
Flink 在 58 同城的应用与实践
一、实时计算平台架构
实时计算平台的定位是为 58 集团海量数据提供高效、稳定的实时计算一站式服务。一站式服务主要分为三个方向:
第一个方向是实时数据存储,主要负责为线上业务接入提供高速度的实时存储能力;
第二是实时数据计算,主要为海量数据的处理提供分布式计算框架;
第三是实时数据分发,主要负责将计算后的数据分发到后续的实时存储,供上层应用。

第一部分是基础能力建设,目前主要包括 Kafka 集群、storm 集群、 Flink 集群、SparkStreaming 集群。
另一部分是平台化建设,主要是包括两点:
第一个是数据分发,我们的数据分发是基于 Kafka Connect 打造的一个平台,目标是实现异构数据源的集成与分发。在实际使用数据场景过程中,经常需要将不同的数据源汇聚到一起进行计算分析。
传统方式可能需要针对不同的存储采用不同的数据同步方案。我们的数据分发是通过提供一套完整的架构,实现不同数据源的集成和分发。
第二个是我们基于 Flink 打造的一站式实时计算平台,后文会有详细的介绍。
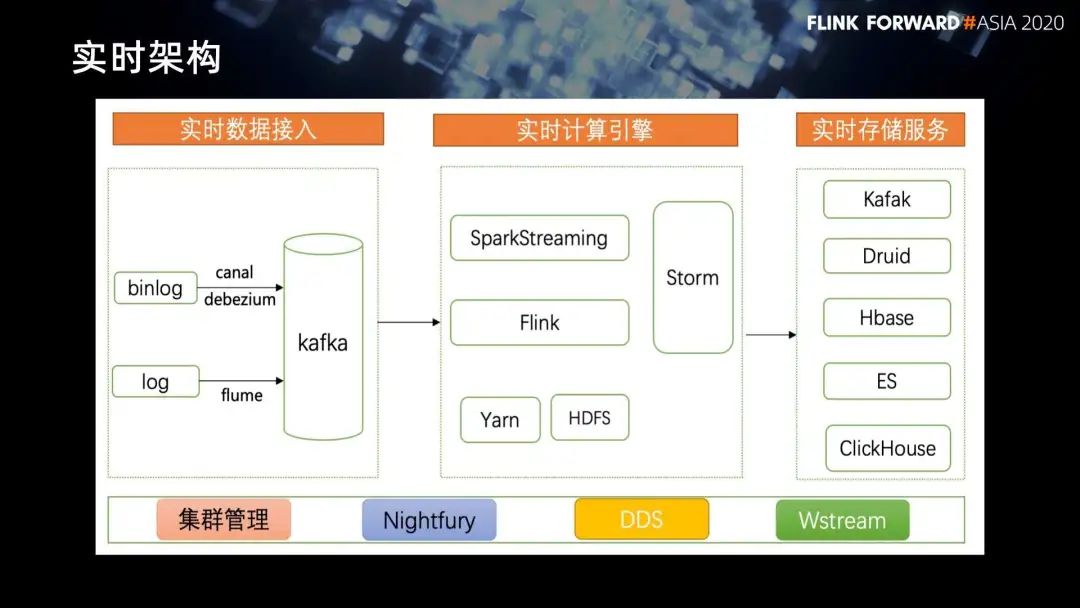
在实时数据接入这部分,我们采用的是 Kafka,binlog 提供 canal 和 debezium 两种方式进行接入。
在业务日志这部分,我们主要采用 flume 进行线上业务的 log 的采集。
在实时计算引擎这部分,根据开源社区发展以及用户的需求,从最早的 Storm 到后来引入 SparkStreaming,以及现在主流的 Flink。
在实时存储这部分,为了满足多元化的实时需求,我们支持 Kafka、Druid、Hbase、ES、ClickHouse。
同时在计算架构之上,我们建设了一些管理平台,比如集群管理,它主要负责集群的扩容,稳定性的管理。
另一个是 Nightfury,主要负责集群治理,包括数据接入、权限治理、资源管理等等。

第一个场景是实时 ETL,主要是针对原始日志进行信息转化,结构化处理,运用于后续计算,需要高吞吐低延迟的计算能力。
第二块是实时数仓,它作为离线数仓的一个补充,主要是提升一些实时指标的时效性。第三种场景是实时监控,它需要比较灵活的时间窗口支持。
最后一种场景是实时数据流分析,比如说,数据乱序的处理、中间状态的管理、Exactly once 语义保障。
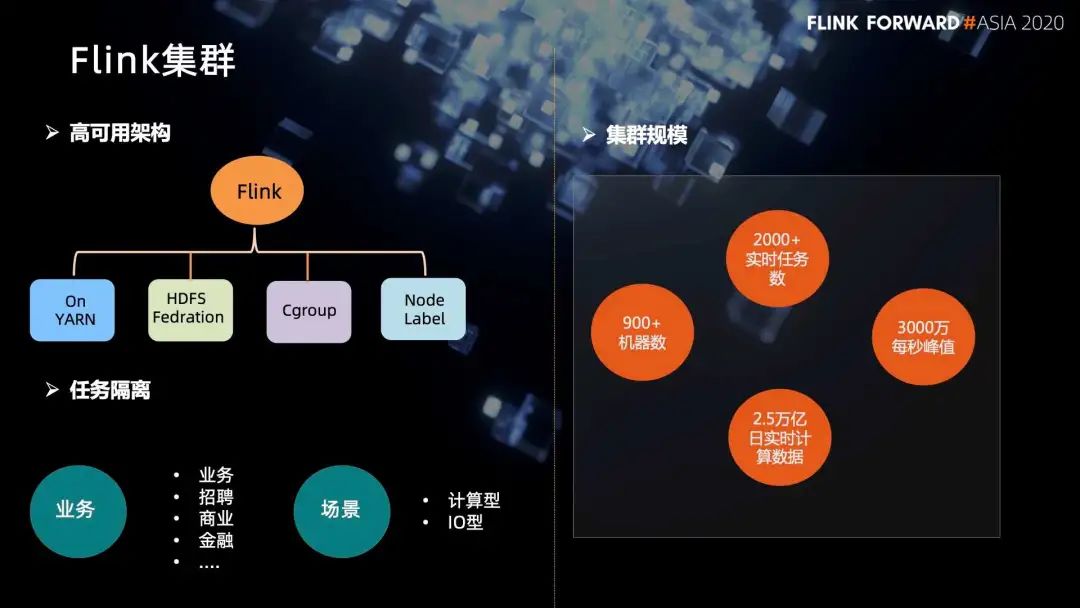
首先在部署模式上,主要是采用 Flink On YARN,实现集群的高可用。
在底层的 HDFS 上,采用 HDFS federation 机制,既可以避免离线集群的抖动对实时这边造成影响,同时也减少了维护的 HDFS 数量。
在集群隔离上,主要是采用 Node Labe 机制,就可以实现把重要业务运行在一些指定节点上。同时在这个基础之上,引入了 Cgroup,对 CPU 进行隔离,避免任务间的 CPU 抢占。
在管理层面,不同的业务提交到不同的队列进行管理,避免业务间的资源抢占。
在计算场景上,根据不同的计算场景,比如说计算型、IO 型,会提交到不同的节点,从而提升整个集群的资源利用率。
二、实时 SQL 建设
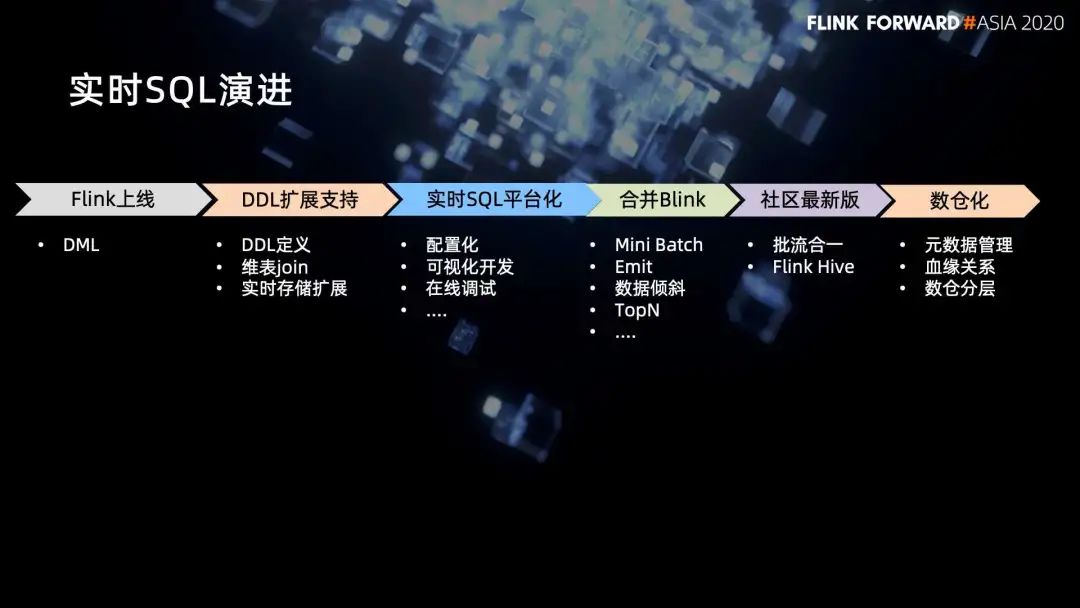
1. 实时 SQL 演进
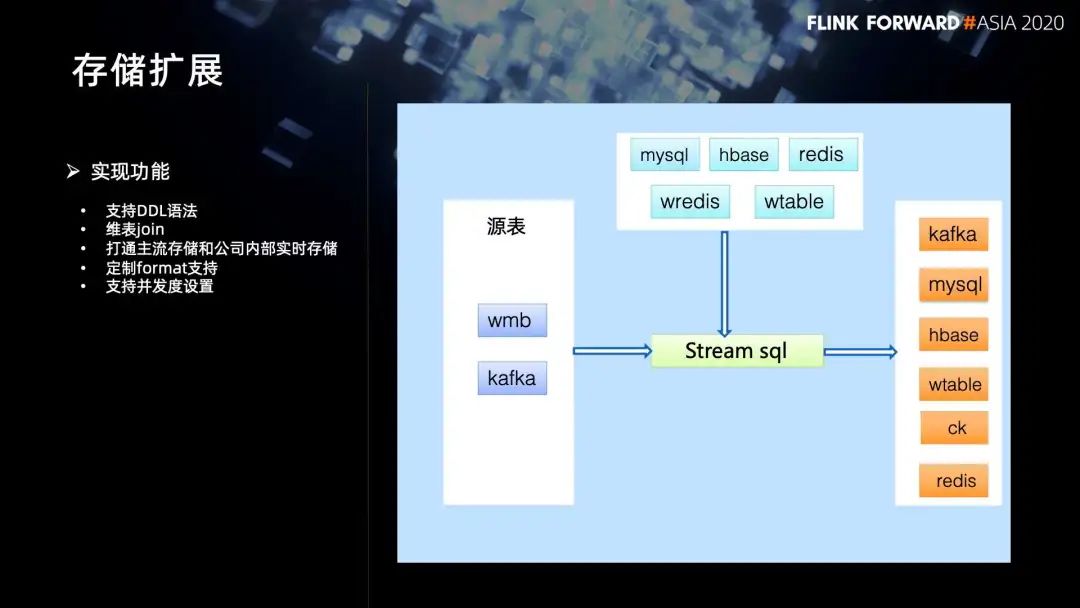
2. 存储扩展
第一,打通了主流存储和内部的实时存储。比如说,在源表上支持了内部的 wmb,它是一个分布式消息队列。在维表上支持这种 redis,内部的 wtable。在结果表上支持了 ClickHouse,redis,以及我们内部的 wtable;
第二,定制 format 支持。因为在实际业务中,很多数据格式并不是标准的,没法通过 DDL 来定义一个表。我们提供了一种通用的方式,可以采用一个字段来代表一条日志,让用户可以通过 udf 去自定义,并解析一条日志。
最后,在 source 和 sink DDL 定义基础上,增加了并发度的设置。这样用户就可以更灵活地控制任务的并发。
3. 性能优化
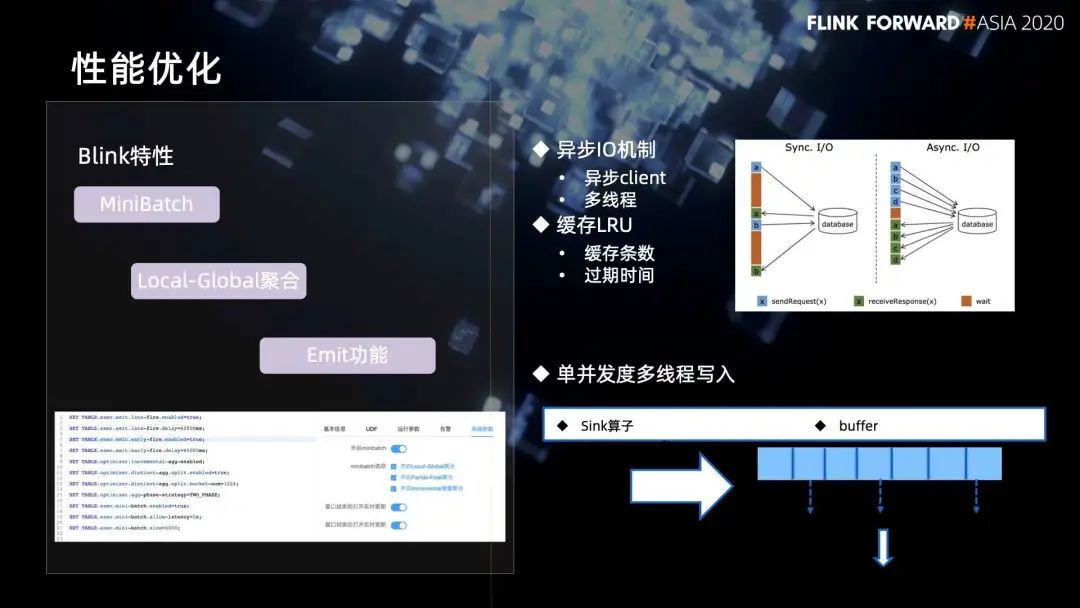
第一个是对 Blink 特性的引进,Blink 提供了大量的特性,比如通过 mini batch 的处理方式,提高任务的吞吐。通过 local global 两阶段聚合,缓解数据热点问题。还有通过 emit,增强窗口的功能。把这些功能集成到我们的计算平台,用户通过一些按钮可以直接打开。
另一个是对异步 lO 的应用。在实时数仓化建设过程中,维表之间的关联是比较大的应用场景,经常因为维表的性能导致整个任务的吞吐不高。因此我们增加了一个异步 IO 的机制,主要有两种实现:
一种针对目标存储支持异步 client,直接基于异步 client 来实现。比如 MySQL 和 redis。
另一种不支持异步 client 的,我们就借助现成的机制来模拟,同时在这个基础之上增加了一套缓存的机制,避免所有的数据直接查询到目标存储,减少目标存储的压力。同时在缓存基础上,也增加 LRU 机制,更加灵活的控制整个缓存。
同样,数据写入这一块遇到大并发量写入的时候,尽量提高并发来解决写入性的问题,这样就会导致整个任务的 CPU 利用率比较低,所以就采用单并发度多线程的写入机制,它的实现是在 sink 算子里面增加一个 buffer,数据流入到 sink 之后会首先写入到 buffer,然后会启动多线程机制去消费这个 buffer,最终写到存储里面。
4. 数仓化建设
首先,元数据管理功能不完善;
然后,Flink SQL 这一块,对于每个任务我们都可能需要重新定义一个数据表。并且由于数据没有分层的概念,导致任务比较独立,烟囱式开发,数据和资源使用率比较低下;
另外,也缺乏数据血缘信息。

■ 4.1 数仓化
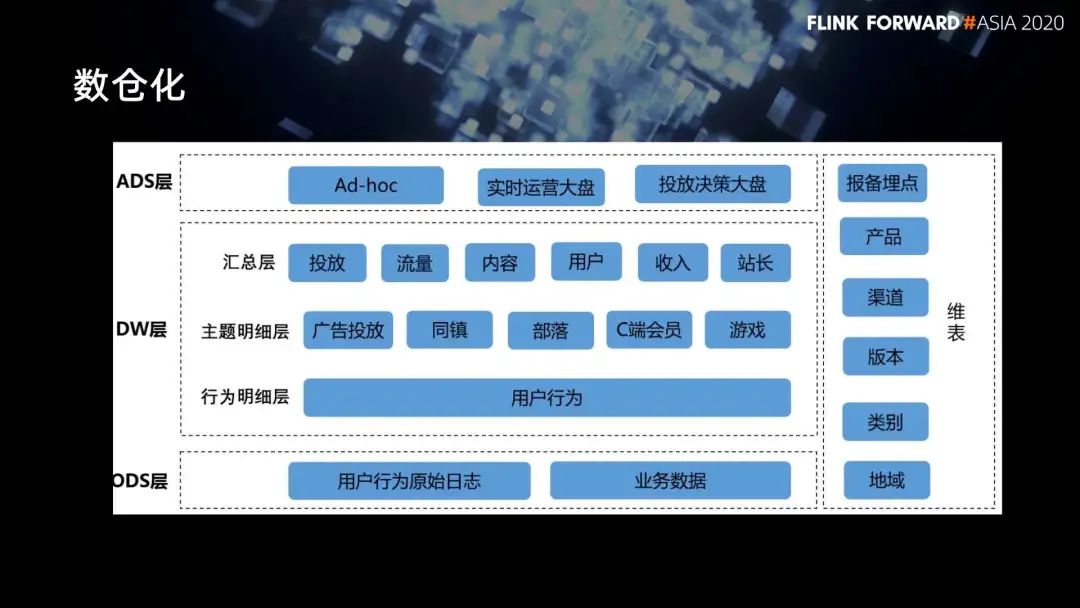
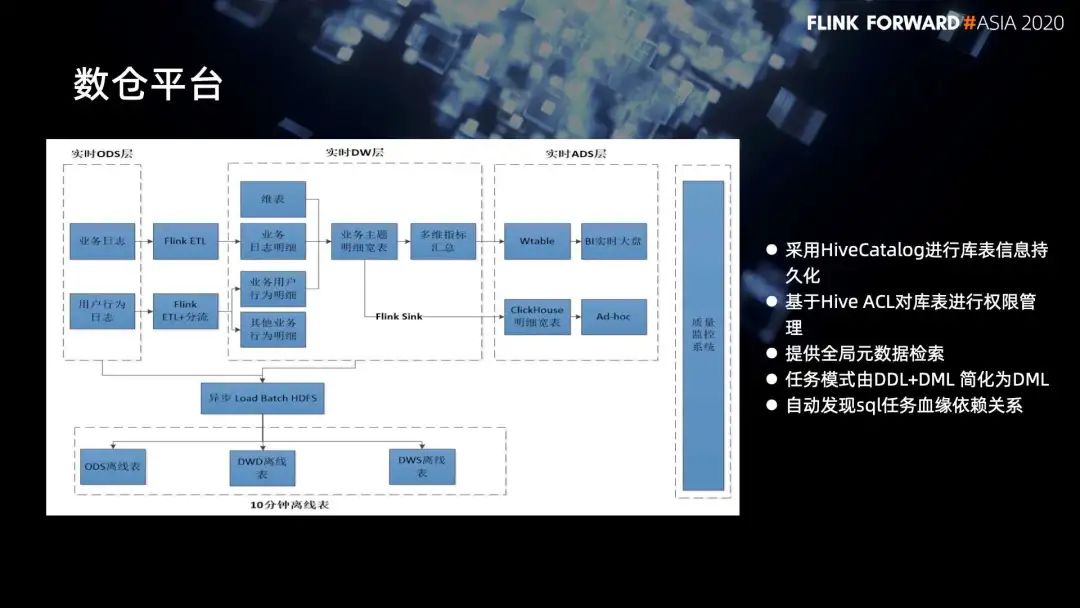
■ 4.2 数仓平台
首先,在元数据管理这一块,Flink 默认采用内存对元数据进行管理,我们就采用了 HiveCatalog 机制对库表进行持久化;
同时我们在数据库的权限管理上,借助 Hive ACL 来进行权限管理;
有了元数据持久化之后,就可以提供全局的元数据检索;
同时任务模式就可以由传统的 DDL+DML 简化为 DML;
最后,我们也做了血缘关系,主要是在 Flink SQL 提交过程中,自动发现 SQL 任务血缘依赖关系。
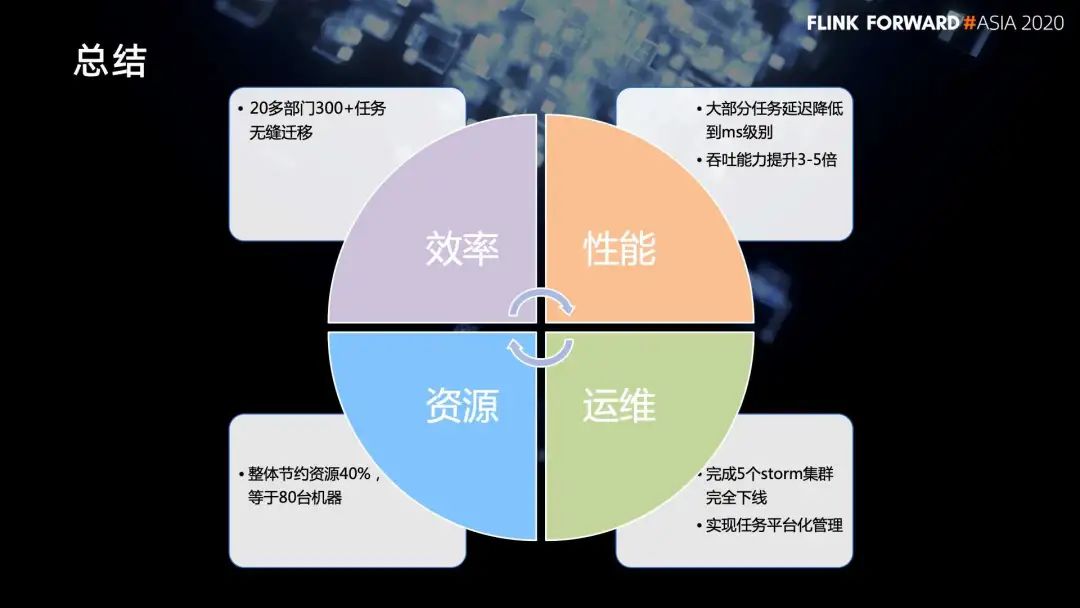
三、Storm 迁移 Flink 实践
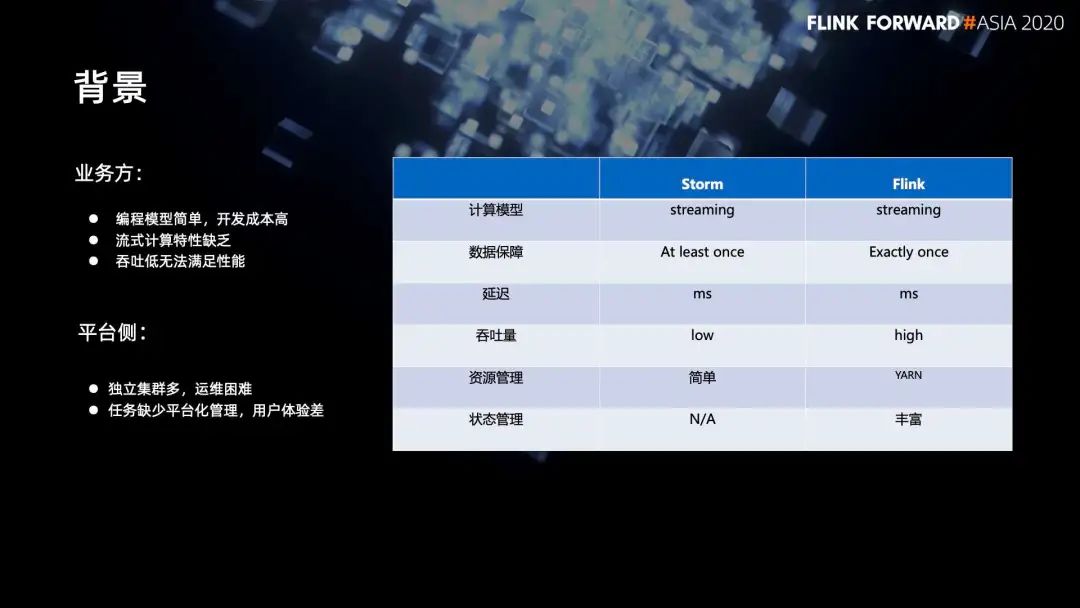
1. Flink 与 Storm 对比
在数据保障上,Flink 支持 Exactly once 语义,在吞吐量、资源管理、状态管理,用户越来越多的基于 Flink 进行开发;
而 Storm 对用户来说,编程模型简单,开发成本高,流式计算特性缺乏,吞吐低无法满足性能。在平台侧,独立集群多、运维困难、任务缺少平台化管理、用户体验差。
2. Flink-Storm 工具
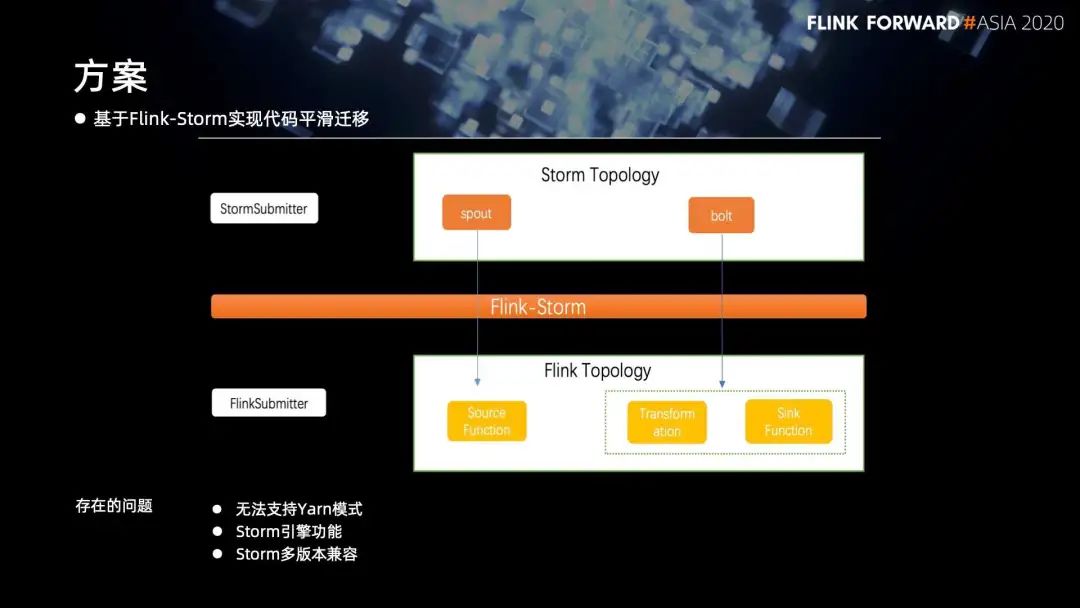
3. 对 Flink-Storm 的改进
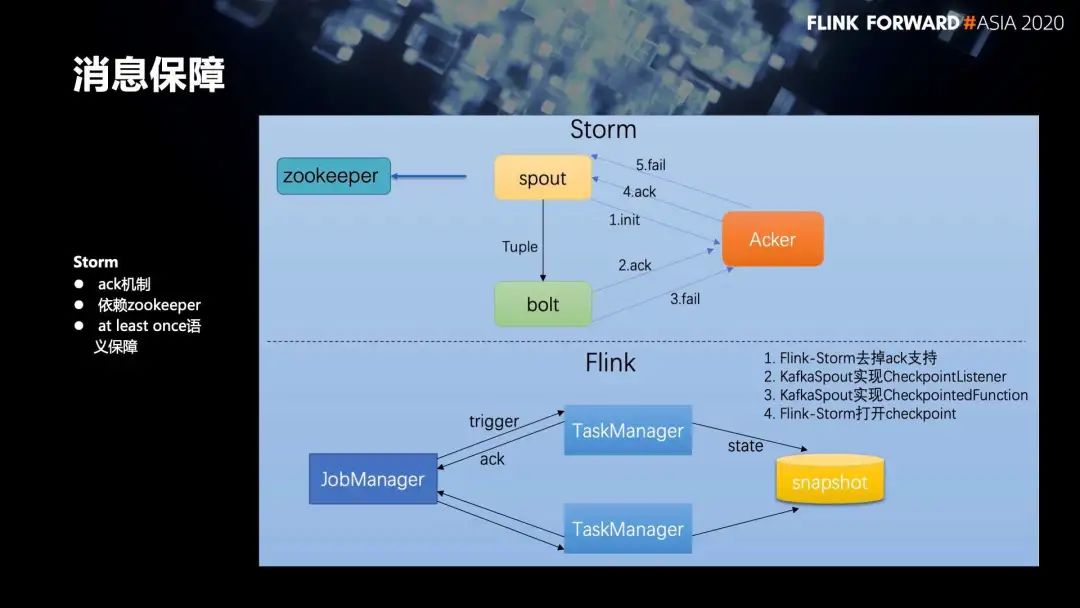
■ 3.1 消息保障
第一,ack 机制;
第二,依赖 zookeeper;
第三,at least once 语义保障。
第一,Flink-Storm 去掉 ack 支持;
第二,KafkaSpout 实现 CheckpointListener;
第三,KafkaSpout 实现 CheckpointedFunction;
第四,Flink-Storm 打开 checkpoint。
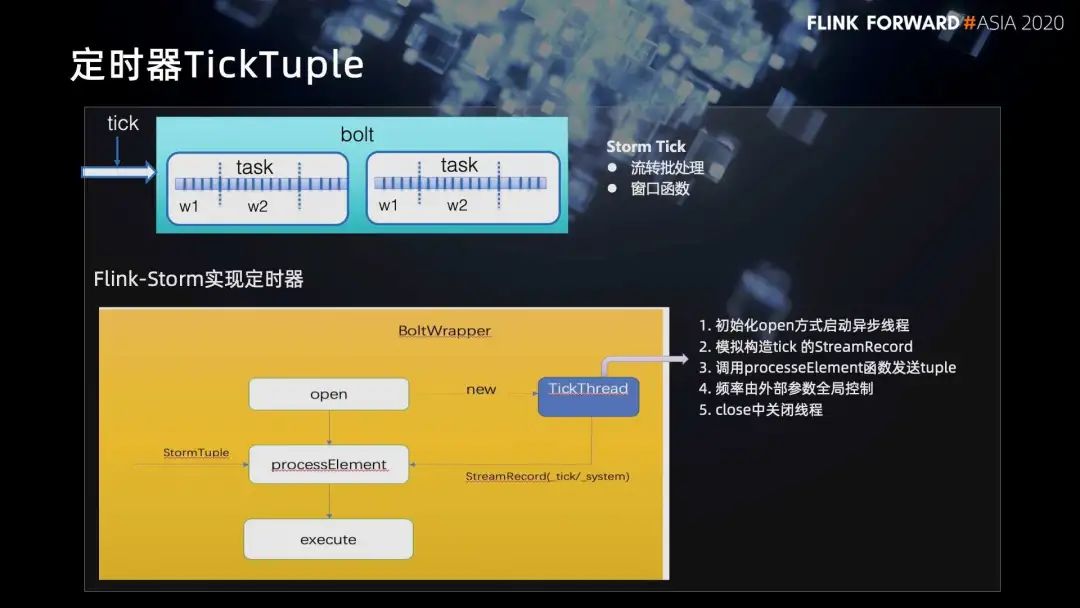
■ 3.2 对 Storm 定时器的支持
初始化 open 方式启动异步线程;
模拟构造 tick 的 StreamRecord;
调用 processeElement 函数发送 tuple;
频率由外部参数全局控制;
close 中关闭线程。
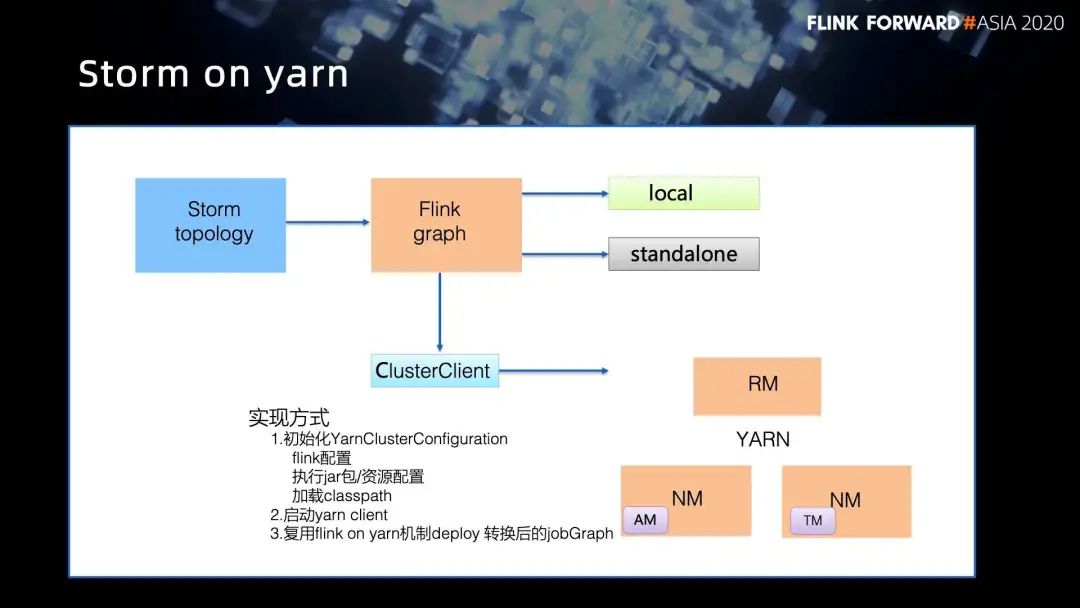
■ 3.3 Storm on Yarn
初始化 YarnClusterConfiguration Flink 配置 执行 jar 包 / 资源配置 加载 classpath;
启动 yarn client;
复用 Flink on yarn 机制 deploy 转换后的 jobGraph。
4. 任务迁移
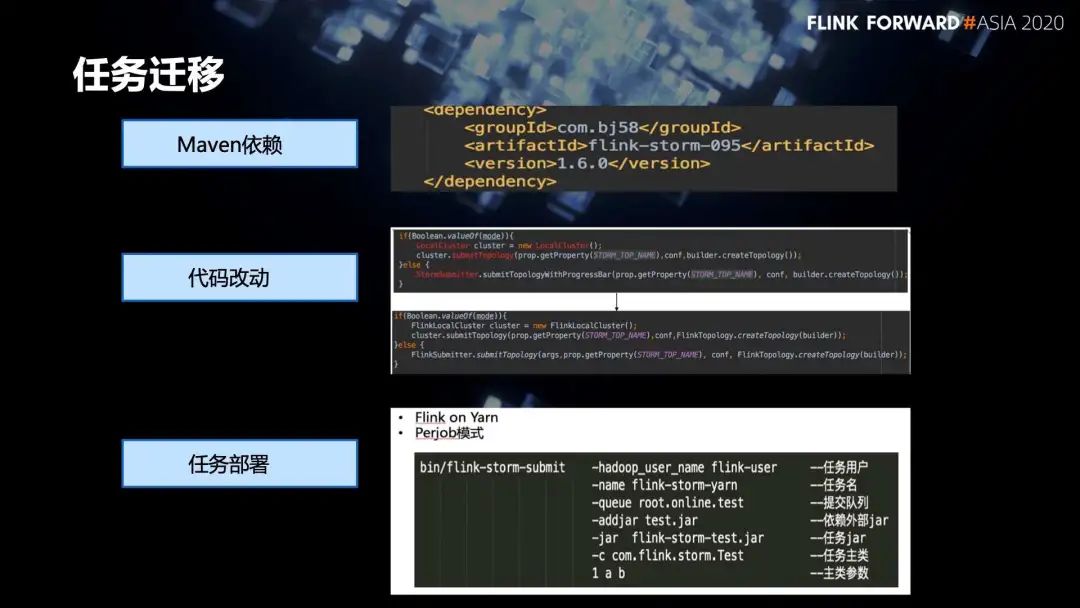
四、一站式实时计算平台
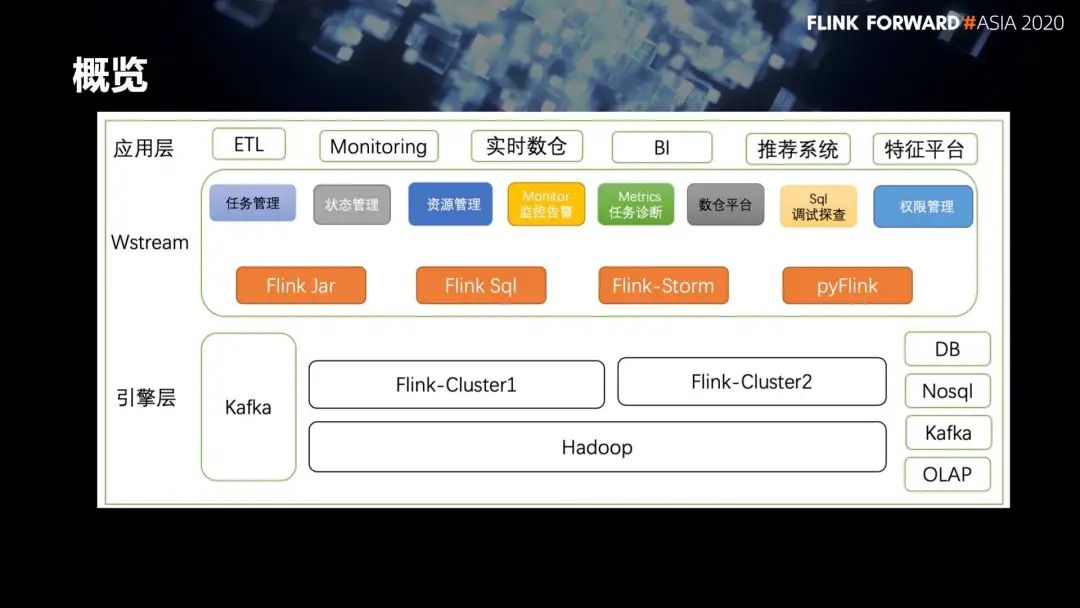
1. Wstream 平台
在任务接入方式上,支持 Flink Jar,Flink SQL,Flink-Storm,PyFlink 这 4 种方式,来满足多元化的用户需求;
在产品功能上,主要支持了任务管理、任务的创建、启动删除等;
另外,为了更好的让用户管理自己的任务和对任务进行问题定位,我们也提供了一个监控告警和任务诊断的系统;
针对数仓,提供了一些数仓平台化的功能,包括权限管理、血缘关系等等;
针对 Flink SQL 也提供了调试探查的功能。
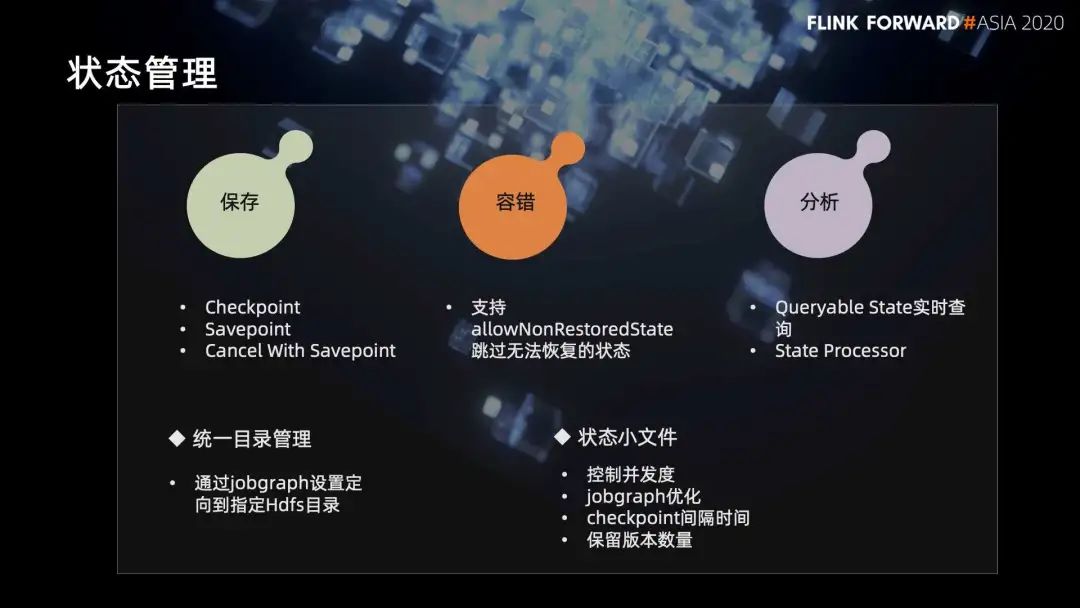
2. 状态管理
在任务保存方面,支持 Checkpoint,Savepoint,Cancel With Savepoint。
在容错方面,支持 allowNonRestoredState,跳过无法恢复的状态。
在分析方面,支持 Queryable State 实时查询,基于离线的 State Processor 的分析方式,我们会帮用户把这个状态下载进行分析。
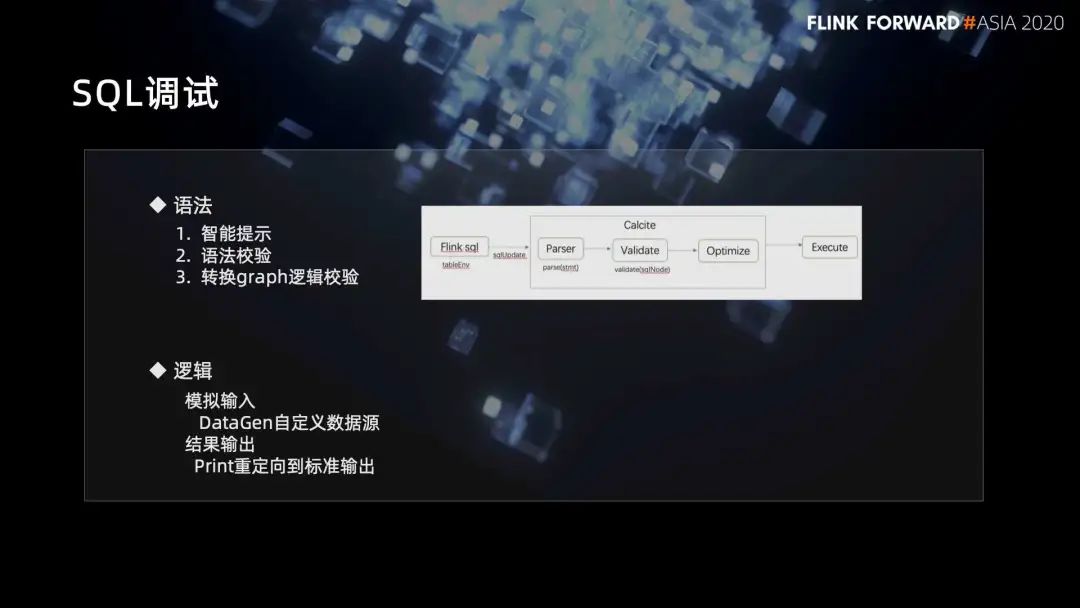
3. SQL 调试
第一,语法层面的功能包括:
智能提示;
语法校验;
转换 graph 逻辑校验。
第二,逻辑层面的功能包括:
模拟输入,DataGen 自定义数据源;
结果输出,Print 重定向到标准输出。
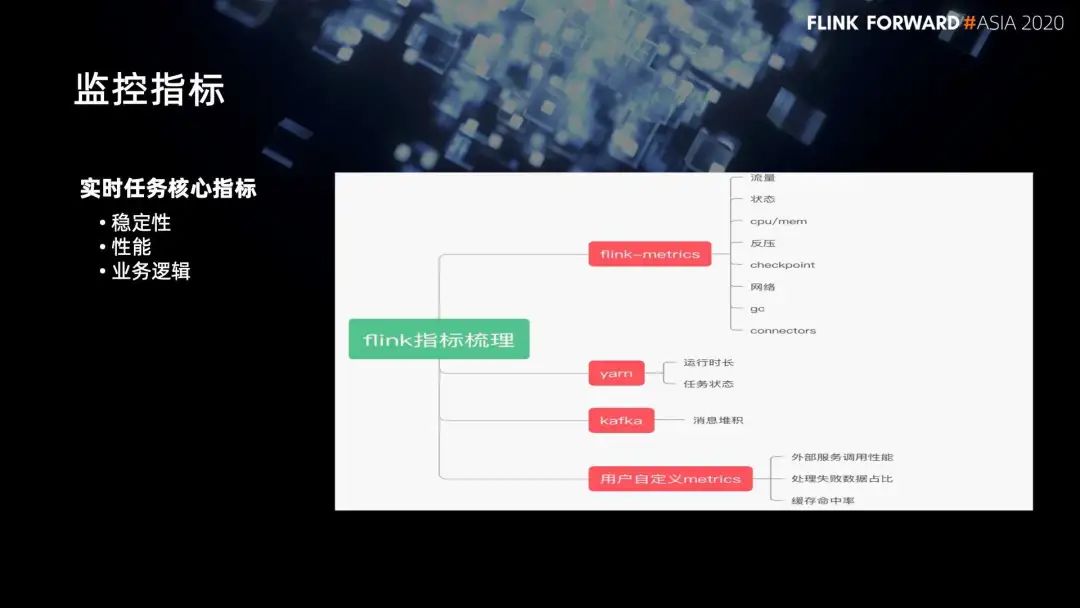
4. 任务监控
第一个是 Flink 自带的 Flink-metrics,提供大量的信息,比如流量信息、状态信息、反压、检查点、CPU、网络等等;
第二个是 yarn 层面,提供运行时长、任务状态;
第三,从 kafka 层面提供消息堆积;
最后,通过用户自定义的一些 metrics,我们可以了解业务逻辑是否符合预期。
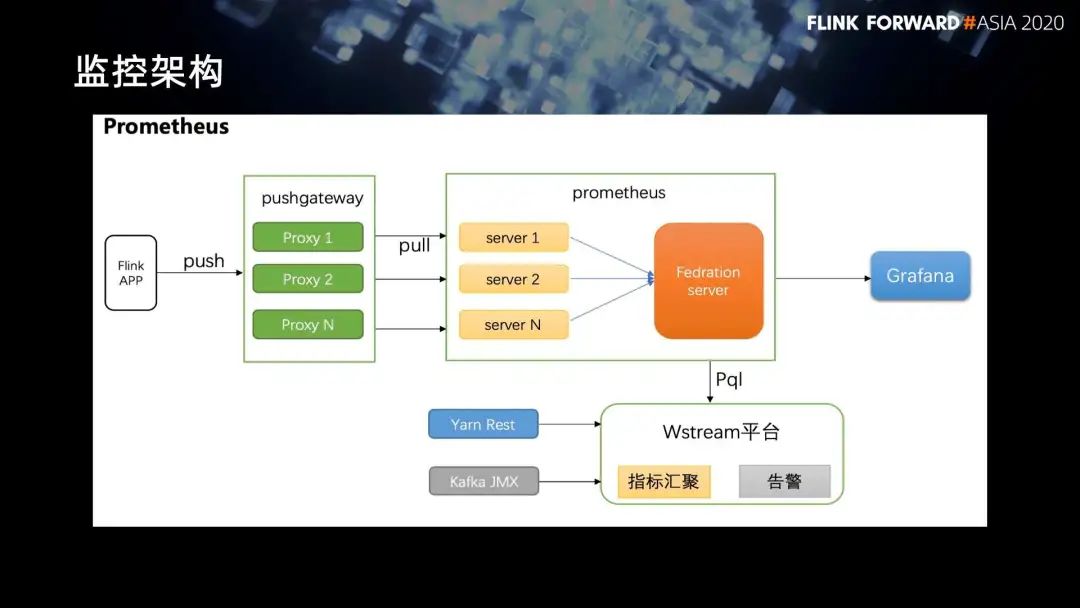
5. 监控体系
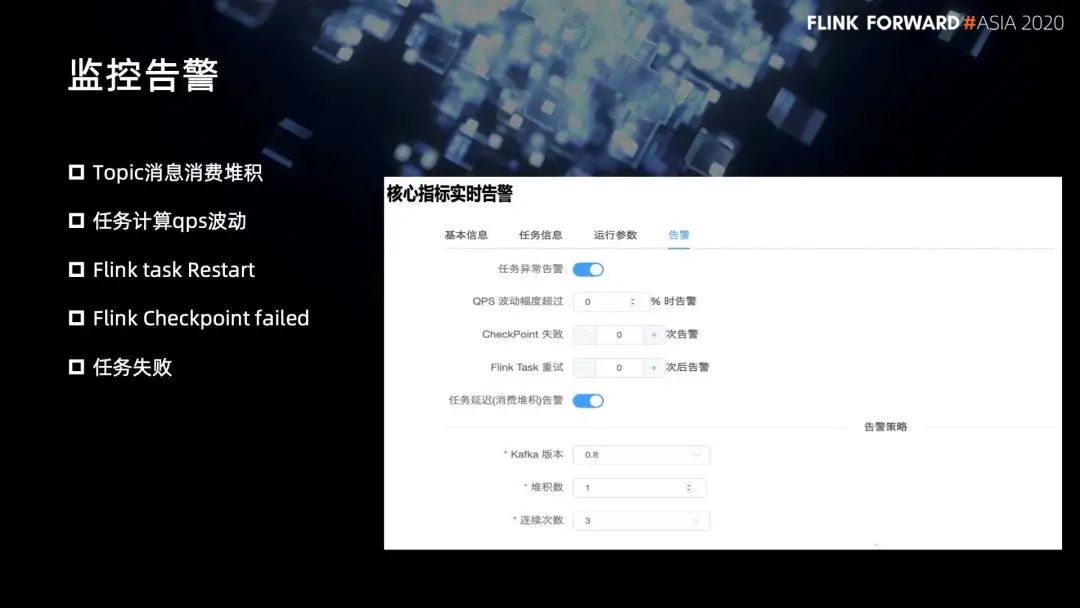
6. 监控告警
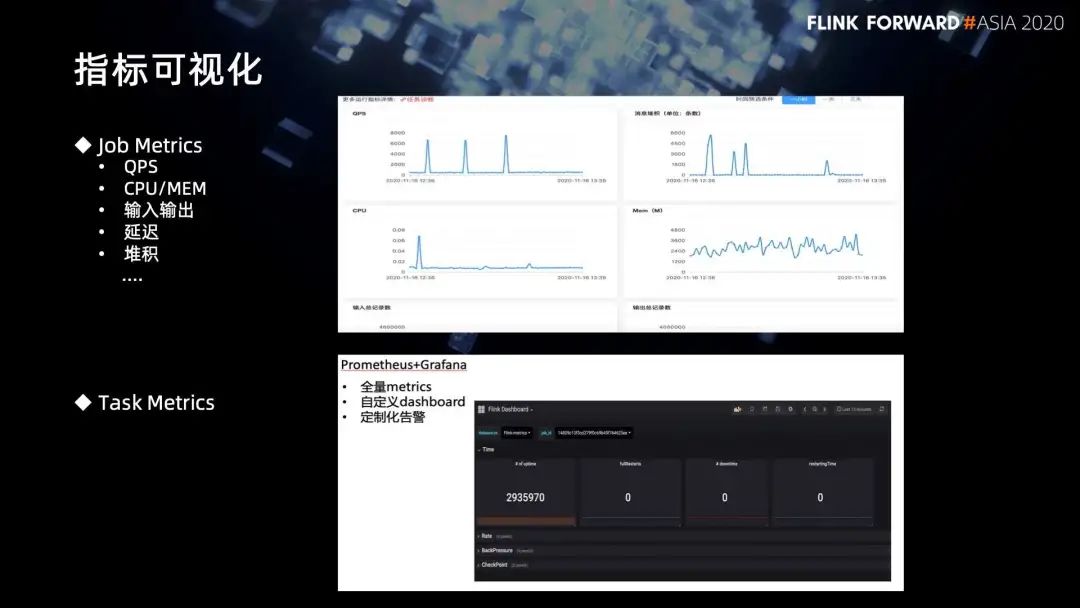
7. 指标可视化
第一个层面是 Job 层面,这一块主要是把一些比较核心的指标汇聚到我们的实时计算平台。比如说,qps 信息、输入输出的信息、延迟的信息等等;
对于更底层的 task 级别的 metrics,通过 Grafana 可以了解具体的一些task信息,比如流量信息、反压信息等。
五、后续规划
我们的后续规划,主要包括 4 个方面:
第一个是社区比较流行的批流合一。因为我们当前这个实时架构大部分还是基于 Lambda 架构,这种架构会带来很大的维护工作量,所以我们也希望借助批流合一的能力来简化架构;
第二个是资源调优,因为作为流式计算来说,缺少一些动态资源管理的机制,因此我们也希望有手段来进行这样一些调优;
第三个是智能监控,我们当前的监控和告警是事后的,希望有某种方式在任务出现问题之前进行预警;
最后是拥抱社区的新能力,包括对新场景的探索。
