
一直用git,你了解git的内部机制吗?
Python实战社群
Java实战社群
长按识别下方二维码,按需求添加
扫码关注添加客服
进Python社群▲
扫码关注添加客服
进Java社群▲
作者丨Coder技术栈
来源丨匠心Java
“ 大家好~我是Coder 老C,很高兴又和大家见面了~”
在工作过程中我们会不可避免的使用Git,但是你知道Git是如何存储你的文件、如何保存你的提交信息吗?等等 了解这些也便于我们更好的理解和记忆命令,更好的排查问题和使用Git,下面就让我们来看一下吧~
本文主要依照官网的介绍根据真实项目中的变化总结整理而成
首先,我们要明确 Git 是一个分布式版本控制系统 其本质是一套 内容寻址文件系统
通俗点说,Git 从核心上来看不过是简单地存储键值对(key-value)。它允许插入任意类型的内容,并会返回一个键值,通过该键值可以在任何时候再取出该内容。
ps : 下面所说的SHA-1码 和 commit_id 是同一种
首先,Git存储在本地的表现形式
当你在一个新目录或已有目录内执行 git init 时,Git 会创建一个 .git 目录,几乎所有 Git 存储和操作的内容都位于该目录下。如果你要备份或复制一个库,基本上将这一目录拷贝至其他地方就可以了。如下图: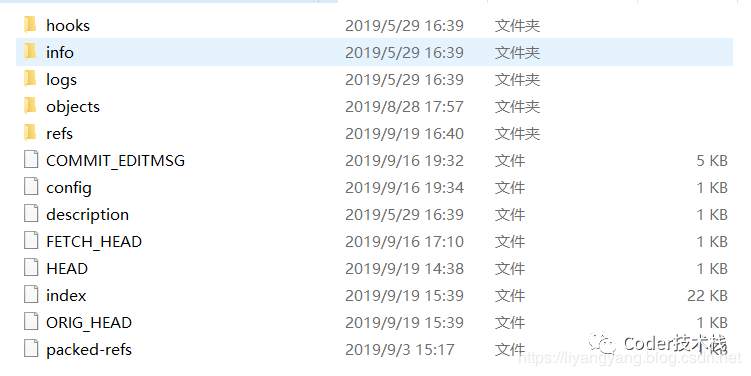
info目录保存了一份不希望在 .gitignore 文件中管理的忽略模式 (ignored patterns) 的全局可执行文件hooks目录保存了客户端或服务端钩子脚本config文件包含了项目特有的配置选项objects目录存储所有数据内容refs目录存储指向数据 (分支) 的提交对象的指针HEAD文件指向当前分支index文件保存了暂存区域信息
其中,HEAD 及 index 文件,objects 及 refs 目录是 Git 的核心部分。
接下来,说一下Git的存储方式
如上述所说,objects 目录存储所有数据内容,objects 目录下的每一个文件是Git为每份存储数据内容生成一个文件,取得该内容与头信息的 SHA-1 校验和,创建以该校验和前两个字符为名称的子目录,并以 (校验和) 剩下 38 个字符为文件命名 (保存至子目录下)。如下图: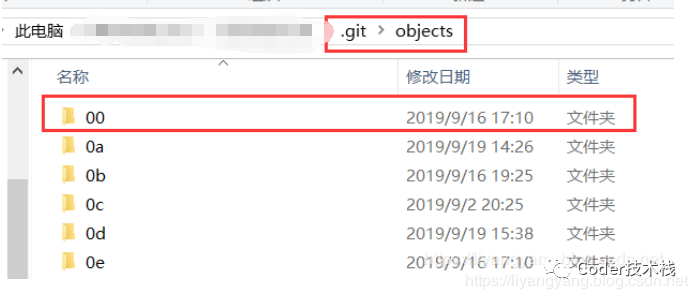 打开00文件夹可以看到里面保存的内容:
打开00文件夹可以看到里面保存的内容: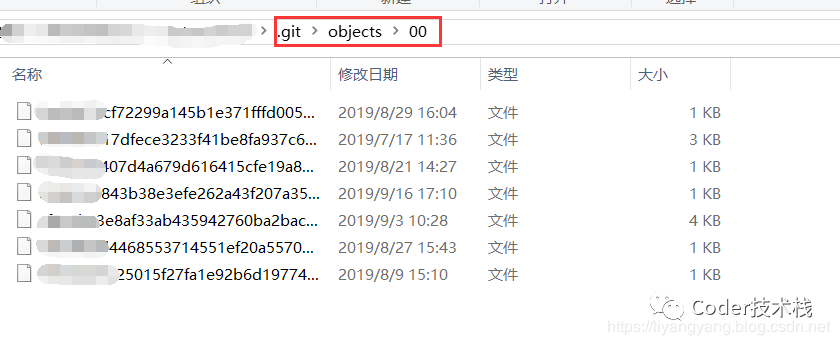 Git 以一种类似 UNIX 文件系统但更简单的方式来存储内容。所有内容以 tree 或 blob 对象存储,其中 tree 对象对应于 UNIX 中的目录,blob 对象则大致对应于 inodes 或文件内容。
Git 以一种类似 UNIX 文件系统但更简单的方式来存储内容。所有内容以 tree 或 blob 对象存储,其中 tree 对象对应于 UNIX 中的目录,blob 对象则大致对应于 inodes 或文件内容。
一个单独的 tree 对象包含一条或多条 tree 记录,每一条记录含有一个指向 blob 或子 tree 对象的 SHA-1 指针,并附有该对象的权限模式 (mode)、类型和文件名信息。
正如 Git的每一次提交都是对代码仓库的完整备份,也就是保存了一份代码仓库完整的快照所说,每一个commit都是存储为一个Tree,如下图: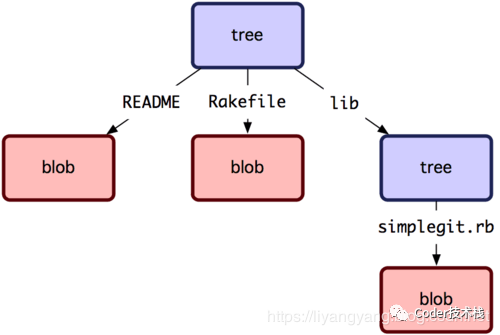 具体在git中为:
具体在git中为:可以看到,目录作为tree存储,文件作为blob存储
之后,我们通过 git cat-file-p命令可以发现存储是树型的,也就是对应于git的tree对象,保存的都是指向下一个部分的索引id
如下图,每一步都是查看的上一步中的某个id: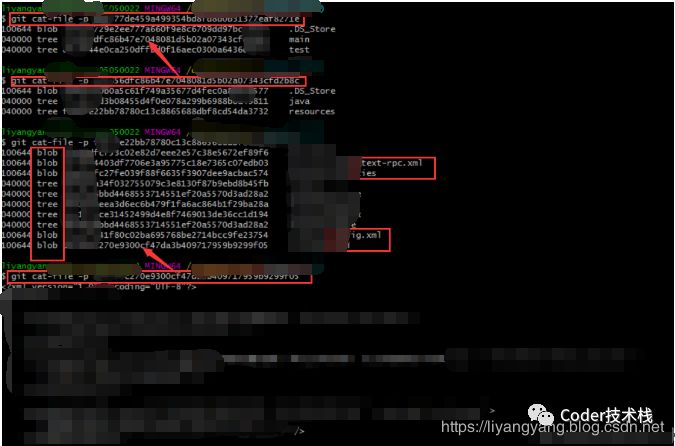
上述所说每个commit创建一个树快照,那么是通过什么创建的呢?
这就是我们上述说的 用于存储暂存区信息的index文件了。
通常 Git 根据你的暂存区域或 index 来创建并写入一个 tree 。因此要创建一个 tree 对象的话首先要通过将一些文件暂存从而创建一个 index 。
这也是为什么commit前必须要有文件被add到暂存区,如果暂存区为空,commit会报错停止执行。
这个时候就有一个问题了,我们有多个快照树,它们指向了你要跟踪的项目的不同快照,其中也没有关于谁、何时以及为何保存了这些快照的信息
此时,commit对象就出场了~ 每次commit提交后就会创建一个对应commit 对象,这个对象就是为你保存了这些基本信息的。
一般情况下,一次commit提交就可以理解为创建了一个tree树,以commit_id为根节点的tree,该树包含了当前项目的整体快照
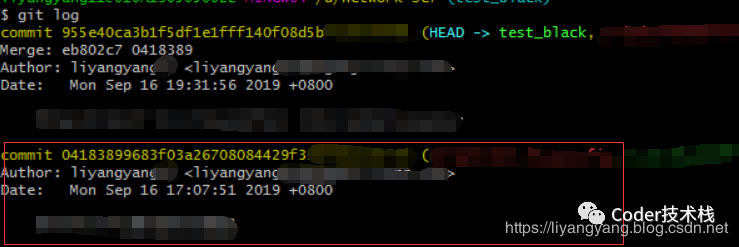
当我们使用 git log命令查看提交历史的时候,就展示了commit对象的一些基本信息,如下图:
其中:commit 后跟的id就是当前commit快照的树根节点id
其余的还包含作者,作者邮箱,创建时间等基本信息
Git每次commit提交会保存项目快照,难道是将所有的文件重新复制一份吗?
