
如何通俗的理解面向对象编程
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自:磐创AI
面向对象编程或OOP对于初学者来说可能是一个很难理解的概念。这主要是因为很多地方都没有正确的解释。通常很多书籍都是从解释OOP开始,讨论三大术语:封装、继承和多态性。但是当这本书能够解释这些话题的时候,任何一个刚刚开始的人都会感到失落。
所以,我想让程序员、数据科学家和蟒蛇爱好者们更容易理解这个概念。我打算这样做的方法是去掉所有的行话,并通过一些例子。我将从解释类和对象开始。然后我将解释为什么类在各种情况下都很重要,以及它们是如何解决一些基本问题的。这样,读者也能在帖子末尾理解这三大术语。
在这个名为Python Shorts的系列文章中,我将解释Python提供的一些简单但非常有用的构造、一些基本技巧以及我在数据科学工作中经常遇到的一些用例。
这篇文章是关于解释OOP的外行方式。
简单地说,Python中的一切都是对象,类是对象的蓝图。所以当我们写下:
a = 2
b = "Hello!"
我们正在创建一个int类的对象a,该对象的值为2,str类的对象b的值为“Hello!”. 当我们在默认情况下用两个引号来提供字符串。
除此之外,我们中的许多人最终都会在没有意识到的情况下使用类和对象。例如,当你使用任何scikit-learn模型时,实际上是在使用一个类。
clf = RandomForestClassifier()
clf.fit(X,y)
这里的分类器clf是一个对象,fit是一个在RandomForestClassifier类中定义的方法
因此,我们在使用Python时经常使用它们。但为什么呢。类是怎么回事?我可以用函数做同样的事情吗?
是的,你可以。但是与函数相比,类确实为你提供了很多功能。举个例子,str类有很多为对象定义的函数,我们只需按tab键就可以访问这些函数。人们也可以编写所有这些函数,但是那样的话,只按tab键就不能使用它们了。
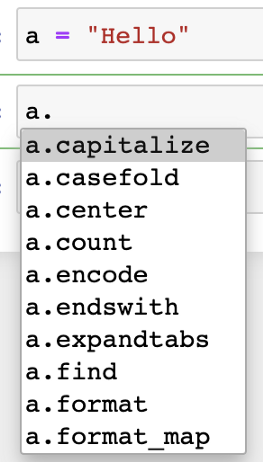
类的这个属性称为封装。从Wikipedia来看,封装是指将数据与操作该数据的方法捆绑在一起,或者限制对对象某些组件的直接访问。
所以这里str类绑定了数据(“Hello!)以及所有对我们的数据进行操作的方法。我会在帖子的最后解释声明的第二部分。同样,RandomForestClassifier 类将所有的方法(fit、predict等)捆绑在一起
除此之外,类的使用还可以帮助我们使代码更加模块化和易于维护。假设我们要创建一个像Scikit-Learn这样的库。我们需要创建许多模型,每个模型都有一个fit和predict方法。如果不使用类,我们将为每个不同的模型提供许多函数,例如:
RFCFit
RFCPredict
SVCFit
SVCPredict
LRFit
LRPredict
and so on.
这种代码结构只是一场噩梦,因此Scikit Learn将每个模型定义为一个具有fit和predict方法的类。
所以,现在我们了解了为什么要使用类,它们是如何如此重要,我们如何真正开始使用它们?所以,创建一个类非常简单。下面是你将要编写的任何类的样板代码:
class myClass:
def __init__(self, a, b):
self.a = a
self.b = b
def somefunc(self, arg1, arg2):
# 这里有些代码
我们在这里看到很多新的关键字。主要是class、__init__和self。这些是什么?同样,通过一些例子很容易解释。
假设你在一家有很多账户的银行工作。我们可以创建一个名为account的类,用于处理任何帐户。例如,下面我创建了一个基本的玩具类帐户,它为用户存储数据,即帐户名和余额。它还为我们提供了两种银行存款/取款的方法。一定要通读一遍。它遵循与上面代码相同的结构。
class Account:
def __init__(self, account_name, balance=0):
self.account_name = account_name
self.balance = balance
def deposit(self, amount):
self.balance += amount
def withdraw(self,amount):
if amount <= self.balance:
self.balance -= amount
else:
print("Cannot Withdraw amounts as no funds!!!")
我们可以使用以下方法创建一个名为Rahul且金额为100的帐户:
myAccount = Account("Rahul",100)
我们可以使用以下方法访问此帐户的数据:

但是,如何将这些属性balance和account_name分别设置为100和“Rahul”?我们从来没有调用过__init__方法,那么为什么对象会获得这些属性?这里的答案是,只要我们创建对象,它就会运行。因此,当我们创建myAccount时,它还会自动运行函数__init__
所以现在我们明白了,让我们试着存一些钱到我们的账户里。我们可以通过:

我们的余额上升到200英镑。但是你有没有注意到,我们的函数deposit需要两个参数,即self和amount,但是我们只提供了一个参数,而且仍然有效。
那么,这个self是什么?有self的方法是用一种不同的方式调用同一个函数。下面,我调用属于类account的同一个函数deposit,并向它提供myAccount对象和amount。现在函数需要两个参数。

我们的账户余额如预期增加了100。所以这是我们调用的同一个函数。现在,只有self和myAccount是完全相同的对象时,才会发生这种情况。我调用的时候我的账户存款(100)。Python为函数调用提供与参数self相同的对象myAccount。这就是为什么self.balance在函数定义中真正指的是myAccount.balance.
但是,仍然存在一些问题

我们知道如何创建类,但是还有一个重要的问题我还没有提到。
所以,假设你正在与苹果iPhone部门合作,并且必须为每种iPhone型号创建一个不同的类。对于这个简单的例子,让我们假设我们的iPhone的第一个版本目前只做一件事——打电话并存储。我们可以这样写:
class iPhone:
def __init__(self, memory, user_id):
self.memory = memory
self.mobile_id = user_id
def call(self, contactNum):
# 这里有些实现
现在,苹果计划推出iPhone1,这款iPhone机型引入了一项新功能——拍照功能。一种方法是复制粘贴上述代码并创建一个新的类iPhone1,如下所示:
class iPhone1:
def __init__(self, memory, user_id):
self.memory = memory
self.mobile_id = user_id
self.pics = []
def call(self, contactNum):
# 这里有些实现
def click_pic(self):
# 这里有些实现
pic_taken = ...
self.pics.append(pic_taken)
但正如你所看到的,这是大量不必要的代码重复(上面用粗体显示),Python有一个消除代码重复的解决方案。编写iPhone1类的一个好方法是:
Class iPhone1(iPhone):
def __init__(self,memory,user_id):
super().__init__(memory,user_id)
self.pics = []
def click_pic(self):
# 这里有些实现
pic_taken = ...
self.pics.append(pic_taken)
这就是继承的概念。根据Wikipedia的说法:继承是将一个对象或类基于另一个保留类似实现的对象或类的机制。简单地说,iPhone1现在可以访问类iPhone中定义的所有变量和方法。
在本例中,我们不必进行任何代码复制,因为我们已经从父类iPhone继承(获取)了所有方法。因此,我们不必再次定义调用函数。另外,我们不使用super在函数中设置mobile_uid和内存。
**super().__init__(memory,user_id)**是什么?
在现实生活中,你的初始函数不是这些漂亮的两行函数。你将需要在类中定义许多变量/属性,并且复制并粘贴子类(这里是iphone1)会很麻烦。因此存在super().。这里super().__init__()实际上在这里调用父iPhone类的**__init__**方法。因此,在这里,当类iPhone1的__init__函数运行时,它会自动使用父类的__init__函数设置类的memory和user_id。
我们在ML/DS/DL中的哪里可以看到?下面是我们创建PyTorch模型。此模型继承了nn.Module类,并使用super调用该类的__init__函数。
class myNeuralNet(nn.Module):
def __init__(self):
super().__init__()
# 在这里定义所有层
self.lin1 = nn.Linear(784, 30)
self.lin2 = nn.Linear(30, 10)
def forward(self, x):
# 在此处连接层输出以定义前向传播
x = self.lin1(x)
x = self.lin2(x)
return x
但什么是「多态」?我们越来越了解类是如何工作的,所以我想我现在就试着解释多态。看下面的类。
import math
class Shape:
def __init__(self, name):
self.name = name
def area(self):
pass
def getName(self):
return self.name
class Rectangle(Shape):
def __init__(self, name, length, breadth):
super().__init__(name)
self.length = length
self.breadth = breadth
def area(self):
return self.length*self.breadth
class Square(Rectangle):
def __init__(self, name, side):
super().__init__(name,side,side)
class Circle(Shape):
def __init__(self, name, radius):
super().__init__(name)
self.radius = radius
def area(self):
return pi*self.radius**2
这里我们有基类Shape和其他派生类-Rectangle和Circle。另外,看看我们如何在Square类中使用多个级别的继承,Square类是从Rectangle派生的,而Rectangle又是从Shape派生的。每个类都有一个名为area的函数,它是根据形状定义的。
因此,通过Python中的多态性,一个同名函数可以执行多个任务的概念成为可能。事实上,这就是多态性的字面意思:“具有多种形式的东西”。所以这里我们的函数area有多种形式。
多态性与Python一起工作的另一种方式是使用isinstance方法。因此,使用上面的类,如果我们这样做:
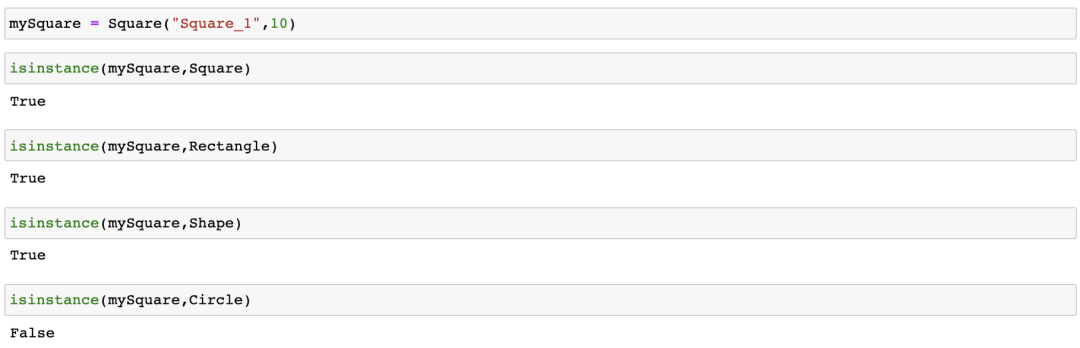
因此,对象mySquare的实例类型是方形、矩形和形状。因此对象是多态的。这有很多好的特性。例如,我们可以创建一个与Shape对象一起工作的函数,它将通过使用多态性完全处理任何派生类(Square、Circle、Rectangle等)。

为什么我们看到函数名或属性名以单下划线和双下划线开头?有时我们想让类中的属性和函数私有化,而不允许用户看到它们。这是封装的一部分,我们希望“限制对对象某些组件的直接访问”。例如,假设我们不想让用户看到我们的iPhone创建后的memory(RAM)。在这种情况下,我们使用变量名中的下划线创建属性。
因此,当我们以下面的方式创建iPhone类时,你将无法访问你的memory或ipython私有函数,因为该属性现在使用_。
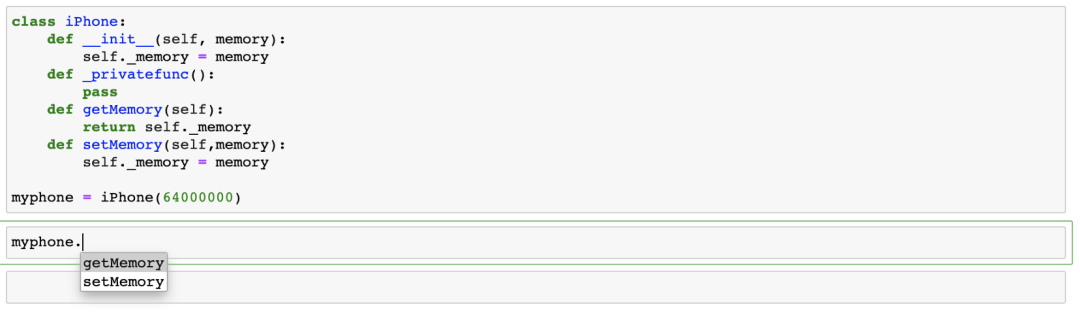
但你仍然可以使用(尽管不建议使用)更改变量值,

你还可以使用私有函数myphone._privatefunc()。如果要避免这种情况,可以在变量名前面使用双下划线。例如,在调用print(myphone.__memory)下面抛出一个错误。此外,你无法使用myphone更改对象的内部数据。myphone.__memory = 1。
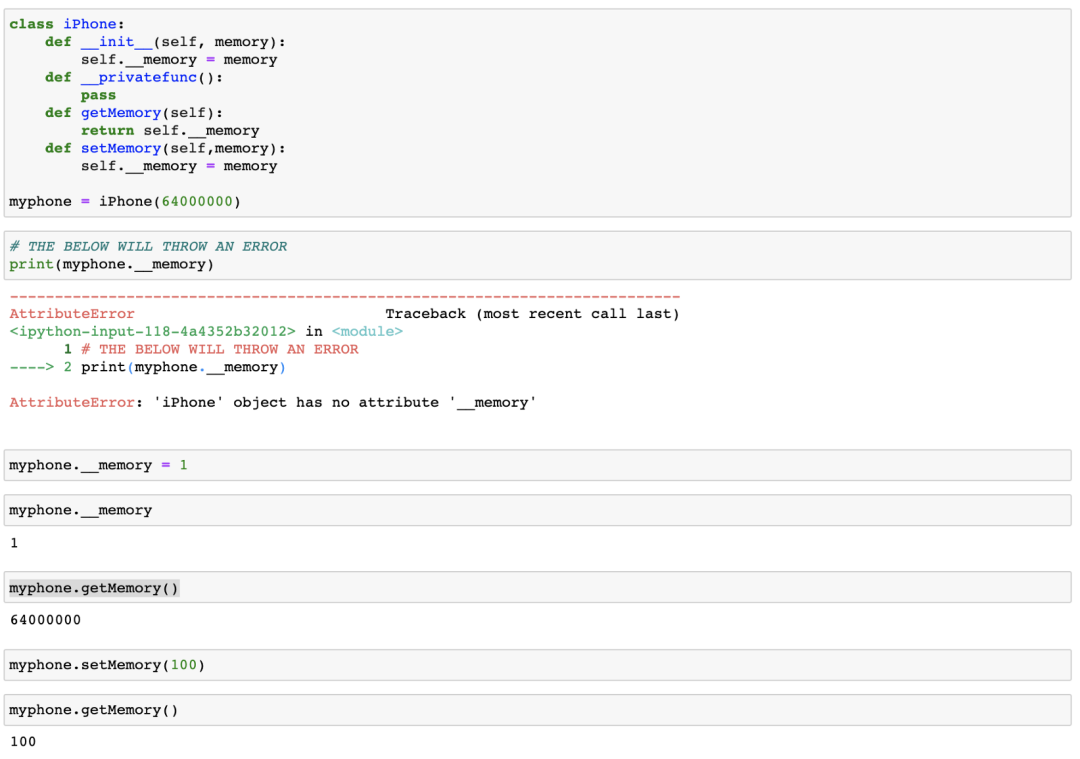
但是,正如你所见,你可以在类定义中的函数setMemory中访问和修改self.__memory

我希望这对你理解类很有用。仍然有很多类需要我在下一篇关于magic方法的文章中讨论。敬请期待。另外,总结一下,在这篇文章中,我们学习了OOP和创建类以及OOP的各种基础知识:
封装:对象包含自身的所有数据。
继承:我们可以创建一个类层次结构,其中父类的方法传递给子类
多态:函数有多种形式,或者对象可能有多种类型。
为了结束这篇文章,我会给你一个练习,让你去实现,因为我认为这可能会为你澄清一些概念。创建一个类,使你可以使用体积和曲面面积管理三维对象(球体和立方体)。基本样板代码如下所示:
import math
class Shape3d:
def __init__(self, name):
self.name = name
def surfaceArea(self):
pass
def volume(self):
pass
def getName(self):
return self.name
class Cuboid():
pass
class Cube():
pass
class Sphere():
pass
如果你想了解更多关于Python的知识,我想从密歇根大学(universityofmichigan)调出一门关于学习中级Python的优秀课程:https://bit.ly/shrea
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~