
我的 Spark 3.1.1 之旅【收藏夹吃灰系列】
点击蓝色“有关SQL”关注我哟
加个“星标”,天天与10000人一起快乐成长

图 | 榖依米
大数据三部曲终于完成了:
本篇是最后一部,《我的 Spark 3.1.1 之旅》。
如今使用 CDH( Cloudera Distribution Hadoop) 部署 Hadoop 成了业界常规,为什么还要费劲自己动手呢?这不浪费时间嘛!
是的。时间投入蛮大的,不算写文章,搭建过程也得有 20多个小时。白天忙公司项目,都已经焦头烂额,回到家,还得花上 2-3 小时,熬到深夜。
搭建过程,难熬的是,遇到卡点,找不到解决方法。抓狂,质疑,怀疑人生,不停对自己说放弃,但最后一刻,总能在一杯杯热咖啡的陪伴下,找到破解。
一切技术难点,都是纸糊的。我们要做的,只有埋头苦干,与等待!
浪费时间,给自己找罪受?No, 这正是我享受的地方!
初学数据库时,我把 Oracle 反复装了 50 多遍。Solaris, Redhat, CentOS,能找到的操作系统,我都装了。哪个 Linux 容易装,网络不稳定会出什么问题,磁盘不够用会有什么症状,RAC 该如何配置,等等,都经历了一遍。之后看到问题,心里才没有初学时那种慌张。
搭建大数据环境也一样。CDH/Hortonworks/MapR, 这些厂商都给封装完了,纯 UI 式安装管理,开发用得挺爽。但某天爆出一个 Hive Authentication exception, 如果不知道有 hive-site.xml 这回事,不知道 hive.server2.authentication, 处理起来,两眼一抹黑,只能傻傻等待重启了!
所以,我还是会选择,多自己动手,从 0 到 1 玩一样东西。虽然少看了很多蓝光高清电影,但这个过程是值得的!

以下是这次分享的主题:
巧妇也做有米之炊: 准备安装文件 买锅造炉:集群搭建 生米煮成熟饭之后:集群启动与关闭 真香系列:Spark Shell 独食记
A
准备安装文件
Spark 是一个分布式计算框架,通过集群部署,可以发挥并发计算的优势。
其与 Hadoop, Hive 天然集成的策略,让计算更贴近本地数据,完成快速计算,提高效率。
所以在本次实验中,我把 Spark 部署到了 Hadoop 集群中,发挥最大的优势。当然,实际运用中,完成可以有不同的部署方法。
既然是与 hadoop 结合起来运用,那么选择 Spark 版本就很重要了。
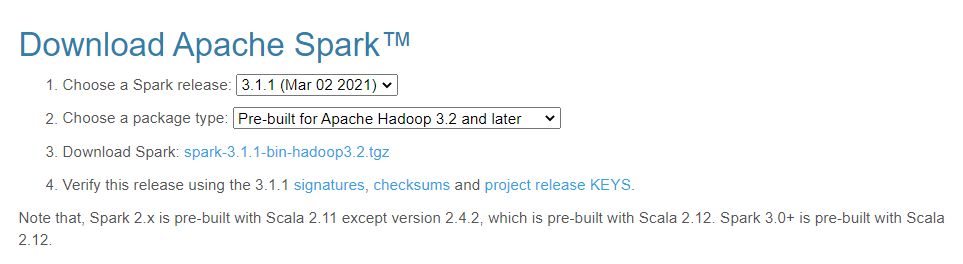
Spark 官网:https://spark.apache.org/downloads.html
对应的,Scala 版本也应该选择 Scala 2.12. Scala 是 Spark 预编译语言,用来开发 Spark 应用最自然。
总结下,完成此次部署,需要的软件有:
Spark 3.1.1 Scala 2.12
Scala 下载官网:https://www.scala-lang.org/download/
A
集群搭建
搭建 Spark ,首要的事情,是规划好 master 节点与 worker 节点。与前面的两部曲相结合,本次实验共有 3 台计算机,对应的 host 与 IP 如下:
namenode 192.168.31.10
nodea 192.168.31.11
nodeb 192.168.31.12
namenode 上运行了 HDFS 的 namenode, YARN 的 ResourceManager,还有本次的 Spark Master.
nodea 和 nodeb 上运行了 HDFS 的 datanode, YARN 的 NodeManager,还有 Spark Worker.
接下来配置每台计算机的环境变量,以及 Spark 集群参数.
环境变量
环境变量,提供了快捷访问可执行文件的路径。
本次实验主要配置 Spark Home 与 Scala Home.
SPARK_HOME=/opt/Spark/Spark3.1.1
SCALA_HOME=/opt/Scala/Scala2.12
export SPARK_HOME
export SCALA_HOME
PATH=$PATH:$PARK_HOME/bin:$SCALA_HOME/bin
export PATH
除了要建立相应的文件目录,目录访问权限需要单独配置。为了实验方便,设置这两目录为 HadoopAdmin 所有,并且给目录加上 777 的权限。
chown -R hadoopadmin /opt/Spark
chown -R hadoopadmin /opt/Scala
chmod a+rwx /opt/Spark
chmod a+rwx /opt/Scala
但事实证明,Scala 的 RPM 包,不能指定目录安装,而只能随遇而安:
[hadoopadmin@namenode Scala]$ rpm -qpi scala-2.12.13.rpm
Name : scala
Version : 2.12.13
Release : 1
Architecture: noarch
Install Date: (not installed)
Group : Development/Languages
Size : 634532234
License : BSD
Signature : (none)
Source RPM : scala-2.12.13-1.src.rpm
Build Date : Tue 12 Jan 2021 10:16:51 AM EST
Build Host : travis-job-efec1d00-ea82-450c-8151-6fc45a7e286d
Relocations : (not relocatable)
Vendor : lightbend
URL : http://github.com/scala/scala
Summary : Scala Programming Language Distribution
Description :
Have the best of both worlds. Construct elegant class hierarchies for maximum code reuse and extensibility, implement their behavior using higher-order functions. Or anything in-between.
通过 rpm -qpi 查询得知,scala 的 relocations 属性为 not relocatable, 即,无法指定安装路径。
但安装之后,通过
whereis scala
可以找到 scala 的安装目录。
[hadoopadmin@namenode Scala]$ whereis scala
scala: /usr/bin/scala /usr/share/scala /usr/share/man/man1/scala.1.gz
所以,SCALA_HOME 指定 /usr/share/scala.
最终,在 .bashrc 文件中,加入这些环境变量:
SPARK_HOME=/opt/Spark/Spark3.1.1
SCALA_HOME=/usr/share/scala
PATH=$PATH:$SPARK_HOME/bin:$SCALA_HOME/bin
集群参数配置
为了可以和 Hive 做交互,把 Hive-site.xml 复制到 $SPARK_HOME/conf 下面。 配置 spark-env.sh. 在 $SPARK_HOME/conf 下可能没有 spark-env.sh 文件,需要将 spark-env.sh.template 复制一份成 spark-env.sh:
--spark-env.sh
JAVA_HOME=/opt/java/jdk8
HADOOP_HOME=/opt/Hadoop/hadoop-3.2.2
HADOOP_CONF_DIR=/opt/Hadoop/hadoop-3.2.2/etc/hadoop