当然不可能,在git的文件系统中,是存在共用文件的。
比如有三次commit提交,产生了三个tree树,它们在向下引用的时候,如果两个commit中的整个文件夹或者某个文件没有改变,这两个commit的tree会指向同一个对象。对于两次提交修改了的文件,则会创建一个该文件的一个新的版本的文件,上一次提交指向旧的文件,修改文件的提交指向新版本的文件。
整体情况如下图: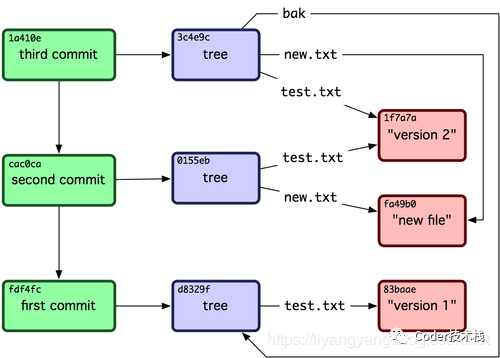 另外,Git 用 zlib 压缩文件内容,因此存储的文件并不会占用太多空间
另外,Git 用 zlib 压缩文件内容,因此存储的文件并不会占用太多空间
了解了git整体存储方式之后,我们再看一下前面提到的存储指向数据 (分支) 的提交对象的指针的 refs目录
refs目录内容如下图: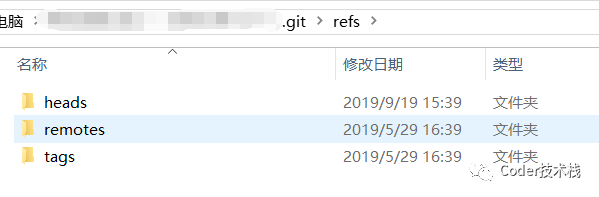 首先,也是思考一个问题:在项目开发中,有许多分支,每个分支的提交记录都不相同,我们也不可能去记住每个commit_id,去执行像
首先,也是思考一个问题:在项目开发中,有许多分支,每个分支的提交记录都不相同,我们也不可能去记住每个commit_id,去执行像 git log1a410e 这样的命令来查看完整的历史,这样的话你就要记得 1a410e 是你最后一次提交并且记得这个id,这样才能在提交历史中找到这些对象,git是怎样的应对这个问题的呢?
这时候,我们需要一个文件来用一个简单的名字来记录这些 SHA-1 值,这样就可以用这些指针而不是原来的 SHA-1 值去检索了。在 Git 中,称之为“引用”(references 或者 refs)。
可以在 .git/refs 目录下面找到这些包含 SHA-1 值的文件。如下图refs中heads文件下的文件,其中 每个文件存储的是与文件名同名的分支的最新提交的commit_id: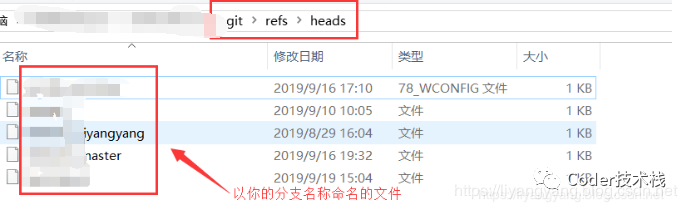 添加上refs文件夹下的文件后,我们的Git存储结构就看起来像下图:
添加上refs文件夹下的文件后,我们的Git存储结构就看起来像下图: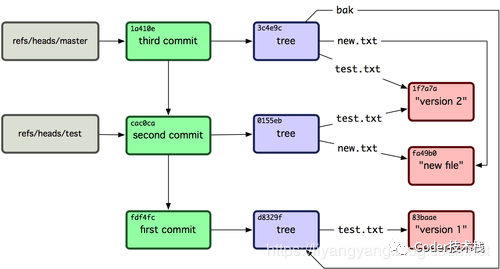
接下来,再思考一个问题,git是怎么标识当前是在什么分支,从而找到refs中对应的映射文件获取SHA-1值呢?
那就是前面所说的HEAD文件了,我们打开文件可以看到以下内容:ref:refs/heads/test_branch
这里标识的是当前指向的是test_branch分支,并且指定了要是用的映射文件的路径,这样就解决了上述问题,是不是特别简单~
上述已经介绍了Git的三个主要类型:tree树、commit对象、HEAD。下面我们说一下Git中另外一个重要的东西:Tag(标签)Tag 对象比较简单,Tag对象非常像一个 commit 对象---包含一个标签,一组数据,一个消息和一个指针。最主要的区别就是 Tag 对象指向一个 commit 而不是一个 tree。它就像是一个分支引用,但是不会变化,永远指向同一个 commit,仅仅是为了提供一个更加友好的名字。
好了,通过介绍了git的核心组成元素
HEAD及index文件,objects及refs目录, 你应该会对git的存储和一些机制有一个简单的整体了解,这对我们更好的理解git命令和更好的使用git是有帮助的。希望本片文章会对大家有些许帮助~
参考:git官网


近期精彩内容推荐:

