”缓存”的对象的期望状态和实际状态的一致性。
根据以上Reflector的机制,可以澄清一下Kubernetes中关于控制器模式的一个常见误区,即以为控制器是不断轮询api,不停地调用List和Get,获取到对象的期望状态,其实在文章开头就说过了,这样做会给apiserver造成很大的压力,效率很低,所以才设计了Informer,依赖Etcd的Watch机制,通过事件来获知对象变化状态,建立本地缓存。即使在Informer中,也没有周期性的调用对象的List接口,正常情况下,List&Watch只会执行一次,即先执行List把数据拉过来,放入队列中,后续就进入Watch阶段。
那什么时候才会再执行List呢?其实就是异常的时候,在List或者Watch的过程中,如果有异常,比如apiserver重启了,那么Reflector就开始周期性的执行List&Watch,直到再次正常进入Watch阶段。为了在异常时段,不给apiserver造成压力,这个周期是一个称为backoff的可变的时间间隔,默认是一个指数型的间隔,即越往后重试的间隔越长,到一定时间又会重置回一开始的频率。而且,为了让不同的apiserver能够均匀负载这些Watch请求,客户端会主动断开跟apiserver的连接,这个超时时间为60秒,然后重新发起Watch请求。此外,在控制器重启过程中,也会再次执行List,所以会观察到之前已经创建好的API对象,又重新触发了一遍AddFunc方法。
从以上这些点,可以看出来,Kubernetes在性能和稳定性的提升上,还是下了很多功夫的。
Controller
这里Controller的作用是通过轮询不断从队列中取出Delta元素,根据元素的类型,一方面通过Indexer更新本地的缓存,一方面调用Processor来触发注册到Informer的事件方法:
# k8s.io/client-go/tools/cache/controller.go
func (c *controller) processLoop() {
for {
obj, err := c.config.Queue.Pop(PopProcessFunc(c.config.Process))
}
}
这里的c.config.Process是定义在shared_informer.go中的HandleDeltas()方法:
# k8s.io/client-go/tools/cache/shared_informer.go
func (s *sharedIndexInformer) HandleDeltas(obj interface{}) error {
s.blockDeltas.Lock()
defer s.blockDeltas.Unlock()
// from oldest to newest
for _, d := range obj.(Deltas) {
switch d.Type {
case Sync, Replaced, Added, Updated:
s.cacheMutationDetector.AddObject(d.Object)
if old, exists, err := s.indexer.Get(d.Object); err == nil && exists {
if err := s.indexer.Update(d.Object); err != nil {
return err
}
isSync := false
switch {
case d.Type == Sync:
// Sync events are only propagated to listeners that requested resync
isSync = true
case d.Type == Replaced:
if accessor, err := meta.Accessor(d.Object); err == nil {
if oldAccessor, err := meta.Accessor(old); err == nil {
// Replaced events that didn't change resourceVersion are treated as resync events
// and only propagated to listeners that requested resync
isSync = accessor.GetResourceVersion() == oldAccessor.GetResourceVersion()
}
}
}
s.processor.distribute(updateNotification{oldObj: old, newObj: d.Object}, isSync)
} else {
if err := s.indexer.Add(d.Object); err != nil {
return err
}
s.processor.distribute(addNotification{newObj: d.Object}, false)
}
case Deleted:
if err := s.indexer.Delete(d.Object); err != nil {
return err
}
s.processor.distribute(deleteNotification{oldObj: d.Object}, false)
}
}
return nil
}
Processer & Listener
Processer和Listener则是触发事件方法的机制,在创建Informer时,会创建一个Processer,而在向Informer中通过调用AddEventHandler()注册事件方法时,会为每一个Handler生成一个Listener,然后将该Lisener中添加到Processer中,每一个Listener中有两个channel:addCh和nextCh。Listener通过select监听在这两个channel上,当Controller从队列中取出新的元素时,会调用processer来给它的listener发送“通知”,这个“通知”就是向addCh中添加一个元素,即add(),然后一个goroutine就会将这个元素从addCh转移到nextCh,即pop(),从而触发另一个goroutine执行注册的事件方法,即run()。
# k8s.io/client-go/tools/cache/shared_informer.go
func (p *sharedProcessor) distribute(obj interface{}, sync bool) {
p.listenersLock.RLock()
defer p.listenersLock.RUnlock()
if sync {
for _, listener := range p.syncingListeners {
listener.add(obj)
}
} else {
for _, listener := range p.listeners {
listener.add(obj)
}
}
}
func (p *processorListener) add(notification interface{}) {
p.addCh <- notification
}
func (p *processorListener) pop() {
defer utilruntime.HandleCrash()
defer close(p.nextCh) // Tell .run() to stop
var nextCh chan<- interface{}
var notification interface{}
for {
select {
case nextCh <- notification:
// Notification dispatched
var ok bool
notification, ok = p.pendingNotifications.ReadOne()
if !ok { // Nothing to pop
nextCh = nil // Disable this select case
}
case notificationToAdd, ok := <-p.addCh:
if !ok {
return
}
if notification == nil { // No notification to pop (and pendingNotifications is empty)
// Optimize the case - skip adding to pendingNotifications
notification = notificationToAdd
nextCh = p.nextCh
} else { // There is already a notification waiting to be dispatched
p.pendingNotifications.WriteOne(notificationToAdd)
}
}
}
}
func (p *processorListener) run() {
// this call blocks until the channel is closed. When a panic happens during the notification
// we will catch it, **the offending item will be skipped!**, and after a short delay (one second)
// the next notification will be attempted. This is usually better than the alternative of never
// delivering again.
stopCh := make(chan struct{})
wait.Until(func() {
for next := range p.nextCh {
switch notification := next.(type) {
case updateNotification:
p.handler.OnUpdate(notification.oldObj, notification.newObj)
case addNotification:
p.handler.OnAdd(notification.newObj)
case deleteNotification:
p.handler.OnDelete(notification.oldObj)
default:
utilruntime.HandleError(fmt.Errorf("unrecognized notification: %T", next))
}
}
// the only way to get here is if the p.nextCh is empty and closed
close(stopCh)
}, 1*time.Second, stopCh)
}
Indexer
Indexer是对缓存进行增删查改的接口,缓存本质上就是用map构建的key:value键值对,都存在items这个map中,key为<namespace>/<name>:
type threadSafeMap struct {
lock sync.RWMutex
items map[string]interface{}
// indexers maps a name to an IndexFunc
indexers Indexers
// indices maps a name to an Index
indices Indices
}
而为了加速查询,还可以选择性的给这些缓存添加索引,索引存储在indecies中,所谓索引,就是在向缓存中添加记录时,就将其key添加到索引结构中,在查找时,可以根据索引条件,快速查找到指定的key记录,比如默认有个索引是按照namespace进行索引,可以根据快速找出属于某个namespace的某种对象,而不用去遍历所有的缓存。
Indexer对外提供了Replace(), Resync(), Add(), Update(), Delete(), List(), Get(), GetByKey(), ByIndex()等接口。
总结
本篇对 Kubernetes Informer的使用方法和实现原理,进行了深入分析,整体上看,Informer的设计是相当不错的,基于事件机制,一方面构建本地缓存,一方面触发事件方法,使得控制器能够快速响应和快速获取数据,此外,还有诸如共享 Informer、resync、index、watch timeout 等机制,使得 Informer 更加高效和稳定,有了 Informer,控制器模式可以说是如虎添翼。
最后,其实有一个地方还没有弄明白,就是 resync 机制是维持的缓存和实际状态的一致性,但是 etcd 数据库中的对象的状态,和缓存中的对象状态,如果只依靠 Watch 事件机制的话,能否保证一致性,如果因为某个原因,导致某次事件没有更新到缓存中,那后续这个对象如果没有发生变化的话,就不会有事件再发出来了,而 List 在正常情况下,又只 List 一次,这样缓存中的数据就跟数据库中的数据不一致了,就可能会出问题,找了半天没找到针对这种情况的处理,不知道是别有洞天,我没发现,还是这真的是个问题,只是没人遇到过。
原文链接:https://hackerain.me/2020/12/11/kubernetes/kube-clientgo-informer.html
K8S 进阶训练营

 点击屏末 | 阅读原文 | 即刻学习
点击屏末 | 阅读原文 | 即刻学习