YARN_CONF_DIR=/opt/Hadoop/hadoop-3.2.2/etc/hadoop
SPARK_CONF_DIR=/opt/Spark/Spark3.1.1/conf
SPARK_MASTER_HOST=namenode
将 nodea/nodeb 加入到 $SPARK_HOME/workers 文件中。
-- workers
nodea
nodeb
通过 scp 把 /opt/Spark 复制到 nodea 和 nodeb 上
scp -rv $SPARK_HOME hadoopadmin@nodea:$SPARK_HOME
scp -rv $SPARK_HOME hadoopadmin@nodeb:$SPARK_HOME
A
Spark 集群启动与关闭
启动
Spark 集群的启动,有两种方式。一种是可以把 Master 与 worker 分开来处理。即,先启动 master 节点,worker 节点之后一台一台手工启动;第二种是,用一个启动文件,将 master 和 worker 同时启动。
本次实验,选择第二种方法:
$SPARK_HOME/sbin/start-all.sh
因为 spark 与 hadoop 装在了同一台机器上,而 hadoop 的简易启动命令文件也是 start-all.sh , 所以这里指定了下全目录文件名。
关闭
同上,stop-all.sh 和 hadoop 的关闭脚本同名,指定下全目录文件名:
$SPARK_HOME/sbin/stop-all.sh
监控页
可通过本地8080端口,访问 Spark 集群的监控页。
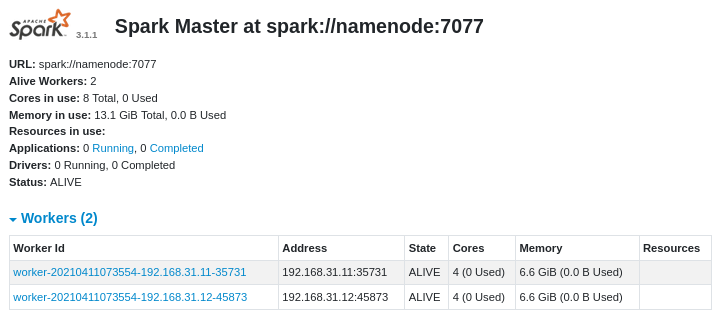
A
Spark Shell 应用
最简单的使用 Spark 集群的方式,就是利用集成的 spark-shell 脚本
[hadoopadmin@namenode bin]$ spark-shell
2021-04-11 07:56:21,588 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://namenode:4040
Spark context available as 'sc' (master = local[*], app id = local-1618142189348).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.1
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_281)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
现在做一个例子,把 frank_lin.txt 这个原本在 HDFS 上的文本文件,复制到 HDFS 的 /user/hadoopadmin 目录下(如果没有 hadoopadmin 目录就建一个)
hdfs dfs -cp /user/hadoop/wordcounter/input/franklin.txt /user/hadoopadmin/
接着用 spark 来统计,改文件共有多少行:
scala> val textfile_franklin=spark.read.textFile("franklin.txt")
textfile_franklin: org.apache.spark.sql.Dataset[String] = [value: string]
scala> textfile_franklin.count()
res1: Long = 2773
注意,这里的 spark 默认用户路径是 HDFS 上的 /user/hadoopadmin.
scala> val textfile = spark.read.textFile("README.md")
org.apache.spark.sql.AnalysisException: Path does not exist: hdfs://namenode:9000/user/hadoopadmin/README.md
通过访问 namenode:4040 可看到应用的执行情况
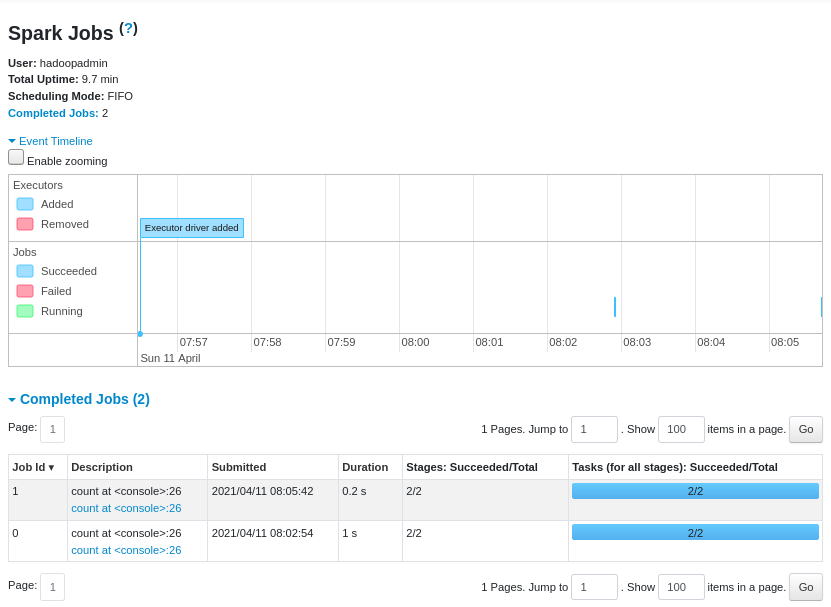
A
小结
往期精彩: