
盘点一个ddddocr实现登录的实战案例
回复“资源”即可获赠Python学习资料
大家好,我是皮皮。
一、前言
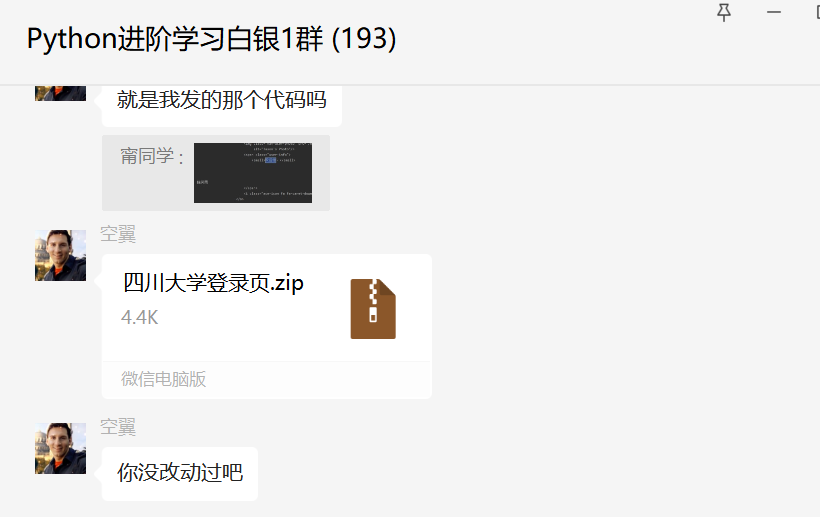
前几天在Python白银交流群【空翼】问了一个Pyhton网络爬虫的问题,这里拿出来给大家分享下。
二、实现过程
一开始看上去并不能登录,找不到原因在哪,后来【甯同学】帮忙搞定了,代码如下:
# -*- coding: utf-8 -*-
# @Author : KongYi
# @Time : 2022/12/3 13:49
import hashlib
import re
import requests
import ddddocr
baseurl = 'http://zhjw.scu.edu.cn/login'
session = requests.Session()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',
}
res = session.get(url=baseurl, headers=headers)
token = re.findall('<input type="hidden" id="tokenValue" name="tokenValue" value="(.*?)">', res.text)[0]
print(token)
res = session.get('http://zhjw.scu.edu.cn/img/captcha.jpg')
with open('captcha.jpg', 'wb') as f:
f.write(res.content)
f.close()
ocr = ddddocr.DdddOcr()
with open('captcha.jpg', 'rb') as f:
img_bytes = f.read()
captcha_text = ocr.classification(img_bytes)
print(captcha_text)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
m = hashlib.md5()
m.update('Chenxiao12345!'.encode())
ctx = m.hexdigest()
print(ctx)
login_url = 'http://zhjw.scu.edu.cn/j_spring_security_check'
data = {
'tokenValue': token,
'j_username': '2020141410129',
'j_password': ctx,
'j_captcha': captcha_text
}
res = session.post(url=login_url, data=data, headers=headers)
jsonurl = 'http://zhjw.scu.edu.cn/'
res = session.post(url=jsonurl, headers=headers)
print(res.text)
代码运行之后,顺利地实现了网页登录。
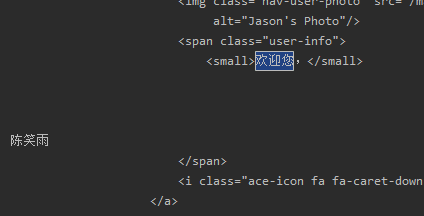
顺利地解决了问题。
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Pyhton网络爬虫的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【空翼】提问,感谢【甯同学】给出的思路和代码解析,感谢【Python狗】等人参与学习交流。
大家在学习过程中如果有遇到问题,欢迎随时联系我解决(我的微信:pdcfighting),应粉丝要求,我创建了一些高质量的Python付费学习交流群和付费接单群,欢迎大家加入我的Python学习交流群和接单群!

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~
评论