
这个队列的思路真的好,现在它是我简历上的亮点了。
往期热门文章:


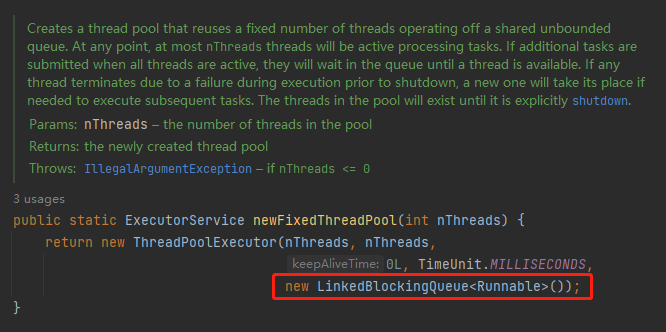
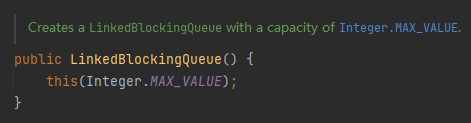
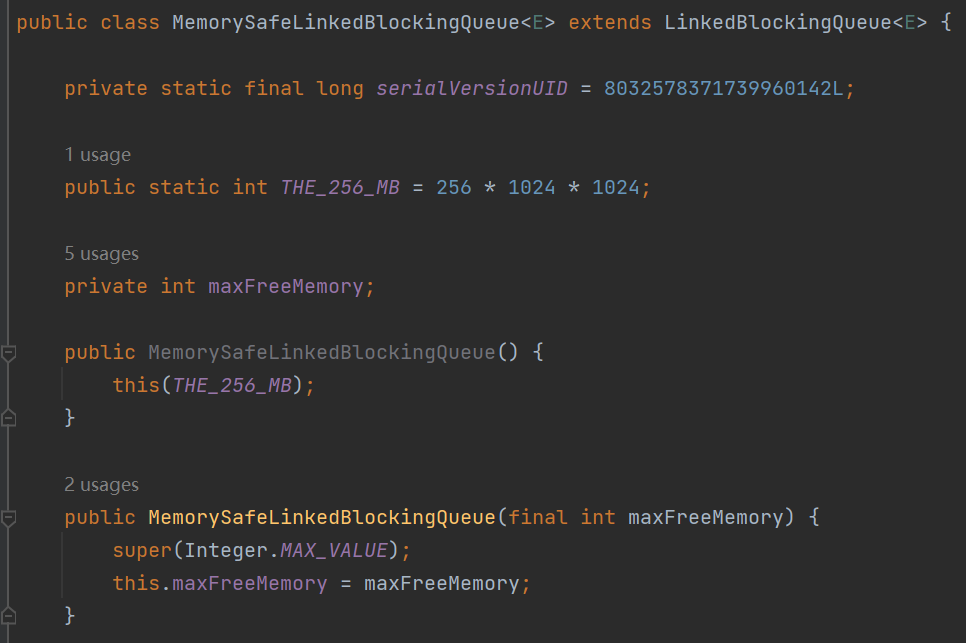
MemorySafeLBQ
https://github.com/apache/dubbo/pull/10021
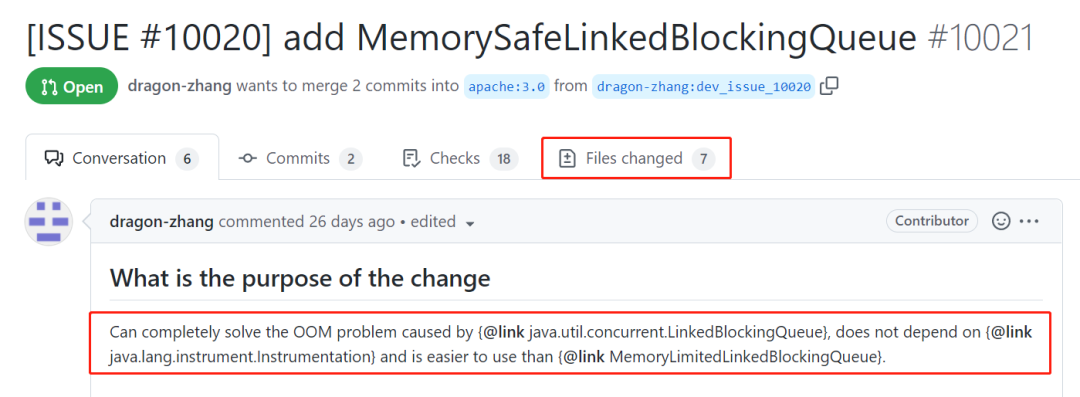
可以完全解决因为 LinkedBlockingQueue 造成的 OOM 问题,而且不依赖 instrumentation,比 MemoryLimitedLinkedBlockingQueue 更好用。
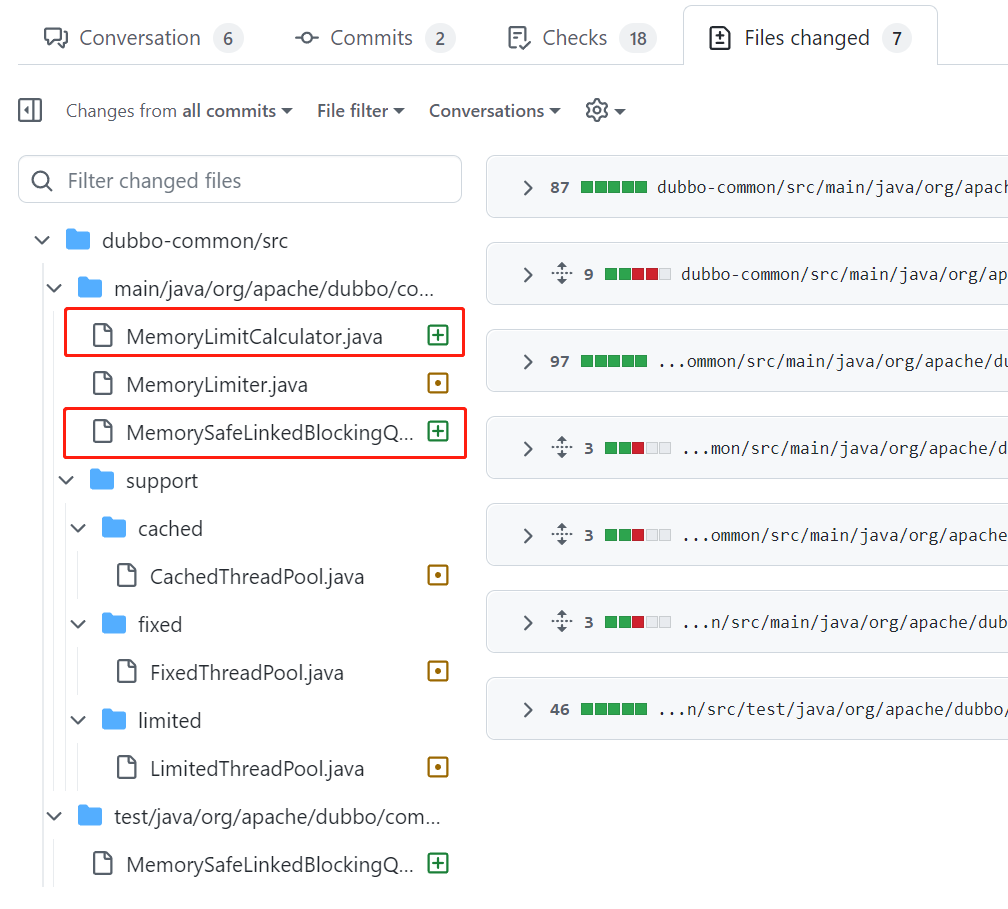

https://github.com/apache/dubbo/pull/9722
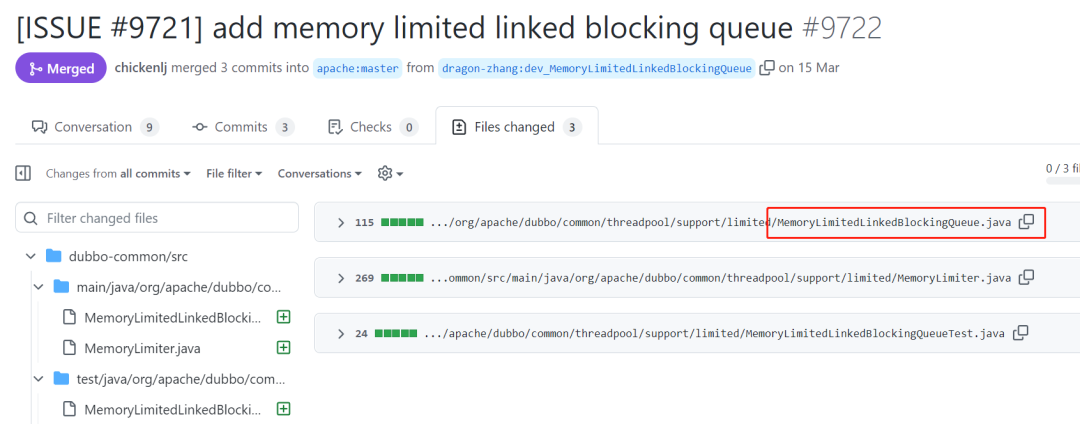

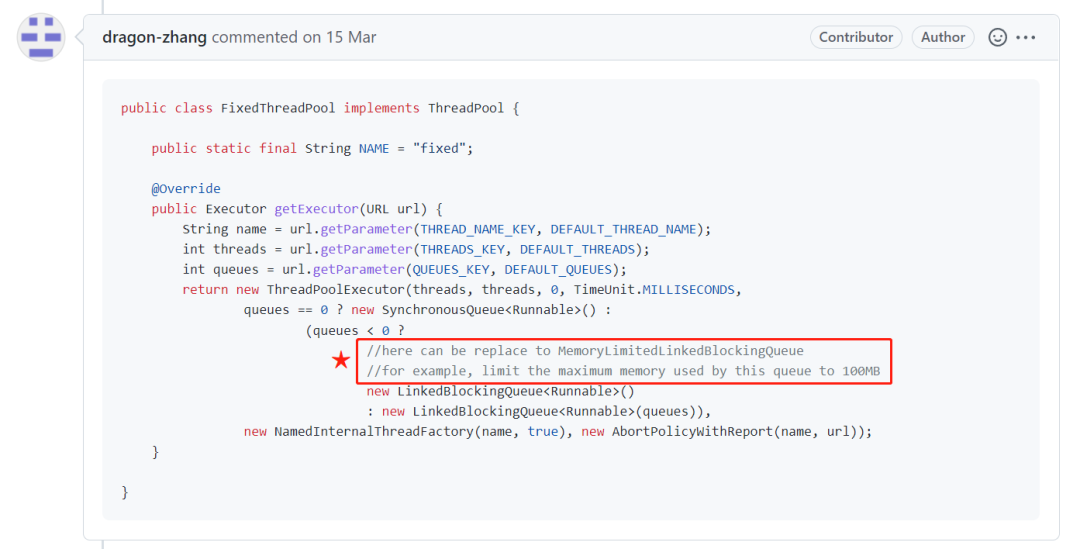
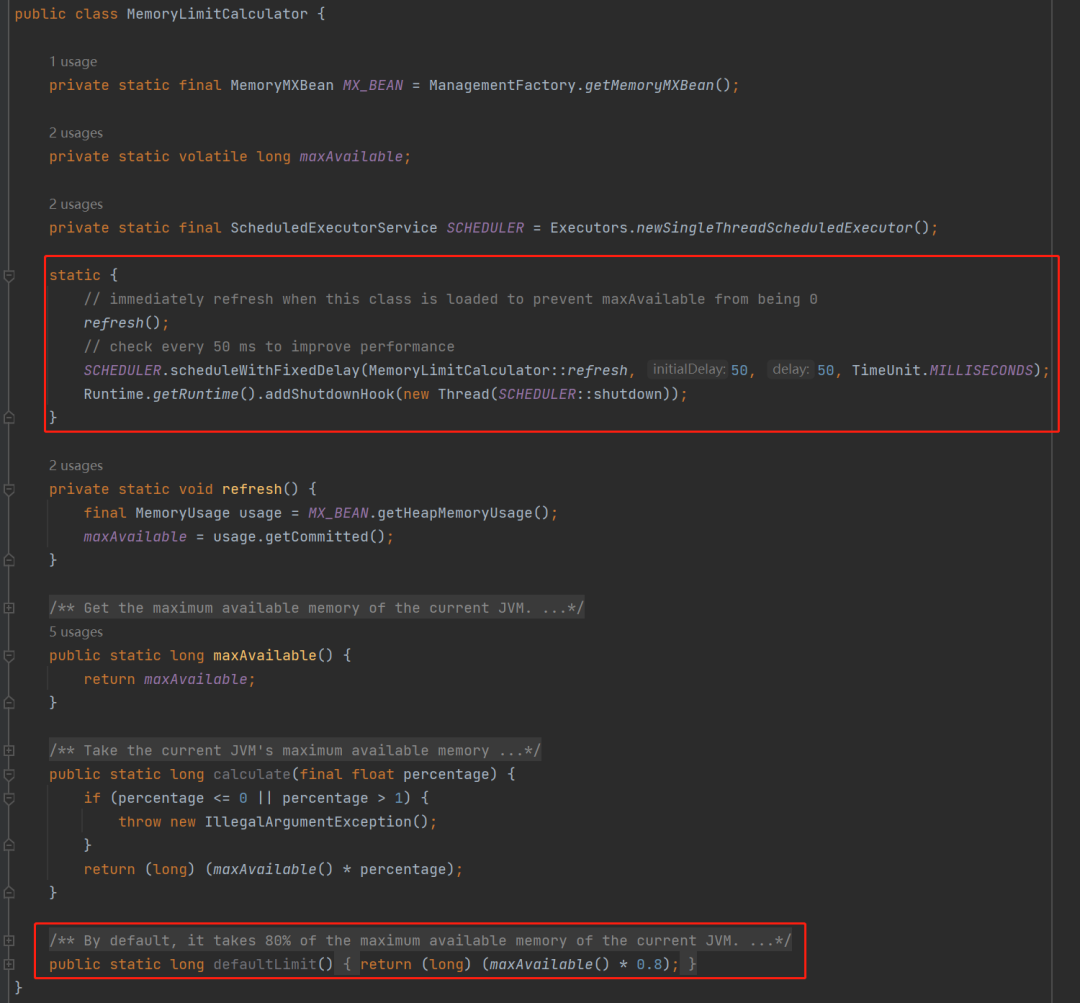
MemoryLimitedLBQ 的实现原理是什么? MemorySafeLBQ 的实现原理是什么? MemorySafeLBQ 为什么比 MemoryLimitedLBQ 更好用?
MemoryLimitedLBQ
https://github.com/apache/dubbo/pull/9722/files
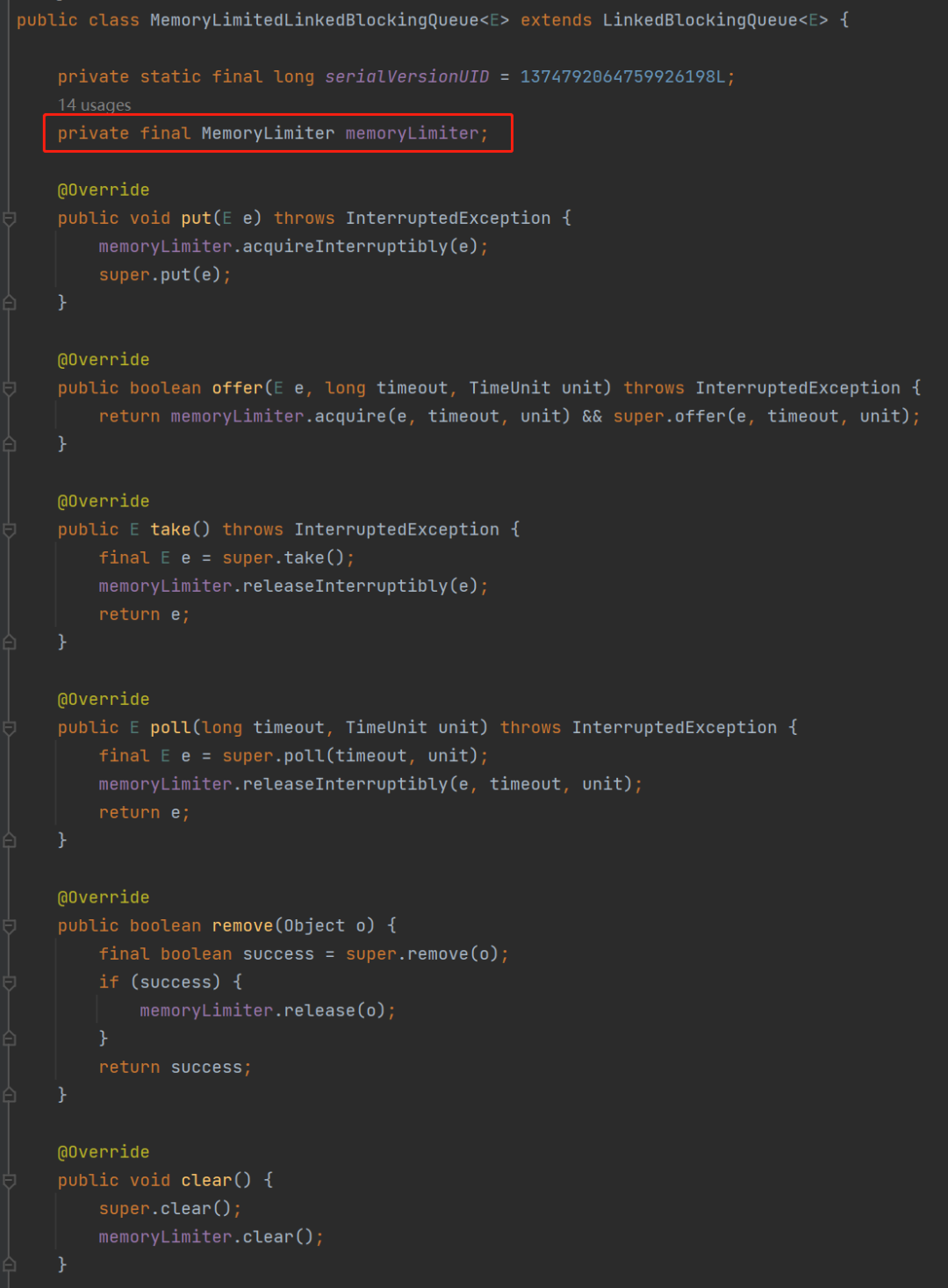
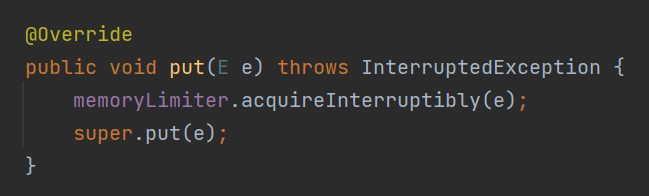
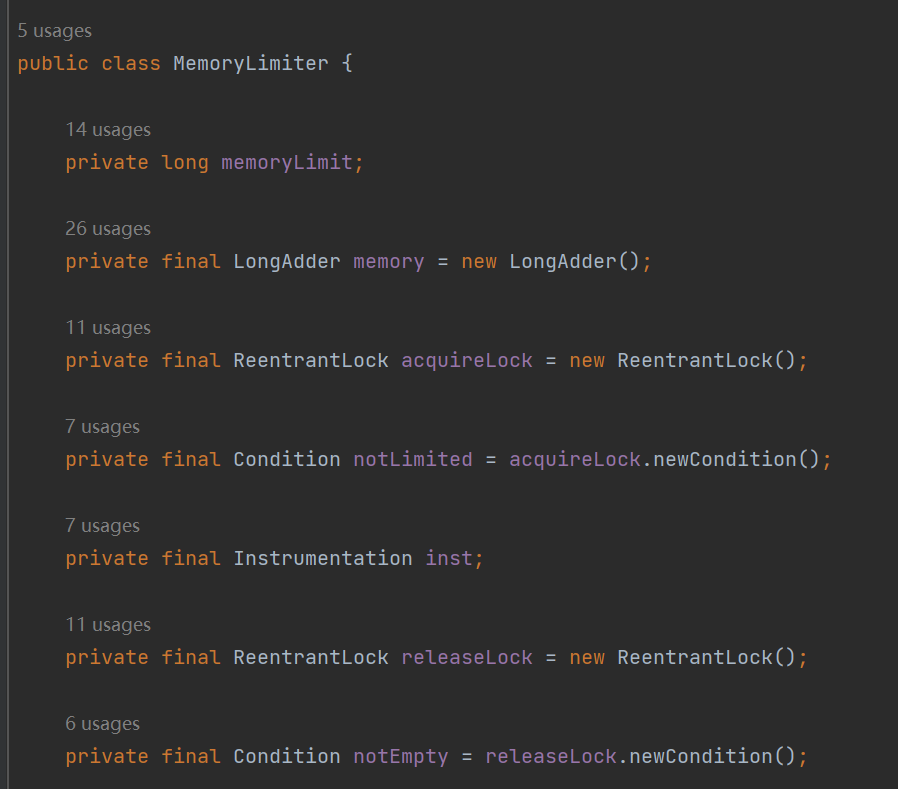
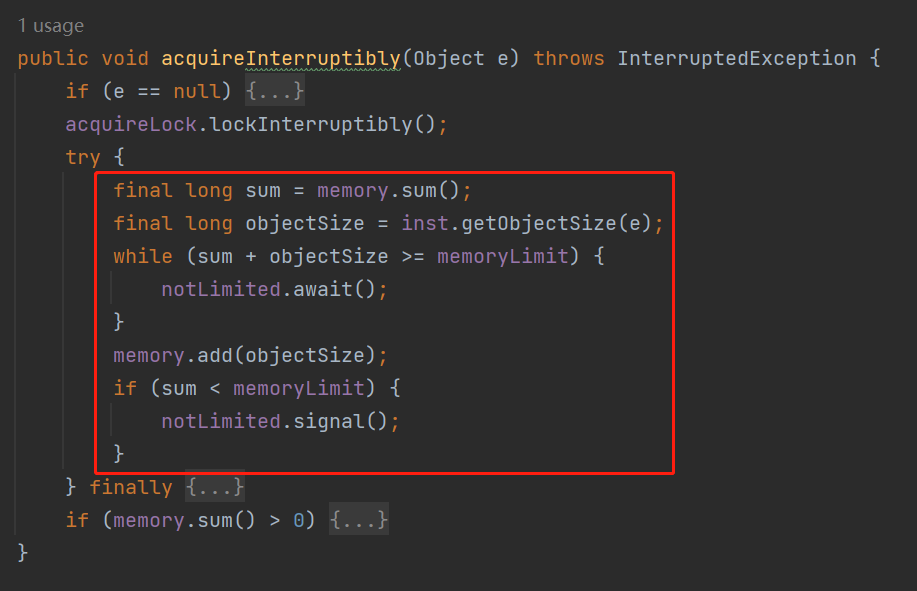
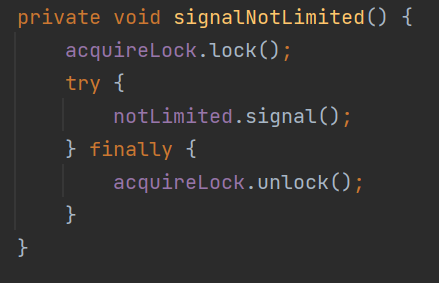
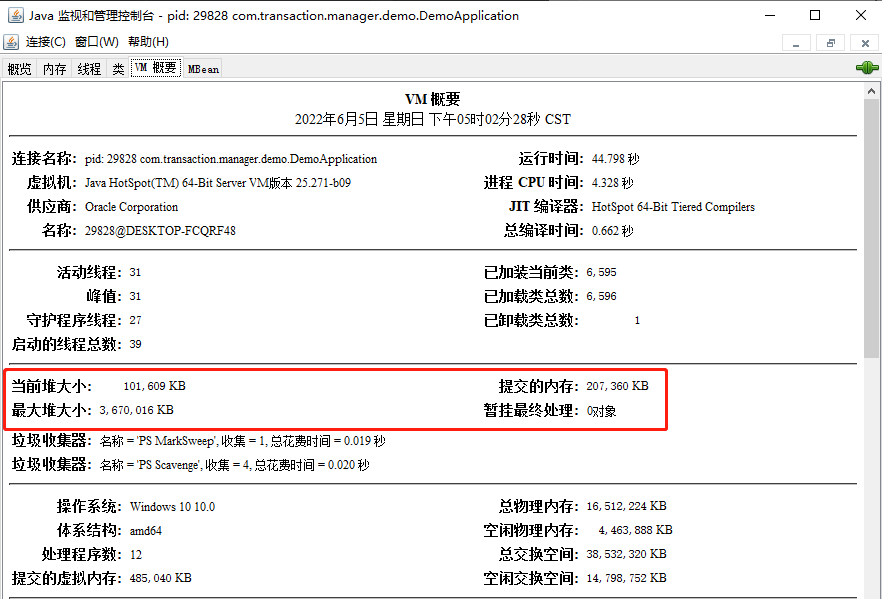
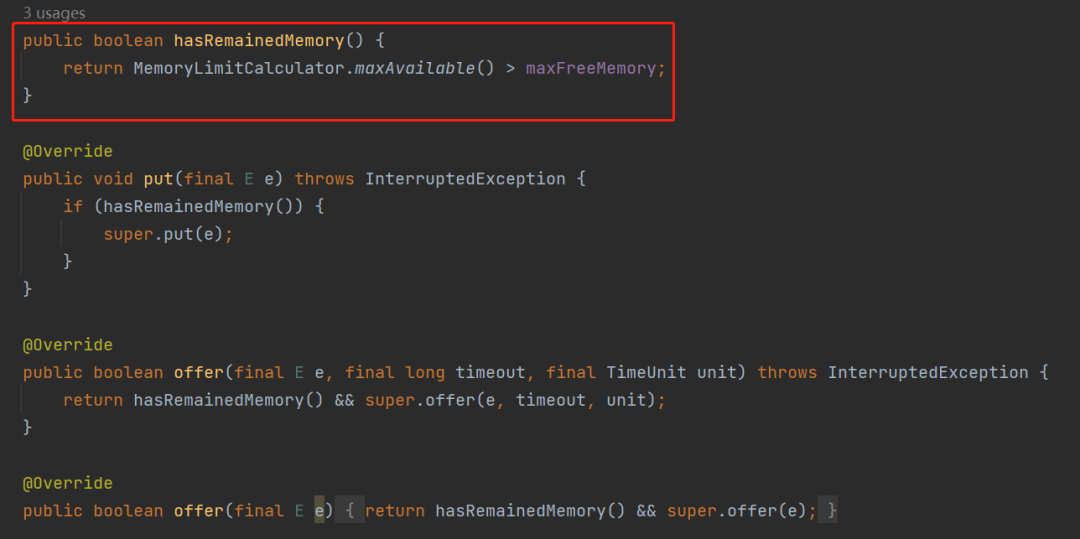
memoryLimit 就是表示这个队列最大所能容纳的大小。 memory 是 LongAdder 类型,表示的是当前已经使用的大小。 acquireLock、notLimited、releaseLock、notEmpty 是锁相关的参数,从名字上可以知道,往队列里面放元素和释放队列里面的元素都需要获取对应的锁。 inst 这个参数是 Instrumentation 类型的。

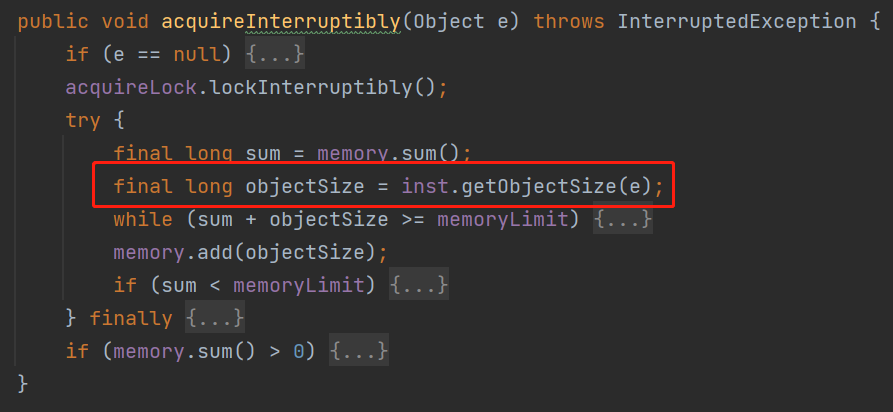
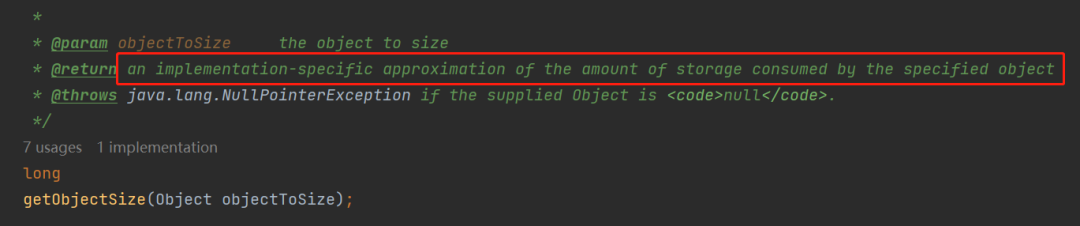
an implementation-specific approximation of the amount of storage consumed by the specified object

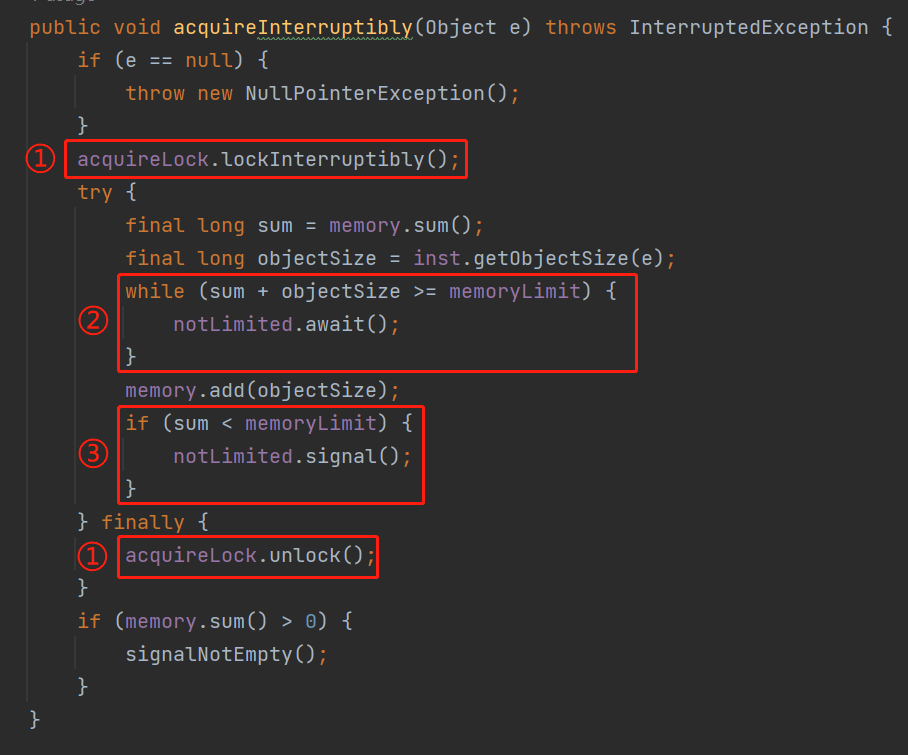
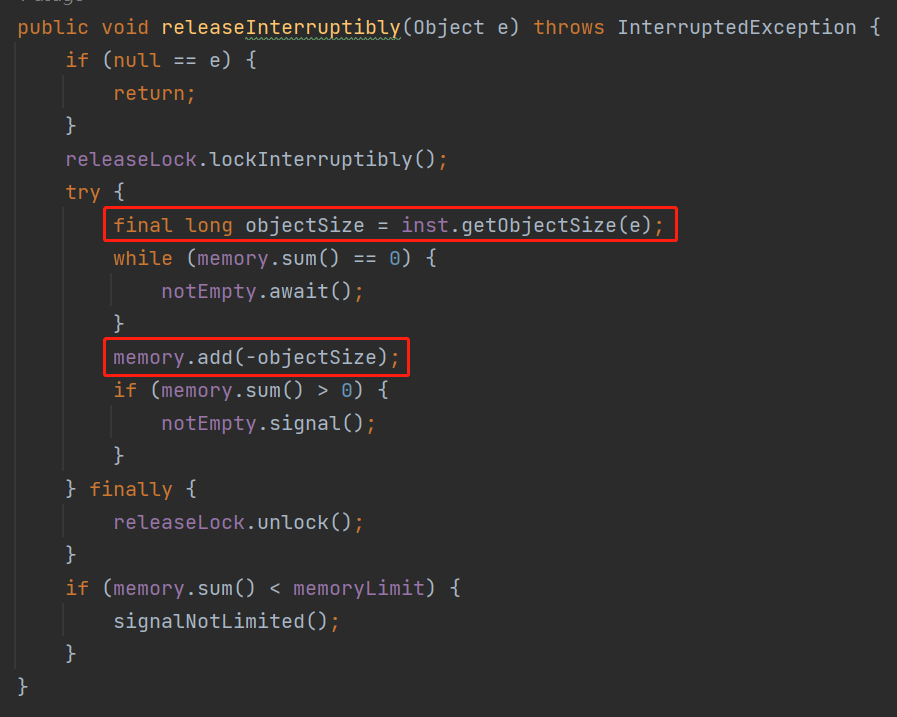

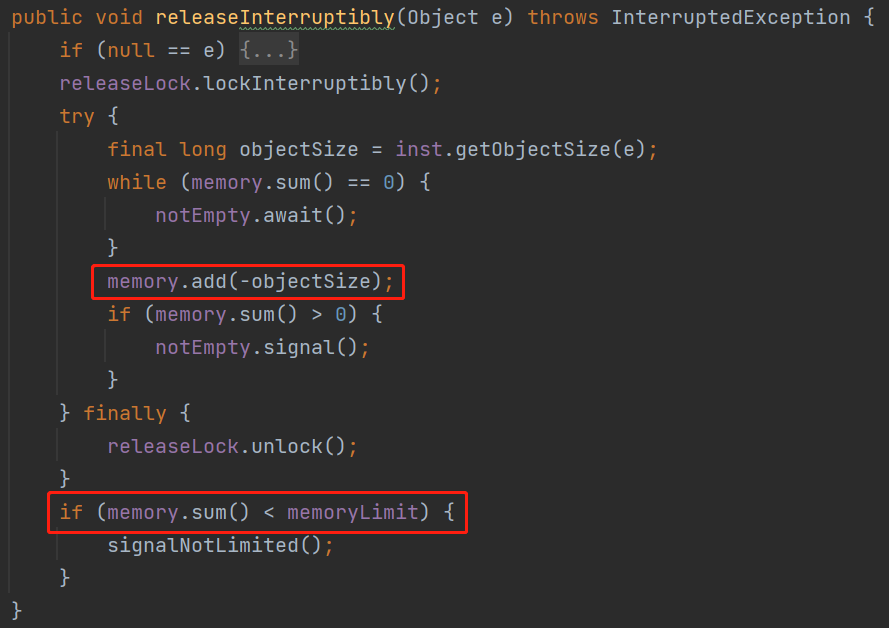
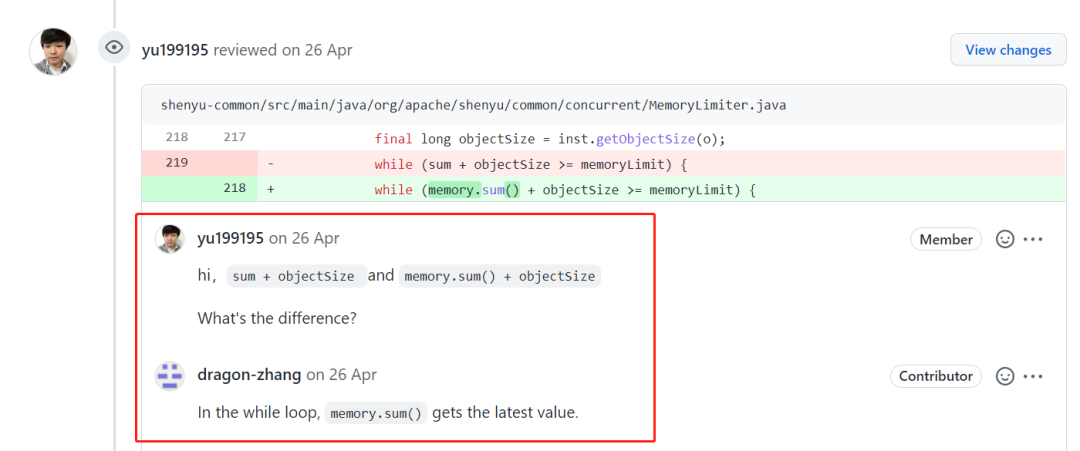
while (sum + objectSize >= memoryLimit) {
notLimited.await();
}

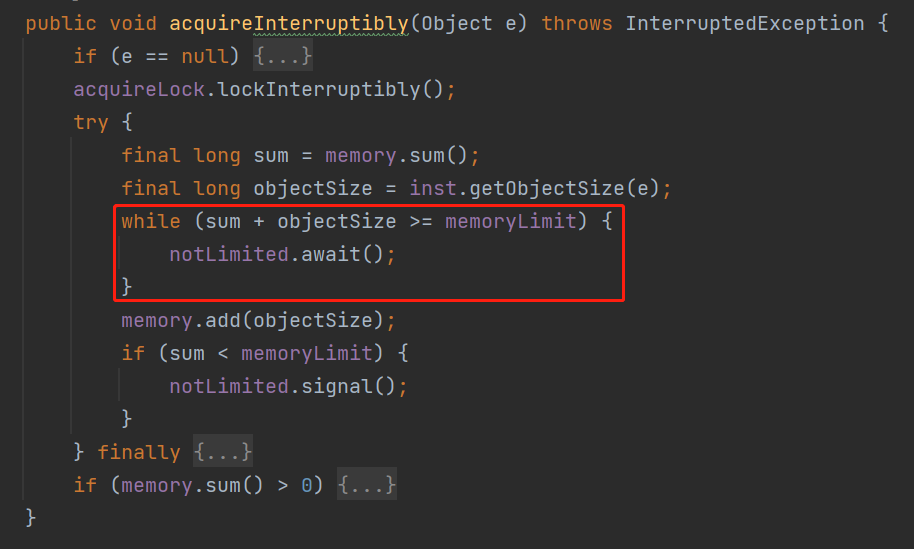
while (memory.sum() + objectSize >= memoryLimit) {
notLimited.await();
}
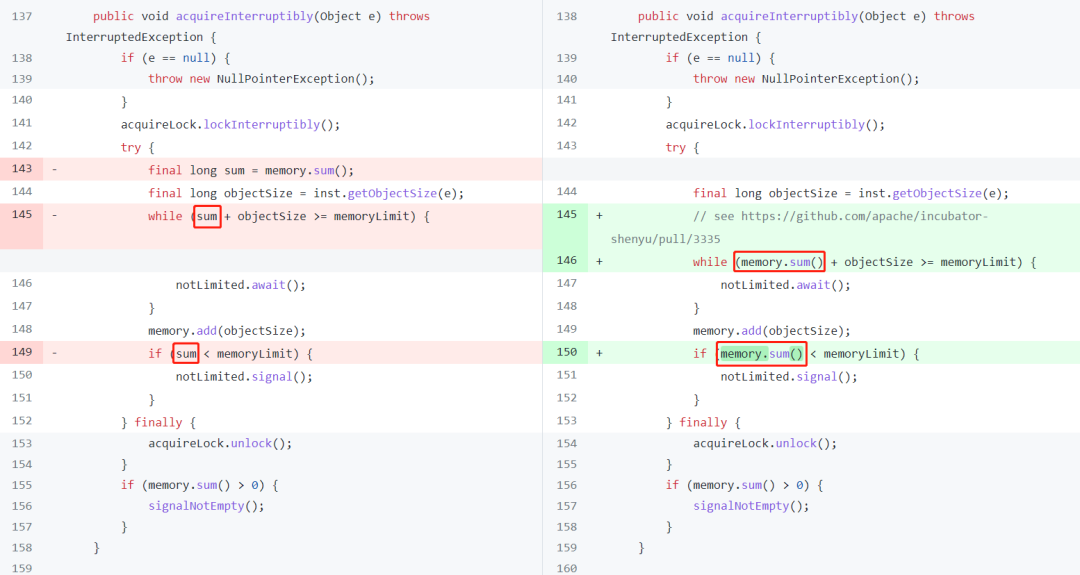
https://github.com/apache/incubator-shenyu/pull/3335

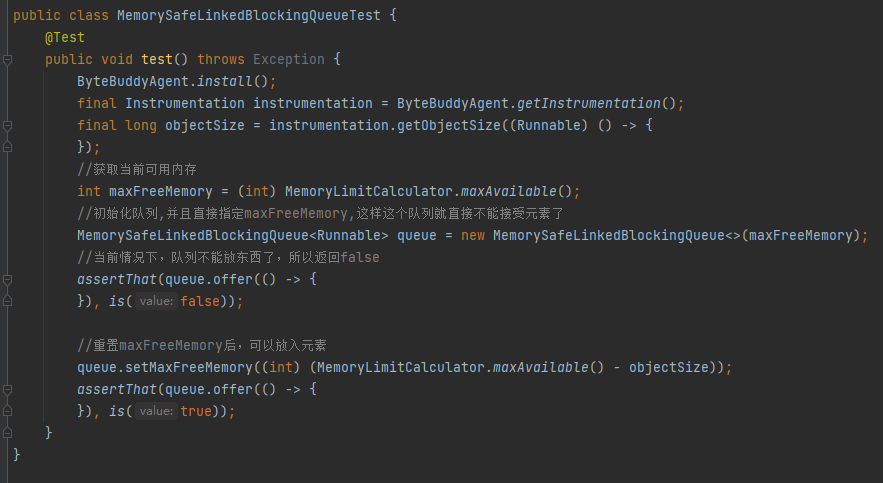
MemorySafeLBQ
https://github.com/apache/dubbo/pull/10021/files

它是你的了

往期热门文章:
2、超越 Xshell!号称下一代 Terminal 终端神器,用完爱不释手!
8、我怀疑这是 IDEA 的 BUG,但是我翻遍全网没找到证据!
9、Spring MVC 中的 Controller 是线程安全的吗?
10、Gitee 倒下了???
评论