
No.5时序数据库随笔 - NaN的支持
2021 校招请阅读:阿里云2021春招
开篇引题
上一篇我们提到了Apache IoTDB如何支持Nullable的问题,IoTDB用NaN来代表没有值,查询之后我们发现NaN代表来当前数据类型的默认值。如:FLOAT 的默认值就是 0.0.
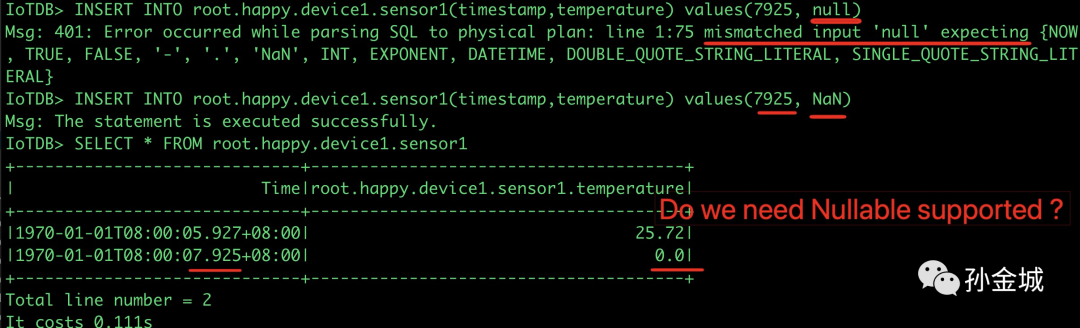
那么这个结果是在v.0.11.2 版本的行为,但从NaN的设计来说,这是一个错误的行为,或者说这是一个bug,在IoTDB-1158里面的讨论区,我们也提到了这一点,目前在master已经修复了。
那么今天我们聊一下,有了NaN我们目前还需要对Apache IoTDB增加Nallable的语法支持吗?
Nallable的本质
任何功能的支持我们可能需要考虑两个维度,一是业务需求,客观业务场景需要的功能一定是我们需要解决的,二是领域标准,做时序数据库我们要考虑传统数据库标准,我们要考虑时序领域的标准。
在业务角度,业务期望的是当由于某种原因,无法提供当前时刻某个传感器的值的时候,需要在查询的是被业务感知的。那么IoTDB里面提供了NaN的策略来支持如 Float、Double等数值的不存在的情况,NaN(Not a number)。
在领域标准方面,传统数据库是有如 NOT NULL 的语法支持的,也就是说字段类型声明时候如果没有声明NOT NULL默认用户在整行插入时候是可以不携带该字段的值的,而显示声明了NOT NULL 那么每次insert 语句就必须携带当前的值。
今天我们文末就以Apache IoTDB Master代码再看看对NaN的支持情况,基于Commit: b986cd1e5f
同类(InfluxDB)行为
我们有时候在买东西时候经常货比三家,不管这物品是好是坏,是贵还是便宜,我们看看其他商家是什么品质,是什么价格,就能辅助我们做判断。那么学习Apache IoTDB的小伙伴,我也建议对InfluxDB有一定的了解. 目前InFluxDB稳定版本是1.8.4,我们就以1.8.4为例体验一下InfluxDB对null的支持方式。
二进制安装
我们今天在macOS下进行操作,首先确保你已经安装了brew工具。然后我们可以一条命令安装InfluxDB v1.8.4.
brew updatebrew install influxdb
启动InfluxDB服务
influxd
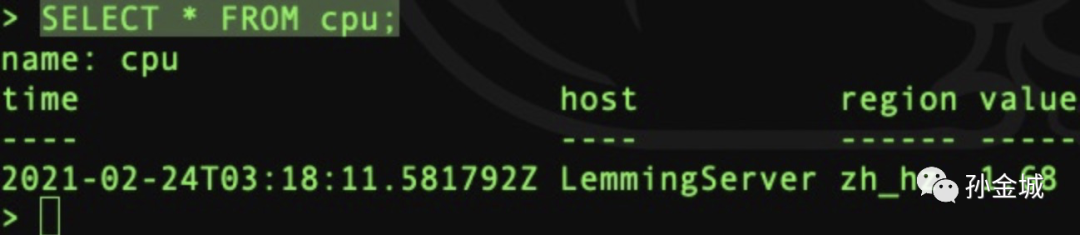
客户端连接并创建测试数据库
jincheng:~ jincheng.sunjc$ influx -precision rfc3339Connected to http://localhost:8086 version 1.8.4InfluxDB shell version: 1.8.4CREATE DATABASE "lemming";use lemming;INSERT cpu,host=LemmingServer,region=zh_hz value=1.68SELECT * FROM cpu;
Nullable的支持情况
单值插入Null(参考InfluxDB的历史信息)
https://github.com/influxdata/influxdb/issues/7722
https://github.com/influxdata/influxdb/pull/2429
https://github.com/influxdata/influxdb/blob/v1.8.4/CHANGELOG.md
> INSERT cpu,host=LemmingServer,region=zh_hz value=
ERR: {"error":"unable to parse 'cpu,host=LemmingServer,region=zh_hz value=': missing field value"}
INSERT cpu,host=LemmingServer,region=zh_hz value=''
ERR: {"error":"unable to parse 'cpu,host=LemmingServer,region=zh_hz value=''': invalid boolean"}
> INSERT cpu,host=LemmingServer,region=zh_hz value=null
ERR: {"error":"unable to parse 'cpu,host=LemmingServer,region=zh_hz value=null': invalid number"}
如上现象说明InfluxDB本身对单值的插入也是不支持Null的。那么这个和IoTDB的现状是一样的。我们再来看看多值同时插入的时候“现象”。
多插入Null
正常插入:
> INSERT temperature,machine=unit42,type=assembly external=25,internal=37
> select * from temperature;
name: temperature
time external internal machine type
---- -------- -------- ------- ----
2021-02-24T04:03:35.634296Z 25 37 unit42 assembly
internal为空:
> INSERT temperature,machine=unit42,type=assembly external=25,internal=
ERR: {"error":"unable to parse 'temperature,machine=unit42,type=assembly external=25,internal=': missing field value"}
internal为null:
> INSERT temperature,machine=unit42,type=assembly external=25,internal=null
ERR: {"error":"unable to parse 'temperature,machine=unit42,type=assembly external=25,internal=null': invalid number"}
不携带internal:
> INSERT temperature,machine=unit42,type=assembly external=25
> select * from temperature;
name: temperature
time external internal machine type
---- -------- -------- ------- ----
2021-02-24T04:03:35.634296Z 25 37 unit42 assembly
2021-02-24T04:05:37.18028Z 25 unit42 assembly
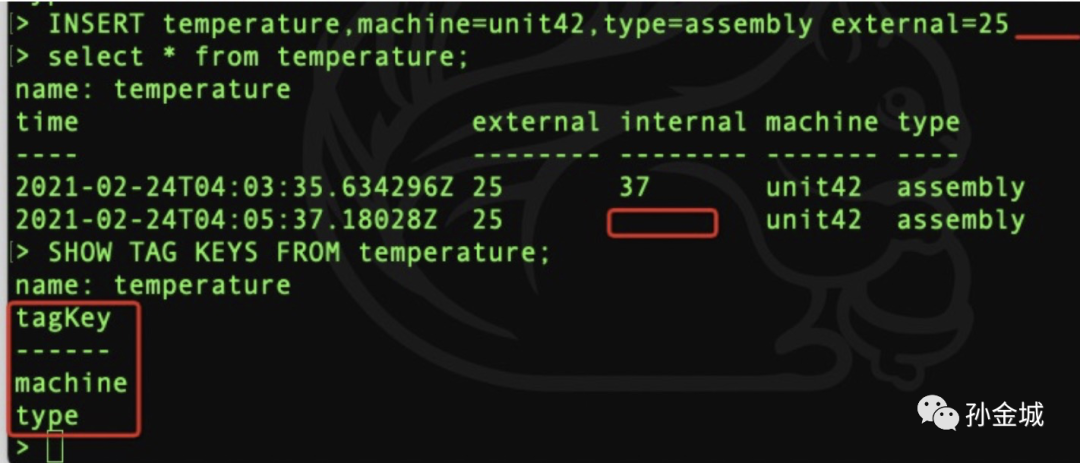
所以根据目前表现,InfulxDB v1.8.4 不支持直接插入Null,但是可以在多值插入时候,不携带某个值,也就是空值的支持。
IoTDB Master 行为(b986cd1e5f)
我们基于 b986cd1e5f进行编译,如下:
启动服务和CLI
启动服务,如下:
jincheng:apache-iotdb-0.12.0-SNAPSHOT-all-bin jincheng.sunjc$ nohup sbin/start-server.sh >/dev/null 2>&1 &[1] 22357
注意我们最新的发布目录已经有变化`apache-iotdb-0.12.0-SNAPSHOT-all-bin`。
连接服务进入CLI,如下:
sbin/start-cli.sh -h 127.0.0.1 -p 6667 -u root -pw root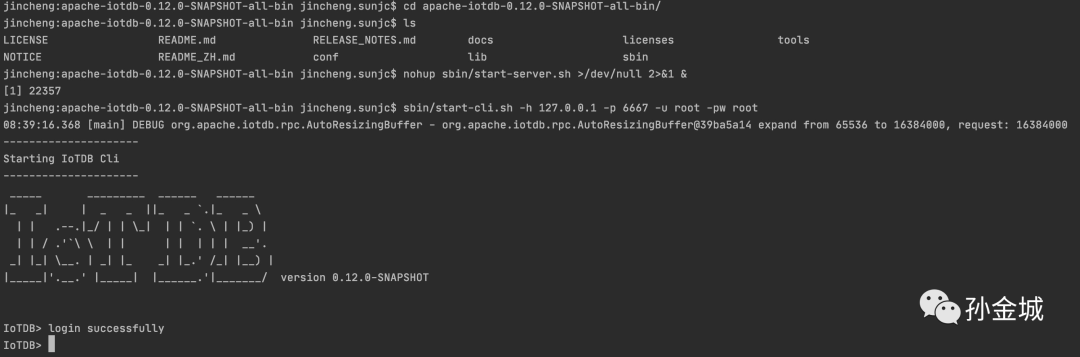
NaN的支持
先进行一些初始化,如下:
SET STORAGE GROUP TO root.lnCREATE TIMESERIES root.ln.wf01.wt01.status WITH DATATYPE=BOOLEAN, ENCODING=PLAINCREATE TIMESERIES root.ln.wf01.wt01.temperature WITH DATATYPE=FLOAT, ENCODING=RLE
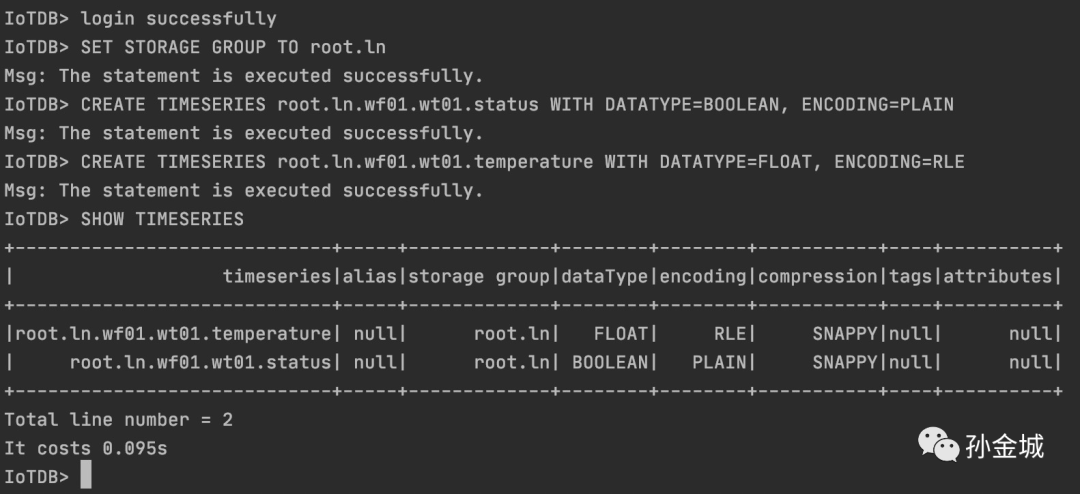
单值的插入
正常插入
INSERT INTO root.ln.wf01.wt01(timestamp,status) values(100,true);INSERT INTO root.ln.wf01.wt01(timestamp,temperature) values(200,20.71)
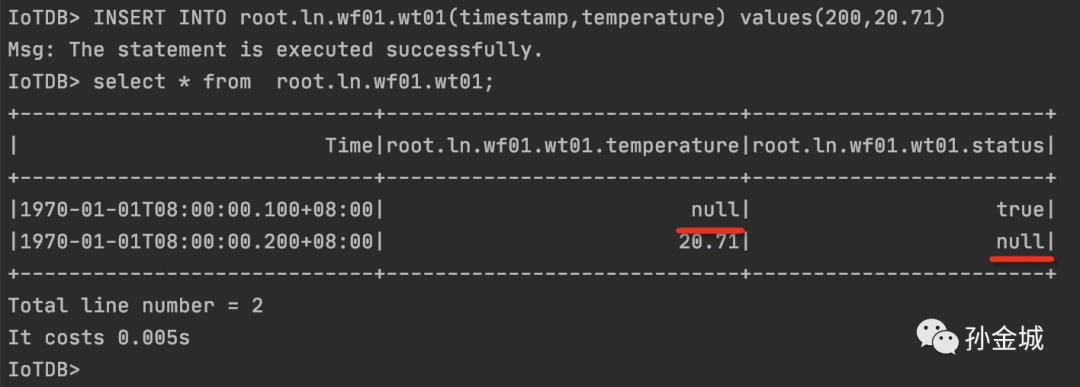
我们可以看到,单值正常插入都是OK的,同时我们在查询时候,如果在相同ts某些值不存在时候,我们查询出来显示是null的,用户可以感知到多时间序列按时间对齐形成一行数据时候哪些字段为null。
异常插
IoTDB> INSERT INTO root.ln.wf01.wt01(timestamp,temperature) values(200,)Msg: 401: Error occurred while parsing SQL to physical plan: line 1:64 mismatched input ')' expecting {NOW, TRUE, FALSE, '-', '.', 'NaN', INT, EXPONENT, DATETIME, DOUBLE_QUOTE_STRING_LITERAL, SINGLE_QUOTE_STRING_LITERAL}IoTDB> INSERT INTO root.ln.wf01.wt01(timestamp,temperature) values(200,'')Msg: 313: failed to insert measurements [temperature] caused by For input string: "''"IoTDB> INSERT INTO root.ln.wf01.wt01(timestamp,temperature) values(200,null)Msg: 401: Error occurred while parsing SQL to physical plan: line 1:64 mismatched input 'null' expecting {NOW, TRUE, FALSE, '-', '.', 'NaN', INT, EXPONENT, DATETIME, DOUBLE_QUOTE_STRING_LITERAL, SINGLE_QUOTE_STRING_LITERAL}IoTDB>

这个现象其实与InfluxDB的表象也是一样的,我们这样设计也是合理的,因为我们是强类型系统,声明了FLOAT类型,就必须插入的是FLOAT值。那么我们再看看多值插入的行为表现。
多值的插入
正常插入
INSERT INTO root.ln.wf01.wt01(timestamp,status,temperature) values(200,false,20.71)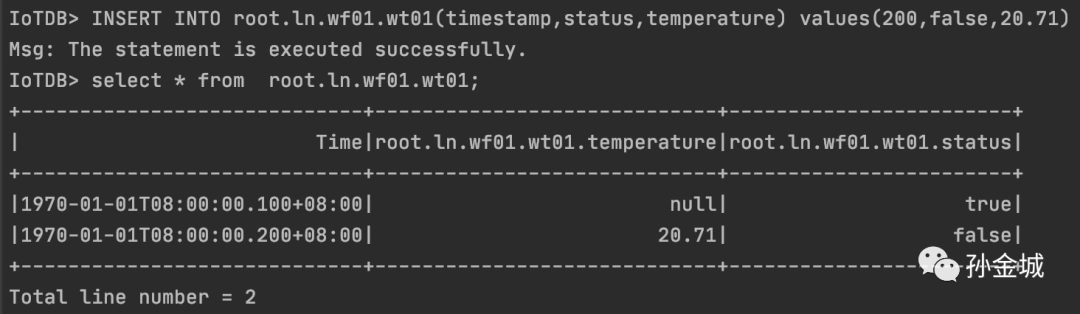
上面一切正常,注意一点,我们插入时间戳是用的是200,那么会覆盖之前的相同时间戳的值。
缺值插入
INSERT INTO root.ln.wf01.wt01(timestamp,status,temperature) values(200,false,)INSERT INTO root.ln.wf01.wt01(timestamp,status,temperature) values(200,false,null)INSERT INTO root.ln.wf01.wt01(timestamp,status,temperature) values(200,false,NaN)
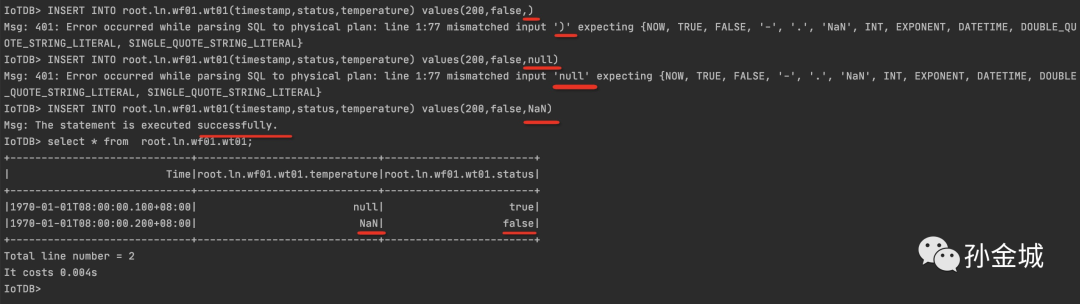
其实,大家发现多值插入,和单值插入的支持是一样的,如果显示的指定要要插入某个列的值,那么就必须在values里面有其合法的值进行插入。如果没有业务值,IoTDB为大家提供了NaN来表示没有具体的数值。当然,NaN不仅仅在多值插入时候可以应用,在单值进行插入时候也是一样可以支持的。比如:
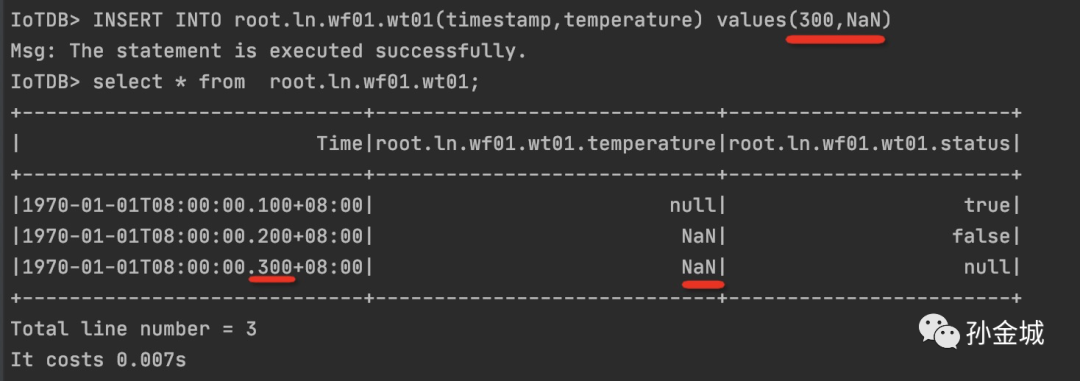
篇尾提问:为啥一定需要NaN呢?
看到这里大家也许会有个疑问,既然我在插入时候没有值我就可以不插入,在查询的时候 IoTDB可以按时间对齐形成一行数据显示,对应时间戳不存在的值用null来显示来,那么我们为什么还要用NaN呢?
这个就和业务有点关系来,比如:如果一个列的值是null显示的,那么到底是当时这个时间点真的设备没有值上送,还是虽然设备上送了数值,但是由于业务程序bug(或者值不合法)导致没有插入成功呢?这个问题是很难回答了,因为:
设备没上送值我们不插入,查询时候是null,
设备虽然上送了,但是业务代码有bug没有插入成功,查询时候也是null,
但是如果我们有NaN的支持,那么我们在业务代码里面每一个时间戳都对应的所有列我们都进行值的插入,如果没有值或者值不合法,那么我们就显示的设置一个NaN代表业务本身在那个时刻没有收到合法的值,而一旦出现null,那就代表在那个时刻业务没有收到设备的任何数据事件,也没有进行任何insert动作,所以查询时候就是null,就可以方便的定位问题了。
再回到开篇的问题,有了NaN我们目前还需要对Apache IoTDB增加Nallable的语法支持吗?
NaN 不等于 Nullable
NaN解决了Float/Double的某些场景的业务问题,但是其他非数值类型,如今天涉及到的Boolean类型是没有支持,从语义角度非数值类型也不应该有NaN的设计,所以关于非数值类型的Null的考虑还是值得进一步讨论的。
下一篇聊什么?
我们希望每一篇都聊点用户提到的问题,下一篇我们聊了InfluxDB和IoTDB如何解决下面这个朋友的问题:
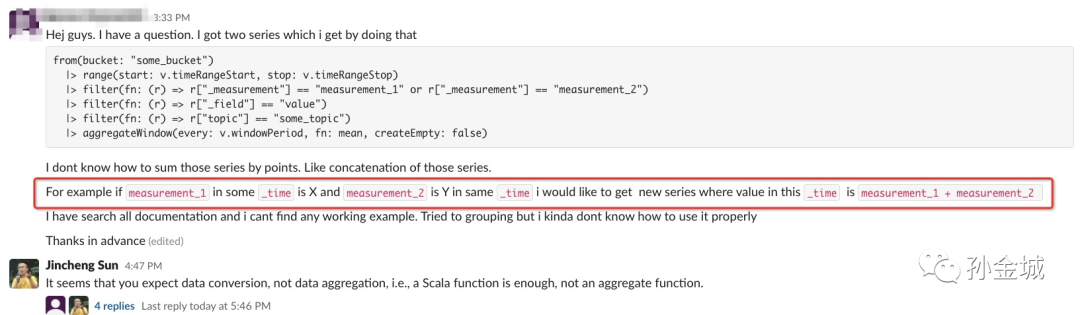
如果你有答案,也可以提前留言,看看你和我的思考是否一样... :) 我们今天就到这里,下次见。
阿里招聘
时序数据库开发岗位
(P7/P8/P9)
(长期有效)
职位描述:
1. 精通Java/Scala编程
2. 精通常用数据结构和算法应用,具备良好的、精益求精的设计思维,每一个bit都是客户/技术价值。
3. 了解Hadoop/Flink/Spark等计算框架和熟悉HBase/LevelDB/RocksDB等主流NoSQL数据库,深入理解其实现原理和架构优势劣势;
4. 具备分布式系统的设计和应用的经历,能对分布式常用技术进行应用和改进者优先;
5. 有开源社区贡献,并成为Flink/Spark/Druid/OpenTSDB/InfluxDB/IoTDB等社区的Committer/PMC者优先;
6. 要具备良好的团队协作能力,良好的沟通表达能力,和对正确事情持之以恒的韧性和耐力。
来!让我看到你的简历,因为成就你的不仅仅是能力,更是雷厉风行的执行力!